Herramienta de Web Scraping (también conocido como extracción de datos de la web, web crawling) se ha aplicado ampliamente en muchos campos hoy en día. Antes de que un web scraper llegue al público, es la palabra mágica para personas normales sin habilidades de programación. Su alto umbral sigue bloqueando a las personas fuera de Big Data.
Una herramienta de web scraping es la tecnología de recopila automatizada y cierra la brecha entre Big Data y cada persona. En este artículo enumeré 20 MEJORES herramienta de web scraping incluyendo sus caracterísiticas y público objetivo para que tomes como referencia.
¡Bienvenido a aprovecharlo al máximo!
¿Cómo Ayudan las Herramientas de Web Scraper?
Antes de empezar, usted puede aprender los puntos clave que cómo puede un web scraper le ayuda.
- Liberar tus manos de hacer trabajos repetitivos de copiar y pegar
- Colocar los datos extraídos en un formato bien estructurado que incluye, entre otros, Excel, HTML y CSV
- Ahorrarte tiempo y dinero al obtener un analista de datos profesional
- Es la cura para comercializador, vendedores, periodistas, YouTubers, investigadores y muchos otros que carecen de habilidades técnicas
Conozca más casos de uso y sectores a los que pueden ayudar las tecnologías de scraping y web scraper.
Los 20 Web Scraper que No te Puedes Perder
Herramientas de Web Scraper para Windows /Mac
1. Octoparse – Gratis
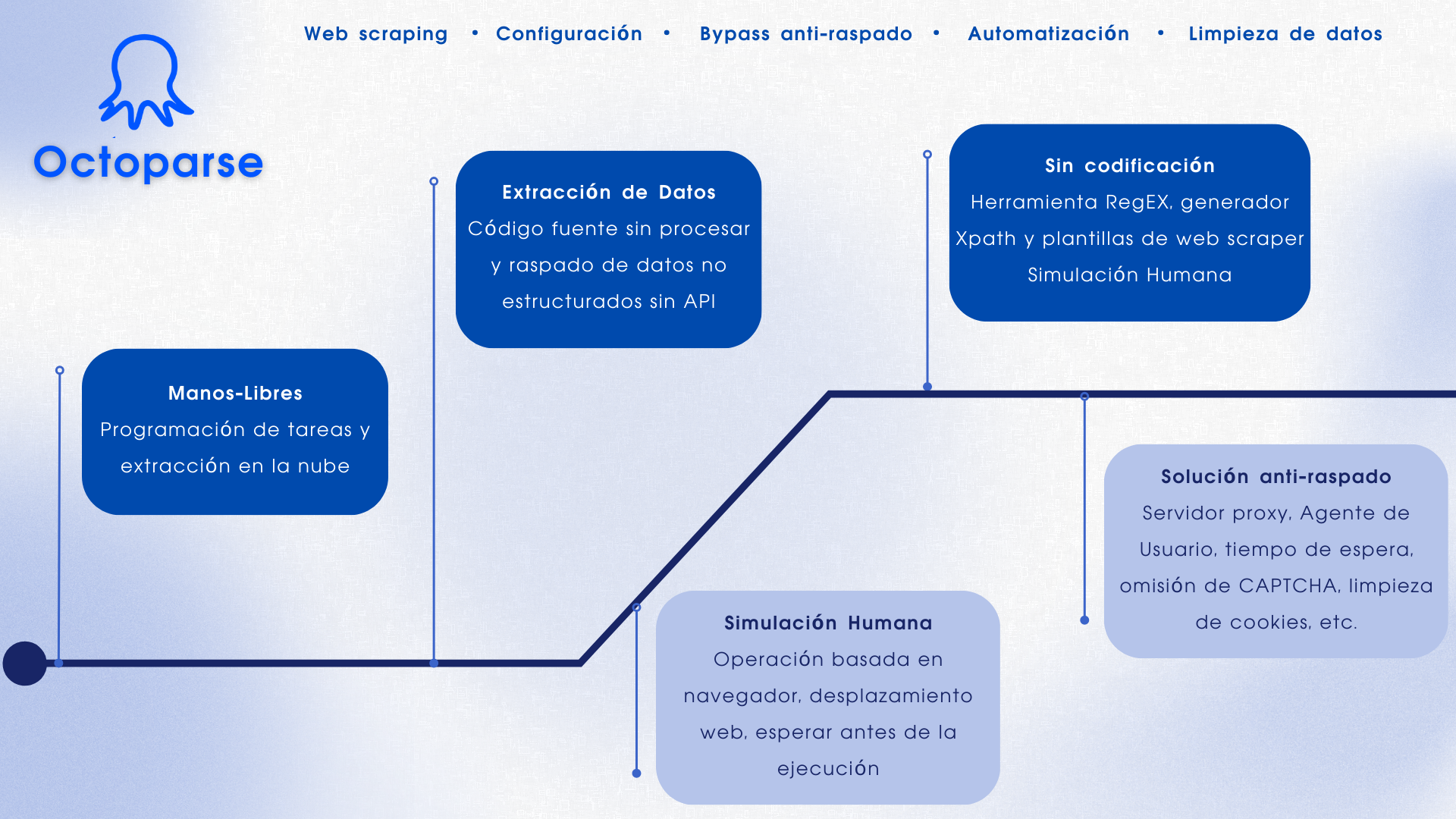
Octoparse es una herramienta gratuita de rastreo web basada en sistemas Windows y macOS para obtener datos web en hojas de cálculo fácilmente. Con una interfaz de apuntar y hacer clic fácil de usar, el software está construido específicamente para los no codificadores. El plan gratuito de Octoparse ya podría satisfacer las básicas necesidades de recopilación de los usuarios sin ninguna habilidad de codificación.
