Con el advenimiento de los grandes datos, las personas comienzan a obtener datos de Internet para el análisis de datos con la ayuda de rastreadores web. Hay varias formas de hacer su propio rastreador: extensiones en los navegadores, codificación de python con Beautiful Soup o Scrapy, y también herramientas de extracción de datos como Octoparse.
Sin embargo, siempre hay una guerra de codificación entre las arañas y los anti-bots. Los desarrolladores web aplican diferentes tipos de técnicas anti-scraping para evitar que sus sitios web sean raspados. En este artículo, he enumerado las cinco técnicas anti-scraping más comunes y cómo se pueden evitar.
1.IP
Una de las formas más fáciles para que un sitio web detecte actividades de web scraping es a través del seguimiento de IP. El sitio web podría identificar si la IP es un robot en función de sus comportamientos. Cuando un sitio web descubre que se ha enviado una cantidad abrumadora de solicitudes desde una sola dirección IP periódicamente o en un corto período de tiempo, existe una buena posibilidad de que la IP se bloquee porque se sospecha que es un bot. En este caso, lo que realmente importa para construir un crawler anti-scraping es el número y la frecuencia de visitas por unidad de tiempo. Aquí hay algunos escenarios que puede encontrar.
Escenario 1
Hacer múltiples visitas en segundos. No hay forma de que un humano real pueda navegar tan rápido. Entonces, si su crawler envía solicitudes frecuentes a un sitio web, el sitio web definitivamente bloquearía la IP para identificarlo como un robot.
Solución: Disminuya la velocidad de scraping. Configurar un tiempo de retraso (por ejemplo, la función “dormir”) antes de ejecutar o aumentar el tiempo de espera entre dos pasos siempre funcionaría.
Escenario 2
Visitar un sitio web exactamente al mismo ritmo. El humano real no repite los mismos patrones de comportamiento una y otra vez. Algunos sitios web monitorean la frecuencia de las solicitudes y si las solicitudes se envían periódicamente con el mismo patrón exacto, como una vez por segundo, es muy probable que se active el mecanismo anti-scraping.
Solución: Establezca un tiempo de retraso aleatorio para cada paso de su rastreador. Con una velocidad de scrapubg aleatoria, el rastreador se comportaría más como los humanos navegan por un sitio web.
Escenario 3
Algunas técnicas anti-scraping de alto nivel incorporarían algoritmos complejos para rastrear las solicitudes de diferentes IP y analizar sus solicitudes promedio. Si la solicitud de una IP es inusual, como enviar la misma cantidad de solicitudes o visitar el mismo sitio web a la misma hora todos los días, se bloquearía.
Solución: Cambie su IP periódicamente. La mayoría de los servicios VPN, cloud servers y servicios proxy podrían proporcionar IP rotadas. Al través una solicitud Rotación de IP, el rastreador no se comporta como un bot, lo que reduce el riesgo de ser bloqueado.
2.Captcha
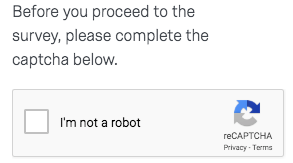
¿Alguna vez has visto este tipo de imagen al navegar por un sitio web?
1.Necesita un clic
2.Necesita seleccionar imágenes específicas
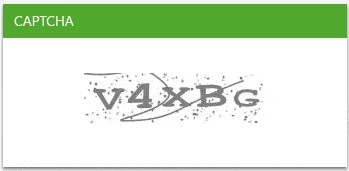
Estas imágenes se llaman Captcha. Captcha significa prueba de Turing pública completamente automatizada para diferenciar a computadoras y seres humanos. Es un programa público automático para determinar si el usuario es un humano o un robot. Este programa proporcionaría varios desafíos, como imagen degradada, rellenar espacios en blanco o incluso ecuaciones, que se dice que son resueltas solo por un humano.
Esta prueba ha evolucionado durante mucho tiempo y actualmente muchos sitios web aplican Captcha como técnicas anti-scraping. Alguna vez fue muy difícil pasar Captcha directamente. Pero hoy en día, muchas herramientas de código abierto ahora se pueden aplicar para resolver problemas de Captcha, aunque pueden requerir habilidades de programación más avanzadas. Algunas personas incluso crean sus propias bibliotecas de características y crean técnicas de reconocimiento de imágenes con aprendizaje automático o habilidades de aprendizaje profundo para pasar esta verificación.
Es más fácil no activarlo que resolverlo
Para la mayoría de las personas, la forma más fácil es ralentizar o aleatorizar el proceso de extracción para no activar la prueba Captcha. Ajustar el tiempo de retraso o usar IP rotados puede reducir efectivamente la probabilidad de activar la prueba.
3.Iniciar Sesión
Muchos sitios web, especialmente las plataformas de redes sociales como Twitter y Facebook, solo le muestran información después de iniciar sesión en el sitio web. Para rastrear sitios como estos, los rastreadores también necesitarían simular los pasos de registro.
