Si quiero construir un web crawler como novato y extraer con éxito 20k datos del sitio web de Amazon Career, ¿cómo puedo configurar un crawler y crear una base de datos que eventualmente se convierta en mi activo sin costo? Vamos a sumergirnos en eso.
Antes de aprender a crear un crawler, es importante entender primero qué es un crawler web y en qué condiciones se encuentra.
¿Qué es Crawler Web y Qué Diferencia hay con el Web Scraper?
El web crawler, también se conoce por la palabra “web crawling” o un “bot de motor de búsqueda”, descarga e indexa contenido de todo Internet. El objetivo de un web crawler es aprender de qué tratan (casi) todas las páginas web en la web, de modo que la información se pueda recuperar cuando sea necesario. Se denominan “web crawler” porque rastreo es el término técnico para acceder automáticamente a un sitio web y obtener datos a través de un programa de software.
Estos bots casi siempre son operados por motores de búsqueda. Al aplicar un algoritmo de búsqueda a los datos recopilados por los web crawlers, los motores de búsqueda pueden proporcionar enlaces relevantes en respuesta a las consultas de búsqueda de los usuarios, generando la lista de páginas web que aparecen después de que un usuario escribe una búsqueda en Google o Bing (u otro motor de búsqueda).
Un web crawler es como alguien que revisa todos los libros en una biblioteca desorganizada e integra un catálogo de tarjetas para que cualquiera que visite la biblioteca pueda encontrar rápida y fácilmente la información que necesita. Para ayudar a clasificar y ordenar los libros de la biblioteca por tema, el organizador leerá el título, el resumen y parte del texto interno de cada libro para averiguar de qué se trata.
¿Qué es la diferencia entre web crawler y web scraper?
Web Crawler vs Web Scraper
En cuanto al web crawler, también hablamos del web scraper. El web scraper, raspador de datos o raspador de contenido es un bot que descarga el contenido de un sitio web, a menudo con la intención de usar ese contenido con un propósito.
El web scraping suele ser mucho más específico que el web crawling. Los web scrapers pueden estar detrás de páginas específicas o sitios web específicos, mientras que los web crawlers seguirán los enlaces y las páginas de forma continua.
Además, los robots web scraper pueden ignorar la tensión que ejercen sobre los servidores web, mientras que los web crawlers, especialmente los de los principales motores de búsqueda, obedecerán el archivo robots.txt y limitarán sus solicitudes para no sobrecargar al servidor web.
¿Por Qué Necesitamos Web Crawler, Especialmente para Empresas?
Imagina que la Búsqueda de Google no existiera. ¿Cuánto tiempo te llevaría obtener la receta de nuggets de pollo sin escribir la palabra clave? Hay 2.5 quintillones de bytes de datos creados cada día. Dicho esto, sin la Búsqueda de Google, sería casi imposible encontrar la información específica.
Google Search es un web crawler único que indexa los sitios web y encuentra la página para nosotros. Además del motor de búsqueda, puede crear un web crawler para ayudarte a lograr:
1. Agregación de contenido: Funciona para recopilar información sobre temas específicos de diversos recursos en una sola plataforma. Como tal, es necesario rastrear sitios web populares para alimentar datos o información a su plataforma a tiempo.
2. Análisis de sentimientos: También se llama minería de opinión. Como su nombre lo indica, es el proceso de analizar las actitudes públicas hacia un producto y servicio. Requiere un conjunto monotónico de datos para evaluar con precisión. Un rastreador web puede extraer tweets, reseñas y comentarios para tu análisis.
3. Generación de leads: Todo negocio necesita leads de ventas, así sobreviven y prosperan. Supongamos que planeas hacer una campaña de marketing dirigida a una industria específica. Puedes raspar el correo electrónico, el número de teléfono y los perfiles públicos de un expositor o una lista de asistentes a Ferias Comerciales, como los asistentes a la Cumbre de Reclutamiento Legal 2018.
¿Cómo Construir un Web Crawler como Principiante?
A. Scraping con Lenguaje de Programación
La programación en lenguajes de computadora es utilizada principalmente por los programadores. Aquí hay un ejemplo de un fragmento de código bot.

