El web scraping es el mejor método de recopilación de datos si lo que buscas es obtener datos de páginas web. A medida que el capital fluye por todo el mundo a través de Internet, el web scraping se utiliza ampliamente entre empresas, autónomos e investigadores, ya que ayuda a recopilar datos web de forma global, precisa y eficiente. Enumeramos aquí los 10 sitios web más raspados según la frecuencia de uso de las plantillas de tareas de Octoparse. Mientras que sigues leyendo, puede que se te ocurra tu propia idea de raspado web. No te preocupes si eres un novato en el raspado web. En este blog encontrarás la respuesta.
¿Qué es una plantilla de tarea Octoparse? Los programadores, para hacer scraping en la web, pueden escribir scripts y ejecutarlos en Python o de cualquier otra forma. Una plantilla de tarea es como un script ya escrito y la única parte que tiene que hacer es averiguar qué datos desea e introducir las palabras clave/URL en nuestra interfaz de plantilla de tarea.
Nota: Si tienes algún problema en el uso de las plantillas, no dudes en ponerte en contacto con nuestro soporte: support@octoparse.com.
Introducción
- Los sitios web de comercio electrónico son siempre los más escrapeados entre los demás, tanto en frecuencia como en cantidad. A medida que las compras en línea se convierten en un estilo de vida doméstico, el comercio electrónico afecta a personas de todos los ámbitos. Los vendedores en línea, los minoristas e incluso los consumidores son recolectores de datos de comercio electrónico.
- Los sitios de directorios ocupan el segundo lugar en la carrera y esto no es sorprendente en absoluto. Los directorios organizan las empresas por categorías, por lo que sirven como un filtro de información funcional que es una buena elección para la recopilación eficaz de datos. Muchos buscan en los directorios información de contacto para aumentar sus ventas.
- Las redes sociales incorporan una gran cantidad de información sobre las opiniones, emociones y acciones cotidianas de las personas. En general, el scraping de sitios de medios sociales es más difícil que el de otros. Esto se debe a que muchos sitios de redes sociales emplean fuertes técnicas anti-scraping con el fin de proteger la privacidad de los usuarios. Sin embargo, las redes sociales siguen siendo una importante fuente de información para el análisis de opiniones y todo tipo de investigaciones.
- Otros sitios pertenecen a categorías como el turismo, las bolsas de trabajo y los motores de búsqueda. De hecho, personas de todos los sectores aprovechan la técnica del web scraping para explotar el valor de los datos al servicio de sus intereses.
Vayamos directamente a la lista de los 10 sitios web más escrapeados en 2023 y cómo son de útiles para nuestros recopiladores de datos.
10 sitios web más raspados
10. Mercadolibre
Puede que Mercadolibre no resulte familiar a todos, pero es un mercado de comercio electrónico familiar en los países latinoamericanos, con Brasil como mayor contribuyente en ingresos. La pandemia acelera su crecimiento y ahora la empresa vale 63.000 millones de dólares en el Nasdaq. El Financial Times la describe como “la respuesta latinoamericana al Alibaba chino”.
Octoparse.es encontró que este sitio era el más popular entre nuestros usuarios españoles y formulamos la plantilla lista para usar donde los usuarios pueden introducir las URL de las páginas de anuncios y obtener los datos del producto: nombre del producto, precio, URL de la página de detalles, URL de las imágenes, etc.
Lectura relacionada:Cómo Extraer Detalles de Productos de Mercado Libre
9. Twitter
Según Statistics, hay unos 330 millones de usuarios activos mensuales y 145 millones de usuarios activos diarios en Twitter. Con un gran número de usuarios, Twitter no es sólo una plataforma para socializar y compartir, sino que también se convierte en un lugar perfecto para la creación de marcas y el marketing.
La gente busca datos en Twitter por diversas razones, como la investigación industrial, el análisis de sentimientos, la gestión de la experiencia del cliente, etc. Las plantillas de tareas para Twitter son muy consultadas en nuestro centro de soporte y hemos entregado un buen número de plantillas personalizables para nuestros clientes. Si utilizas plantillas pre-construidas en Octoparse, puede obtener datos de publicaciones o información del perfil de ciertos autores.