Aquí tienes un vídeo sobre Octoparse, también las principales características y pasos sencillos, para que puedas conocerlo mejor:
Principales características de Octoparse Web Crawler
- Extracción programada de nubes: Extrae datos dinámicos en tiempo real.
- Modo de detección automática: Obtenga datos de páginas web raspadas automáticamente.
- Plantillas predefinidas: Scrapea datos de sitios web populares con unos pocos clics.
- Evite el bloqueo: Servicios en la nube y servidores proxy IP para eludir ReCaptcha y el bloqueo.
- Limpieza de datos: Configuración Regex y XPath integrada para limpiar los datos automáticamente.
Octoparse también proporciona plantillas de raspado de datos en línea fáciles de usar, que le permiten extraer datos rápidamente introduciendo unos pocos parámetros y sin descargar ningún software. Pruébelo a continuación:
https://www.octoparse.es/template/google-maps-review-scraper
2. ParseHub

Parsehub es un excelente web scraper que admite la recopilación de datos de la web que utilizan tecnología AJAX, JavaScript, cookies, etc. Sutecnología de aprendizaje automático puede leer, analizar y luego transformar documentos web en datos relevantes.
- Aplicación web compatible con sistemas como Windows, Mac OS X y Linux, integrada en el navegador.
- No puede crear más de 5 proyectos públicos gratuitos. El plan de suscripción de pago te permite crear al menos 20 proyectos privados para buscar en el sitio.
- Está dirigido a casi cualquier persona que quiera jugar con datos. Pueden utilizarlo desde analistas a científicos de datos, pasando por periodistas.
3. Visual Scraper
Visual Scraper es otra excelente herramienta gratuita de raspado web sin código con una sencilla interfaz de apuntar y hacer clic.
- Obtiene datos en tiempo real de múltiples páginas web y exporta los datos extraídos a archivos CSV, XML, JSON o SQL.
- Además de SaaS, VisualScraper ofrece servicios de búsqueda web, como servicios de entrega de datos y servicios de creación de extracción de software.
- Las tareas pueden programarse para que se ejecuten a una hora determinada o en una secuencia repetitiva cada minuto, cada día, cada semana, cada mes o cada año. 4. Los usuarios pueden utilizarlo para extraer noticias y foros de forma periódica.
4. 80legs

80legs es una poderosa herramienta de web crawling que se puede configurar según los requisitos personalizados. Admite la obtención de grandes cantidades de datos junto con la opción de descargar los datos extraídos al instante. 80legs proporciona un rastreo web de alto rendimiento que funciona rápidamente y obtiene los datos requeridos en solo segundos.
80legs es utilizado por una amplia variedad de empresas. Cualquier empresa que necesite datos extraídos de la web puede usar 80legs para sus necesidades.
5. WebHarvy
WebHarvy es un software de web scraping de apuntar y hacer clic. Está diseñado para no programadores. WebHarvy puede scrapear automáticamente Texto, Imágenes, URL y Correos Electrónicos de sitios web, y guardar el contenido raspado en varios formatos. También proporciona un programador incorporado y soporte proxy que permite el rastreo anónimo y evita que el software de web crawler sea bloqueado por servidores web, tiene la opción de acceder a sitios web objetivo a través de servidores proxy o VPN.
Los usuarios pueden guardar los datos extraídos de las páginas web en una variedad de formatos. La versión actual de WebHarvy Web Scraper te permite exportar los datos raspados como un archivo XML, CSV, JSON o TSV. Los usuarios también pueden exportar los datos raspados a una base de datos SQL.