De Kashif Aziz
El web crawling con Python implica tres pasos principales:
1. Enviar una solicitud HTTP a la URL de la página web. Responder a tu solicitud devolviendo el contenido de las páginas web.
2. Analizar la página web. Un analizador creará una estructura de árbol del HTML a medida que las páginas web se entrelazan y se anidan juntas. Una estructura de árbol ayudará al bot a seguir los caminos que creamos y navegar para obtener la información.
3. Usando la biblioteca de Python para buscar el árbol de análisis. Entre los lenguajes de computadora para web crawling, Python es fácil de aprender en comparación con PHP y Java. Pero todavía tiene una curva de aprendizaje empinada que impide que muchos profesionales no tecnológicos la utilicen. Aunque es una solución económica para escribir la suya, pero extender el ciclo de aprendizaje en un período de tiempo limitado no es una solución a largo plazo.
Como ejemplo, utilizar python para implementar la extracción de datos para iphones en amazon (Necesita API de Amazon Clave_de_acceso, Clave_secreta Etiqueta_de_asociación):
☀️ Sin embargo, hay trucos! ¿Qué pasa si hay un método que puede obtener los mismos resultados sin escribir una sola línea de código?
B. La Herramienta de Web Scraping es Útil como una gran alternativa
Hay muchas opciones, pero yo uso Octoparse. Octoparse es un web scraper rápido y escalable. Es fácil para todos construir su propio scraper ya que solo necesitan hacer clic para obtener datos. Más de 800 plantillas de scraping prediseñadas le ayudarán a scrapear datos con solo ingresar URLs y hacer clics. Además, puede probar el modo de detección automática de datos. Lo que necesita hacer es solamente activarlo y esperar unos minutos.
Volvamos a la página web de Amazon Career como ejemplo:
Objetivo: Crear un crawler para extraer información de trabajo, incluido el título del trabajo, ID del trabajo, descripción, calificación básica, calificación preferida y URL de la página.
URL: https://www.amazon.jobs/en/search?base_query=&loc_query=
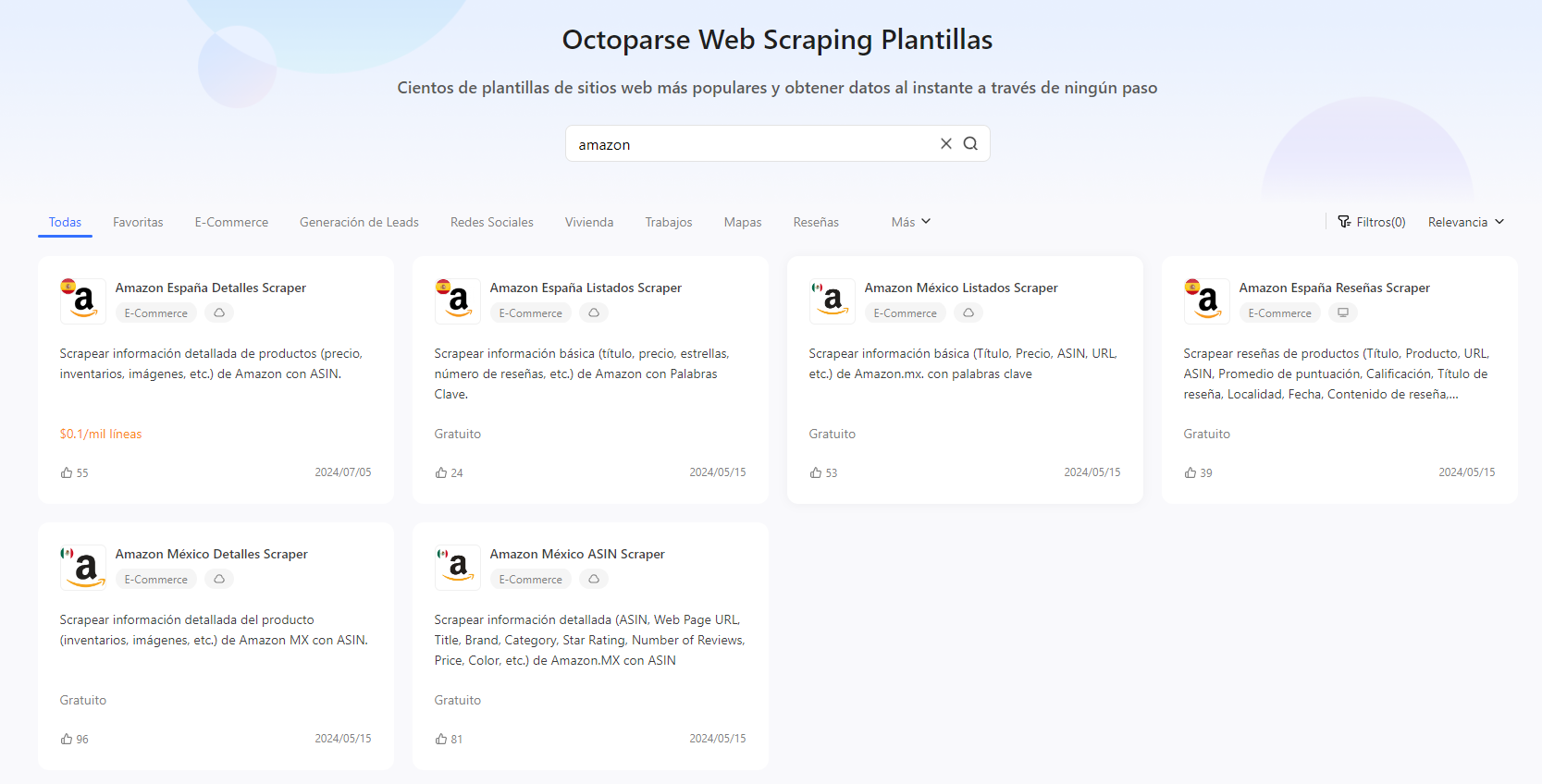
1. Abre Octoparse y buscamos “Amazon” en la barra de texto en la página de inicio. O pruebala directamente con el enlace siguiente:
https://www.octoparse.es/template/amazon-producto-detalles-scraper-asin
2. Al hacer clic en “Empezar“, verás las plantillas diseñadas para el sitio web Amazon. Puedes leer sus instrucciones y datos de muestra haciendo clic en cada una y así luego seleccionar la que más se ajuste a tus necesidades de datos y hacer clic en “Probarla“.
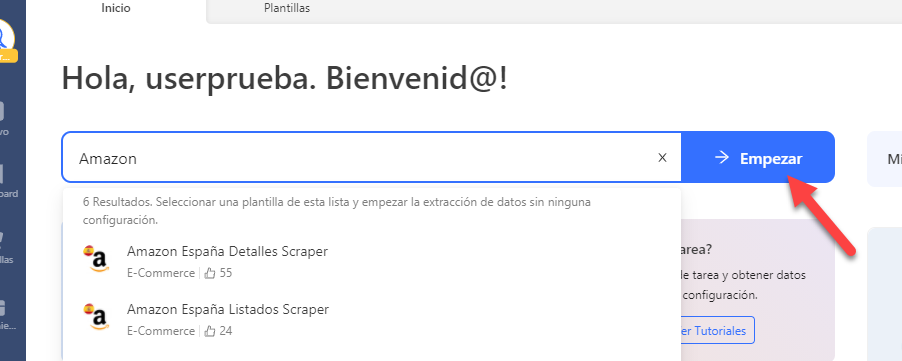
3. Siguiendo las instrucciones, puedes personalizar un web crawler (una plantilla) fácilmente. Lo tendrás que hacer suele ser que ingreses URL de destino o palabras clave, a veces número de páginas que quieres extraer también, para localizar el rango de datos y su cantidad.
4. Cuando la plantilla se haya configurado, es hora de ejecutarla. En este paso lo único que falta es esperar que todos los datos se detecten y scrapeen.