Lectura relacionada: Cómo Extraer Datos de Twitter | Descargar a Excel
8. Indeed
Según Indeed, el gigante del empleo ha recibido 175 millones de CV en total. Buscar trabajo por Internet es ahora tan natural que apenas recordamos cómo es una feria de empleo tradicional. Crear un agregador de empleo, sobre todo para nichos de mercado, se ha convertido en los últimos años en un negocio rentable. ¿Y adivina cómo se hace esto? Sí, el truco está en el web scraping.
Los creadores de portales de empleo no son los únicos que se benefician de los datos de estos sitios. Los profesionales de Recursos Humanos, los demandantes de empleo, los futuros demandantes de empleo y los investigadores especializados en contratación y mercados de trabajo están ávidos de datos de empleo. Si estás buscando trabajo, tener una visión global del mercado siempre te ayuda a la hora de negociar.
7. Tripadvisor
El sector turístico ha sufrido un duro golpe durante la pandemia y ahora se está recuperando. La necesidad de scrapear sitios web de turismo también cabe mencionarla. Pero, ¿por qué se raspan sitios web como booking.com, tripadvisor o Airbnb? Uno de los ejemplos podrían ser los agentes de servicios que ofrecen un servicio integrado a los turistas, incluida la venta de billetes y la reserva de hoteles y restaurantes.
El web scraping también se utiliza mucho para comparar precios y así es como la gente inteligente construye sitios de comparación de precios para dar servicio al público. Si lo intentas, puedes crear un comparador de precios de billetes de avión para ayudar a los turistas a reservar el más económico.
La plantilla Tripadvisor de Octoparse está disponible tanto en inglés como en español.
6. Google
Con su súper algoritmo de aprendizaje automático, Google podría ser el robot que conoce a todo el mundo mejor que sus familiares y amigos. Todo se relaciona con datos. Desde una perspectiva individual, ¿qué podemos obtener de Google?
Los profesionales del marketing SEO pueden ser el grupo de personas más interesadas en las búsquedas de Google. Extraen los resultados de búsqueda de Google para supervisar un conjunto de palabras clave, para recopilar información TDK (abreviatura de Title, Description, Keywords: metadatos de una página web que aparecen en la lista de resultados y que tienen una influencia fundamental en el porcentaje de clics) para una estrategia de optimización SEO.
Además de la extracción de resultados de búsqueda de Google, Octoparse también ofrece plantillas para Google Maps. Introduces la URL de la página de resultados de búsqueda, y Octoparse obtendrá datos bien organizados por ti de las tiendas relacionadas.
5. Páginas Amarillas
Según Wikipedia, Yellowpages.com, también conocido como “YP”, se fundó en 1996 y, a lo largo de décadas de desarrollo, el sitio se ha convertido en el sitio web de directorios más conocido y recibe 60 millones de visitantes al mes.
Pues bien, a ojos de la gente que se dedica al web scraping, yellowpages es el lugar perfecto para recopilar información de contacto y direcciones de empresas en función de su ubicación. Si eres minorista y buscas competidores en tu zona, es tan sencillo como hacer unos pocos clics. Si eres un vendedor y buscas generar clientes potenciales de forma eficiente, páginas amarillas también es una buena opción.
La siguiente captura de pantalla muestra los datos que la plantilla Octoparse puede obtener para ti: nombre de la tienda, valoración, dirección, número de teléfono, etc. Y los datos se pueden exportar a formatos como Excel, CSV, JSON, HTML, Google Sheets o base de datos.