6. Content Grabber
Content Grabber es un software de web crawler dirigido a empresas. Te permite crear agentes de rastreo web independientes. Puedes extraer contenido de casi cualquier sitio web y guardarlo como datos estructurados en el formato que elijes, incluidos los informes de Excel, XML, CSV y la mayoría de las bases de datos.
Es más adecuado para personas con habilidades avanzadas de programación, ya que proporciona muchas potentes de edición de guiones y depuración de interfaz para aquellos que lo necesitan. Los usuarios pueden usar C # o VB.NET para depurar o escribir scripts para controlar la programación del proceso de scraping. Por ejemplo, Content Grabber puede integrarse con Visual Studio 2013 para la edición de secuencias de comandos, la depuración y la prueba de unidad más potentes para un rastreador personalizado avanzado y discreto basado en las necesidades particulares de los usuarios.
7. Helium Scraper
Helium Scraper es un software visual de datos web scraping que funciona bastante bien cuando la asociación entre elementos es pequeña. No es codificación, no es configuración. Y los usuarios pueden obtener acceso a plantillas en línea basadas en diversas necesidades de web scraping.
Básicamente, podría satisfacer las necesidades de web scraping de los usuarios dentro de un nivel elemental.
Descargadores de sitios web
8. Cyotek WebCopy

WebCopy es un web crawler gratuito que te permite copiar sitios parciales o completos localmente web en tu disco duro para referencia sin conexión.
Puedes cambiar su configuración para decirle al bot cómo deseas capturar. Además de eso, también puedes configurar alias de dominio, cadenas de agente de usuario, documentos predeterminados y más.
Sin embargo, WebCopy no incluye un DOM virtual ni ninguna forma de análisis de JavaScript. Si un sitio web hace un uso intensivo de JavaScript para operar, es más probable que WebCopy no pueda hacer una copia verdadera. Es probable que no maneje correctamente los diseños dinámicos del sitio web debido al uso intensivo de JavaScript
9. HTTrack
Como programa gratuito de rastreo de sitios web, HTTrack proporciona funciones muy adecuadas para descargar un sitio web completo a su PC. Tiene versiones disponibles para Windows, Linux, Sun Solaris y otros sistemas Unix, que cubren a la mayoría de los usuarios. Es interesante que HTTrack pueda reflejar un sitio, o más de un sitio juntos (con enlaces compartidos). Puedes decidir la cantidad de conexiones que se abrirán simultáneamente mientras descarga las páginas web en “establecer opciones”.
Puedes obtener las fotos, los archivos, el código HTML de su sitio web duplicado y reanudar las descargas interrumpidas. Además, el soporte de proxy está disponible dentro de HTTrack para maximizar la velocidad.
HTTrack funciona como un programa de línea de comandos, o para uso privado (captura) o profesional (espejo web en línea). Dicho esto, HTTrack debería ser preferido por personas con habilidades avanzadas de programación.
10. Getleft
Getleft es un web spider gratuito y fácil de usar. Te permite descargar un sitio web completo o cualquier página web individual. Después de iniciar Getleft, puedes ingresar una URL y elegir los archivos que deseas descargar antes de que comience. Mientras avanza, cambia todos los enlaces para la navegación local. Además, ofrece soporte multilingüe. ¡Ahora Getleft admite 14 idiomas! Sin embargo, solo proporciona compatibilidad limitada con Ftp, descargará los archivos pero no de forma recursiva.
En general, Getleft debería poder satisfacer las necesidades básicas de scraping de los usuarios sin requerir habilidades más sofisticadas.
Extensiones de Web Scraper
11. Scraper
Scraper es una extensión de Chrome con funciones de extracción de datos limitadas, pero es útil para realizar investigaciones en línea. También permite exportar los datos a las hojas de cálculo de Google. Puedes copiar fácilmente los datos al portapapeles o almacenarlos en las hojas de cálculo con OAuth. Scraper puede generar XPaths automáticamente para definir URL para scraping.
No ofrece servicios de scraping todo incluido, pero puede satisfacer las necesidades de extracción de datos de la mayoría de las personas.
12. OutWit Hub

OutWit Hub es un complemento de Firefox con docenas de funciones de extracción de datos para simplificar sus búsquedas en la web. Esta herramienta de web scraping puede navegar por las páginas y almacenar la información extraída en un formato adecuado.
OutWit Hub ofrece una interfaz única para extraer pequeñas o grandes cantidades de datos por necesidad. OutWit Hub te permite eliminar cualquier página web del navegador. Incluso puedes crear agentes automáticos para extraer datos.