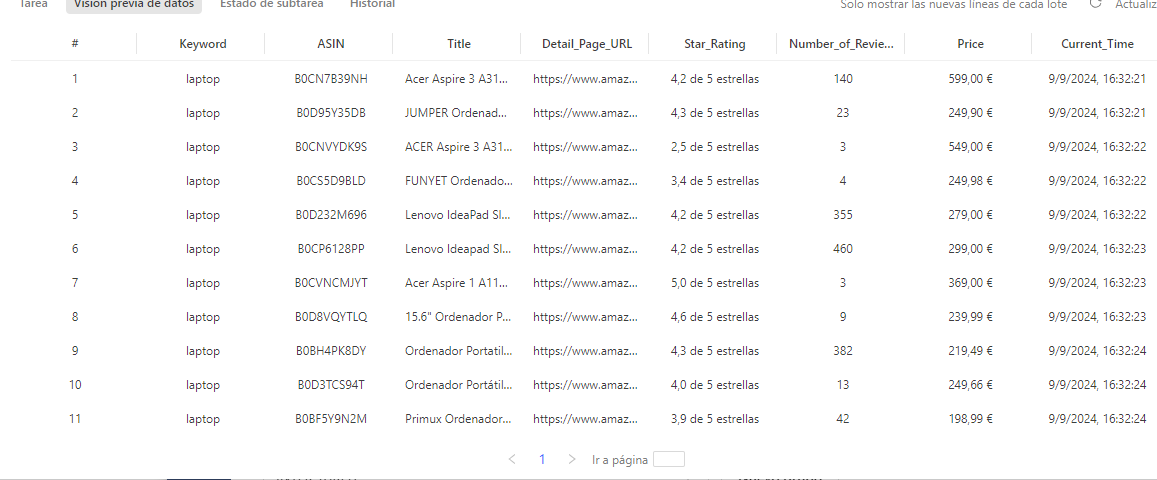
Sin embargo, eso no es todo!
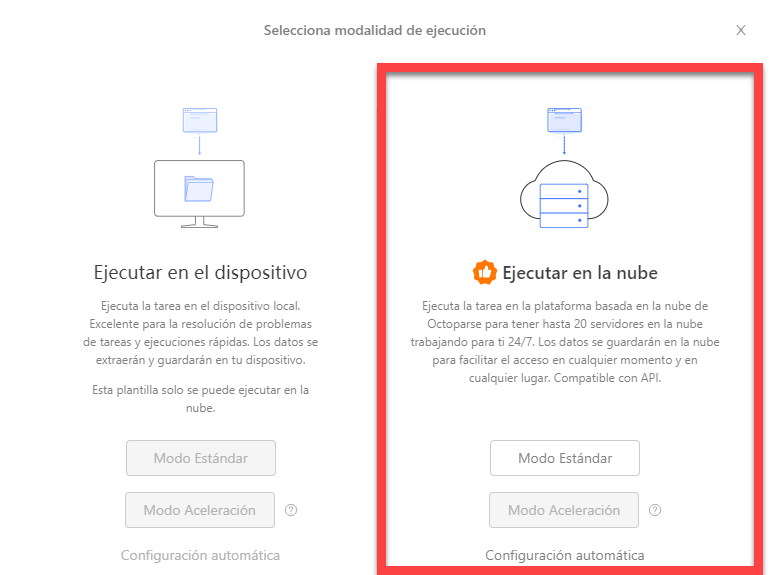
Octoparse también ofrece Extracción en la nube que le ayuda a scrapear 24/7 datos de Amazon con una velocida más rápida que la versin gratuita. Los datos extraídos se pueden exportar a Excel, CSV, HTML, Google Sheets o a la base de datos. Puede probar cómo scrapear datos de Amazon con la detección automática de Octoparse o usar las plantillas de Amazon.
Pensamientos Finales
Escribir guiones puede ser dificil ya que tiene altos costos iniciales y de mantenimiento. Ninguna página web es idéntica, si necesitas rastrear muchos sitios web, es imposible para nosotros escribir un script para cada sitio web, este no es un método sostenible. Además, los sitios web probablemente cambien su diseño y estructura. Entonces, tenemos que depurar y ajustar el rastreador en consecuencia. Los web crawlers son más prácticos para la extracción de datos a nivel empresarial con menos esfuerzos y costos.

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.