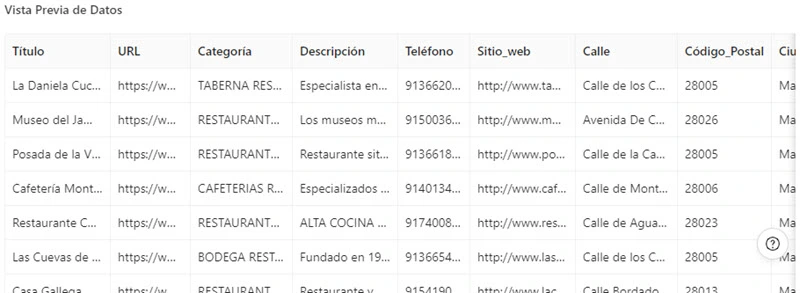
4. Yelp
Al igual que Yellowpages.com, Yelp puede ofrecerte datos de empresas en función de su ubicación. Y aún hay más. Cuando estás de viaje y te surge una pregunta: ¿quién tiene la mejor pizza de la ciudad? Ahí es donde Yelp entra en escena. Yelp no solo sirve como directorio de empresas, sino también como consultor gratuito para los consumidores que buscan comida, servicios a domicilio o un buen masaje.
Se trata de clasificaciones y reseñas, que son datos de oro para las empresas. Quienes se dedican al scraping de Yelp aprovechan los datos de las reseñas y el ranking para hacerse una idea de cómo se ve su negocio a los ojos de un cliente y también para analizar a la competencia.
3. Walmart
Si te interesa el panorama del comercio minorista, un artículo de Vox ha retratado una imagen de cómo los minoristas utilizan los datos para rastrear cada movimiento de sus clientes con el fin de promover las ventas. Los datos se utilizan para formar un mercado transparente y servir a los intereses de los compradores.
Los sitios de comparación de precios se generan bajo la labor del web scraping. Walmart puede ser uno de los objetivos del scraping, ya que su eslogan reza “Ahorra dinero vive mejor”. Esa es una de las razones por las que se hace scraping desde Walmart. Para los minoristas y las tiendas de comestibles, Walmart es también una importante fuente de información para obtener los datos del producto para un estudio de mercado.
2. eBay
Los sitios web de comercio electrónico son siempre los más populares para el web scraping y eBay es sin duda uno de ellos. Tenemos muchos usuarios que dirigen sus propios negocios en eBay y obtener datos de eBay es una forma importante de realizar un seguimiento de sus competidores y seguir la tendencia del mercado.
Hay una historia de un cliente que me impresionó mucho. El cliente es un vendedor de eBay y se dedica a extraer datos de eBay y otros mercados de comercio electrónico con regularidad, creando su propia base de datos a lo largo del tiempo para realizar estudios de mercado en profundidad.
1. Amazon
Sí, no es de extrañar que Amazon ocupe el primer puesto en el ranking de los sitios web más escrapeados. Amazon se lleva la palma en el negocio del comercio electrónico, lo que significa que los datos de Amazon son los más representativos para cualquier tipo de estudio de mercado. Tiene la base de datos más grande.
Sin embargo, obtener datos de comercio electrónico es difícil. El mayor reto para el scraping de Amazon podría ser el captcha y nosotros nos encargamos de ello. El captcha es una forma de evitar que el sitio se bloquee, ya que son muchos los que ansían los datos de Amazon y el raspado frecuente puede sobrecargar los servidores. Octoparse emplea la extracción en la nube y la rotación de IP, que pueden dar en el clavo perfectamente.
El scraping de Amazon puede proporcionarte datos para todos los fines indicados a continuación:
- Seguimiento de precios
- Análisis de la competencia
- Monitorización MAP
- Selección de productos
- Análisis del sentimiento
…
Utilizando la plantilla Octoparse Amazon, puedes recopilar datos de productos como ASIN, clasificación por estrellas, precio, color, estilo, reseñas y mucho más.
Pensamientos Finales
Los datos son el nuevo petróleo, pero sin una herramienta práctica no todo el mundo es capaz de sacarles partido. Octoparse trabaja para facilitar el acceso del público a los datos, tanto si saben programar como si no. De este modo, todos podemos echar mano de los datos necesarios y crear valor para el mundo a través del análisis de datos.
Si te interesa generar opiniones originales y solo te faltan los datos que te respalden, ¡prueba a conseguir tus datos!