Después de iniciar sesión en el sitio web, el rastreador debe guardar las cookies. Una cookie es un pequeño dato que almacena los datos de navegación para los usuarios. Sin las cookies, el sitio web olvidaría que ya ha iniciado sesión y le pedirá que vuelva a iniciar sesión.
Además, algunos sitios web con mecanismos de raspado estrictos solo pueden permitir el acceso parcial a los datos, como 1000 líneas de datos todos los días, incluso después de iniciar sesión.
Tu bot necesita saber cómo iniciar sesión
1) Simular operaciones de teclado y mouse. El rastreador debe simular el proceso de inicio de sesión, que incluye pasos como hacer clic en el cuadro de texto y los botones “iniciar sesión” con el mouse, o escribir información de cuenta y contraseña con el teclado.
2) Inicie sesión primero y luego guarde las cookies. Para los sitios web que permiten cookies, recordarían a los usuarios guardando sus cookies. Con estas cookies, no es necesario volver a iniciar sesión en el sitio web a corto plazo. Gracias a este mecanismo, su rastreador podría evitar tediosos pasos de inicio de sesión y raspar la información que necesita.
3) Si, desafortunadamente, encuentra los mecanismos de escalado estrictos anteriores, puede programar su rastreador para monitorear el sitio web a una frecuencia fija, como una vez al día. Programe el rastreador para que raspe las 1000 líneas de datos más recientes en períodos y acumule los datos más nuevos.
4.UA
UA significa User-Agent, que es un encabezado del sitio web para identificar cómo visita el usuario. Contiene información como el sistema operativo y su versión, tipo de CPU, navegador y su versión, idioma del navegador, un complemento del navegador, etc.
Un ejemplo de UA: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, como Gecko) Chrome/17.0.963.56 Safari/535.11
Al scrape un sitio web, si su rastreador no contiene encabezados, solo se identificaría como un script (por ejemplo, si usa python para construir el rastreador, se declararía como un script de python). Los sitios web definitivamente bloquearían la solicitud de un script. En este caso, el buscador debe pretender ser un navegador con un encabezado UA para que el sitio web pueda proporcionarle acceso.
A veces, el sitio web muestra diferentes páginas o información a diferentes navegadores o diferentes versiones, incluso si ingresa al sitio con la misma URL. Lo más probable es que la información sea compatible con un navegador mientras que otros navegadores están bloqueados. Por lo tanto, para asegurarse de que puede ingresar a la página correcta, se requerirán múltiples navegadores y versiones.
Cambia entre diferentes UA para evitar ser bloqueado
Cambia la información de UA hasta que encuentre la correcta. Algunos sitios web sensibles que aplican técnicas complejas de anti-scraping pueden incluso bloquear el acceso si se usa el mismo UA durante mucho tiempo. En este caso, necesitaría cambiar la información de UA periódicamente.
5.AJAX
Hoy en día, se desarrollan más sitios web con AJAX en lugar de las técnicas tradicionales de desarrollo web. AJAX significa JavaScript asíncrono y XML, que es una técnica para actualizar el sitio web de forma asíncrona. En pocas palabras, no es necesario volver a cargar todo el sitio web cuando solo se producen pequeños cambios dentro de la página.
Entonces, ¿cómo podría saber si un sitio web aplica AJAX?
Un sitio web sin AJAX: Toda la página se actualizará incluso si solo realiza un pequeño cambio en el sitio web. Por lo general, aparece un signo de carga y la URL cambia. Para estos sitios web, podríamos aprovechar el mecanismo e intentar encontrar el patrón de cómo cambiarían las URL. Luego, podría generar URL en lotes y extraer información directamente a través de estas URL en lugar de enseñarle a su crawler cómo navegar por sitios web como los humanos.
Un sitio web con AJAX: Solo se cambiará el lugar donde hace clic y no aparecerá ningún signo de carga. Por lo general, la web URL no cambiaría, por lo que el crawler tiene que lidiar con ella de una manera directa.
Para algunos sitios web complejos desarrollados por AJAX, se necesitarían técnicas especiales para descubrir formas cifradas únicas en esos sitios web y extraer los datos cifrados. Resolver este problema puede llevar mucho tiempo porque las formas cifradas varían en las diferentes páginas. Si pudiera encontrar un navegador con operaciones JS incorporadas, podría descifrar automáticamente el sitio web y extraer datos.
Las técnicas de web scraping y anti-scraping están progresando todos los días. Quizás estas técnicas estarían desactualizadas cuando lea este artículo. Sin embargo, siempre puede obtener ayuda de Octoparse. Aquí en Octoparse, nuestra misión es hacer que los datos sean accesibles para cualquier persona, en particular, aquellos sin antecedentes técnicos. Como herramienta de web scraping, podemos proporcionarle soluciones listas para implementar para estas cinco técnicas anti scraping. ¡No dude en contactarnos cuando necesite una poderosa herramienta de web scraping para su negocio o proyecto!
Referencia:
Megan Mary Jane. 2019. Cómo evitar las técnicas anti-scraping en el web scraping. Recuperado de: https://bigdata-madesimple.com/how-to-bypass-anti-scraping-techniques-in-web-scraping/