Es una de las herramientas de web scraping más simples, de uso gratuito y te ofrece la comodidad de extraer datos web sin escribir código.
Servicios y Soluciones de Datos con Web Scraping
13. Scrapinghub

Scrapinghub es una Herramienta de Extracción de Datos basada Cloud que ayuda a miles de desarrolladores a obtener datos valiosos. Su herramienta de scraping visual de código abierto permite a los usuarios raspar sitios web sin ningún conocimiento de programación.
Scrapinghub utiliza Crawlera, un rotador de proxy inteligente que admite eludir las contramedidas de robots para rastrear fácilmente sitios enormes o protegidos por robot. Permite a los usuarios rastrear desde múltiples direcciones IP y ubicaciones sin la molestia de la administración de proxy a través de una simple API HTTP.
Scrapinghub convierte toda la página web en contenido organizado. Su equipo de expertos está disponible para obtener ayuda en caso de que su generador de rastreo no pueda cumplir con sus requisitos
14. Dexi.io
Como web scraping basado en navegador, Dexi.io te permite scrapear datos basados en su navegador desde cualquier sitio web y proporcionar tres tipos de robots para que puedas crear una tarea de scraping: extractor, rastreador y tuberías.
El software gratuito proporciona servidores proxy web anónimos para tu web scraping y tus datos extraídos se alojarán en los servidores de Dexi.io durante dos semanas antes de que se archiven los datos, o puedes exportar directamente los datos extraídos a archivos JSON o CSV. Ofrece servicios pagos para satisfacer tus necesidades de obtener datos en tiempo real.
15. Webhose.io
Webhose.io permite a los usuarios obtener recursos en línea en un formato ordenado de todo el mundo y obtener datos en tiempo real de ellos. Este web crawler te permite rastrear datos y extraer palabras clave en muchos idiomas diferentes utilizando múltiples filtros que cubren una amplia gama de fuentes
Y puedes guardar los datos raspados en formatos XML, JSON y RSS. Y los usuarios pueden acceder a los datos del historial desde su Archivo. Además, webhose.io admite como máximo 80 idiomas con sus resultados de crawling de datos. Y los usuarios pueden indexar y buscar fácilmente los datos estructurados rastreados por Webhose.io.
En general, Webhose.io podría satisfacer los requisitos elementales de web scraping de los usuarios.
16. Import. io
Los usuarios pueden formar sus propios conjuntos de datos simplemente importando los datos de una página web en particular y exportando los datos a CSV.
Puede scrapear fácilmente miles de páginas web en minutos sin escribir una sola línea de código y crear más de 1000 API en función de sus requisitos. Las API públicas han proporcionado capacidades potentes y flexibles, controla mediante programación Import.io para acceder automáticamente a los datos, Import.io ha facilitado el rastreo integrando datos web en su propia aplicación o sitio web con solo unos pocos clics.
Para satisfacer mejor los requisitos de rastreo de los usuarios, también ofrece una aplicación gratuita para Windows, Mac OS X y Linux para construir extractores y rastreadores de datos, descargar datos y sincronizarlos con la cuenta en línea. Además, los usuarios pueden programar tareas de rastreo semanalmente, diariamente o por hora.
RPA Tools para Web Scraping
17. UiPath

UiPath es un software robótico de automatización de procesos para capturar automáticamente una web. Puede capturar automáticamente datos web y de escritorio de la mayoría de las aplicaciones de terceros. Si lo ejecutas en Windows, puedes instalar el software de automatización de proceso. Uipath puede extraer tablas y datos basados en patrones en múltiples páginas web.
Uipath proporciona herramientas incorporados para un mayor web scraping. Este método es muy efectivo cuando se trata de interfaces de usuario complejas. Screen Scraping Tool puede manejar elementos de texto individuales, grupos de texto y bloques de texto, como la extracción de datos en formato de tabla.
Además, no se necesita programación para crear agentes web inteligentes, pero el .NET hacker dentro de ti tendrá un control completo sobre los datos.
18. Octoparse AI
Octoparse AI es la herramienta flexible de automatización robótica de procesos que se adapta a su forma de trabajar.
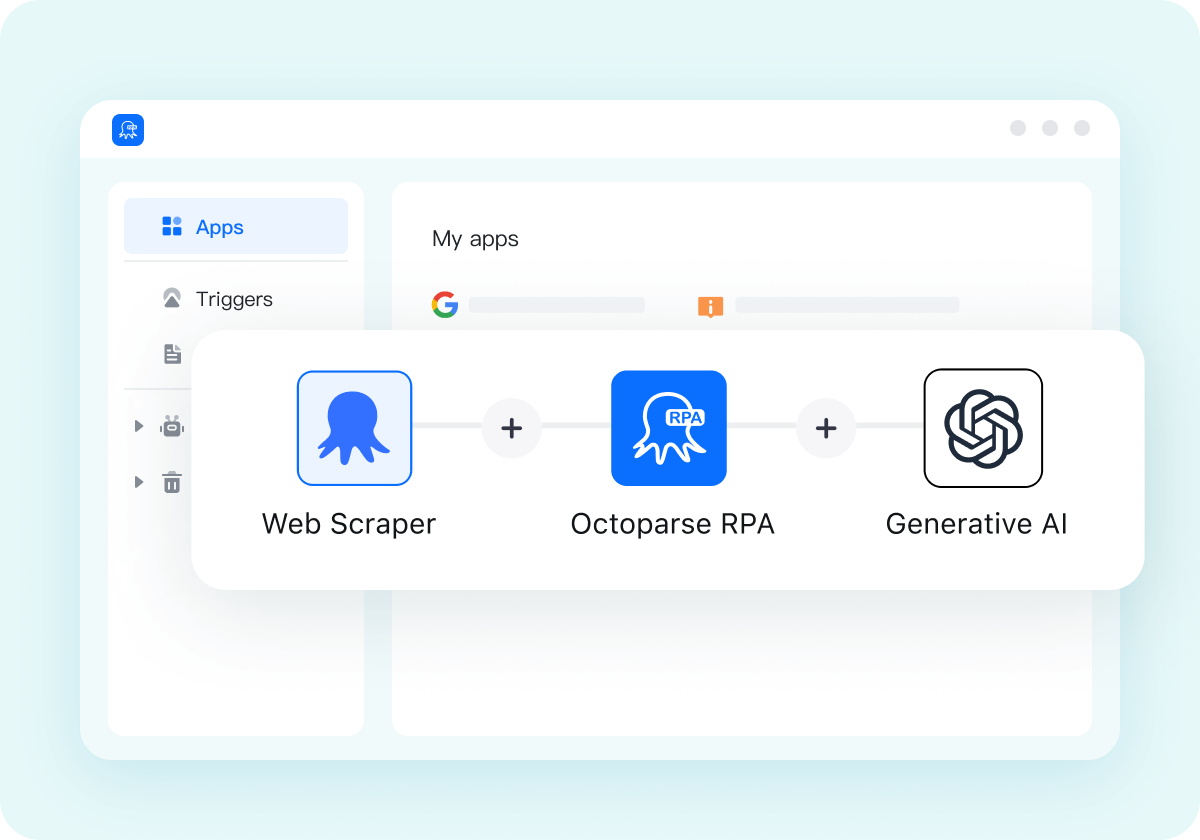
Limpio y tranquilo, Octoparse AI permite a cualquiera crear automatizaciones para su uso personal o en equipo con una solución de arrastrar y soltar que funciona tanto para aplicaciones Windows como para navegadores. Automatice sus procesos digitales con simplicidad sin código para lograr un tiempo de creación de valor increíblemente rápido. De cero a la automatización en minutos.
Bibliotecas para Programadores
19. Scrape.it

Scrape.it es un software node.js de web scraping. Es una herramienta de extracción de datos web basada en la nube. Está diseñado para aquellos con habilidades avanzadas de programación, ya que ofrece paquetes públicos y privados para descubrir, reutilizar, actualizar y compartir código con millones de desarrolladores en todo el mundo. Su potente integración te ayudará a crear un rastreador personalizado según tus necesidades.
20. ProWebScraper
ProWebScraper es un web scraper automatizado diseñado para la extracción de contenido web a escala empresarial que necesita una solución a escala empresarial. Los usuarios comerciales pueden crear fácilmente agentes de extracción en tan solo unos minutos, sin ninguna programación. La API REST de Prowebscraper puede extraer datos de páginas web para ofrecer respuestas instantáneas en segundos.
Los usuarios pueden crear fácilmente agentes de extracción simplemente apuntando y haciendo clic.
Conclusión
Este artículo primero dio una idea sobre Web Scraping en general. Luego enumeró 20 de las mejores herramientas de raspado web del mercado, considerando una serie de factores. La principal conclusión de este artículo, por lo tanto, es que al final, un usuario debe elegir las herramientas de raspado web que se adapten a sus necesidades.
Deseo que este artículo te pueda ayudar a tomar una decisión informada con respecto a la mejor herramienta de raspado web para su negocio o trabajo.




