Probablemente haya escuchado sobre Machine Learning miles de veces de todo tipo de publicaciones/artículos, pero ¿tiene alguna idea de lo que realmente es? Bueno, en este artículo he incluido los 8 términos clave que debe conocer más directamente relacionados con el aprendizaje automático. Nada sofisticado y complicado, así que espero que cualquiera que esté interesado en Machine Learning pueda obtengar algunos puntos útiles de leer esta publicación.
Proceso de lenguaje natural (NLP)
NLP es un concepto muy común para el aprendizaje automático. Había hecho posible que una computadora leyera el lenguaje humano y lo incorporara a todo tipo de procesos.
Las aplicaciones más conocidas para NLP incluyen:
(a) Clasificación de texto y ordenar
Se trata de clasificar textos en diferentes categorías, o de ordenarla lista de texto según su relevancia. Por ejemplo, se puede usar para filtrar correos no deseados (al analizar si el mensaje es spam), o en una perspectiva empresarial también se puede usar para identificar y extraer información relacionada con sus competidores.
(b) Análisis de sentimientos
Con el análisis de sentimientos, una computadora podrá descifrar los sentimientos, como la ira, la tristeza, el deleite, etc. a través del análisis de cadenas de texto. Así que, básicamente, una computadora podrá determinar si las personas se sienten felices, tristes o enojadas mientras escriben las palabras o las oraciones. Esto se usa ampliamente en la encuesta de satisfacción del cliente para analizar cómo se sienten los clientes hacia un producto.
(c) Extracción de información
Esto se usa principalmente para resumir un párrafo largo en un texto corto, al igual que crear un resumen.
(d) Named-entity recognition
Supongamos que ha extraído algunos datos de perfil desordenados, como una dirección, teléfono, nombre y más, todo mezclado entre sí. ¿Desea organizar los datos de alguna manera para poder identificarlos rápidamente y hacer coincidir los datos con el tipo de datos correcto? Así es exactamente cómo Named-entity extraction ayuda a convertir la información desordenada en datos estructurados.
(e) Speech recognition
Un gran ejemplo de esto, Siri de Apple.
(f) Comprensión y generación del lenguaje natural
NLU es usar la computadora para transformar expresiones humanas en expresiones de computadora. Por el contrario, la generación del lenguaje natural es transformar las expresiones de computadora en expresiones humanas. Esta tecnología se usa muy comúnmente para la comunicación humana con robots.
(g) Traducción automática
La traducción automática es traducir textos a otro idioma (o cualquier idioma específico) automáticamente.
Database
Database es un componente necesario en el aprendizaje automático. Si desea establecer un sistema de aprendizaje automático, deberá recopilar datos de recursos públicos o generar nuevos datos. Todos los datasets que se utilizan para el aprendizaje automático se combinan para formar database. En general, los científicos dividirán los datos en tres categorías:
Train dataset: Train dataset se utiliza para modelos de entrenamiento. A través de la capacitación, los modelos de aprendizaje automático podrán reconocer las características importantes de los datos.
Validar dataset: Validar conjunto de datos se utiliza para reparar los coeficientes de los modelos y comparar modelos para elegir el óptimo. Validar el conjunto de datos es diferente del conjunto de datos del tren, y no se puede usar en la sección de capacitación, ya que puede producirse un sobreajuste y afectar negativamente la nueva generación de datos.
Conjunto de datos de prueba: Una vez que se confirma el modelo, el dataset de prueba se utiliza para probar el rendimiento del modelo en un nuevo conjunto de datos.
En el aprendizaje automático tradicional, la proporción de estos tres conjuntos de datos es 50/25/25; sin embargo, algunos modelos no necesitan mucho ajuste o el dataset del entrenamiento puede ser una combinación de capacitación y validación (cross-validation), por lo tanto, la proporción de entrenamiento/prueba puede ser 70/30.
Computer vision
Computer vision es un campo de inteligencia artificial que se enfoca en analizar y comprender datos de figuras y videos. Los problemas que a menudo vemos en Computer vision incluyen:
Clasificación de imágenes: La clasificación de imágenes es una tarea de visión por computadora que le enseña a la computadora a reconocer ciertas imágenes. Por ejemplo, capacitar el modelo para reconocer objetos particulares apareció en lugares específicos.
Detección de objetivos: La detección de objetivos es enseñar al modelo a detectar una clase particular de una serie de categorías predefinidas, y usar rectángulos para rodearlos. Por ejemplo, la detección de objetivos se puede utilizar para configurar el sistema de reconocimiento facial. El modelo puede detectar todos los asuntos predefinidos y resaltarlos.
Segmentación de imagen: La segmentación de imagen es el proceso de dividir una imagen digital en múltiples segmentos (conjuntos de píxeles, también conocidos como super-pixels). El objetivo de la segmentación es simplificar y/o cambiar la representación de una imagen en algo que sea más significativo y más fácil de analizar.
Prueba de significación: Una vez que los sample data se han reunido a través de un estudio o experimento de observación, la inferencia estadística permite a los analistas evaluar la evidencia a favor o alguna afirmación sobre la población de la que se extrajo la muestra. Los métodos de inferencia utilizados para respaldar o rechazar afirmaciones basadas en datos de muestra se conocen como pruebas de significación.
Aprendizaje supervisado
Supervised learning es la tarea de aprendizaje automático de inferir una función a partir de datos de entrenamiento etiquetados. Un algoritmo de aprendizaje supervisado analiza los datos de entrenamiento y produce una función inferida, que puede usarse para mapear nuevos ejemplos. Un escenario óptimo permitirá que el algoritmo determine correctamente las class labels para instancias invisibles. Esto requiere que el learning algorithm se generalice de los datos de entrenamiento a situaciones invisibles de una manera “razonable”.
Unsupervised learning
Unsupervised machine learning es la tarea de aprendizaje automático de inferir una función para describir la estructura oculta a partir de datos “no etiquetados” (una clasificación o categorización no se incluye en las observaciones). Dado que los ejemplos dados al alumno es unlabeled, no existe evaluar la precisión de la estructura de la salida del algoritmo relevante, que es una forma de distinguir el Supervised learning y Unsupervised learning

Reinforcement learning
Reinforcement learning es diferente de lo que acabamos de discutir. Reinforcement learning es como el proceso de jugar con computadoras, y su objetivo es entrenar a las computadoras para que tomen medidas en un entorno a fin de maximizar algunos tipos de recompensas acumulativas. Durante una serie de experimentos, la computadora aprende una serie de patrones de juego, y durante un juego, la computadora puede usar el patrón óptimo para maximizar su recompensa.
Un ejemplo bien conocido es Alpha Go, el Alpha Go venció al mejor jugador de ajedrez humano. Recientemente, Reinforcement learning también se ha aplicado a las ofertas en tiempo real.
Neural network
Neural networks son sistemas informáticos inspirados en las redes neuronales biológicas que constituyen cerebros animales. Al igual que en el cerebro, muchas redes se interconectan y forman una red, la red neuronal artificial (ANN) está constituida por muchas capas. Cada capa es un conjunto de una serie de neurons. Una ANN puede procesar datos consecutivamente, lo que significa que solo la primera capa está conectada con las entradas, junto con el aumento de las capas, una ANN se vuelve más complicada. Cuando las capas se hacen muy grandes, el modelo se convierte en un modelo de aprendizaje profundo. Es difícil definir un ANN con un cierto número de capas. Hace 10 años, las ANN con solo 3 capas son lo suficientemente, ahora generalmente necesitamos 20 capas.
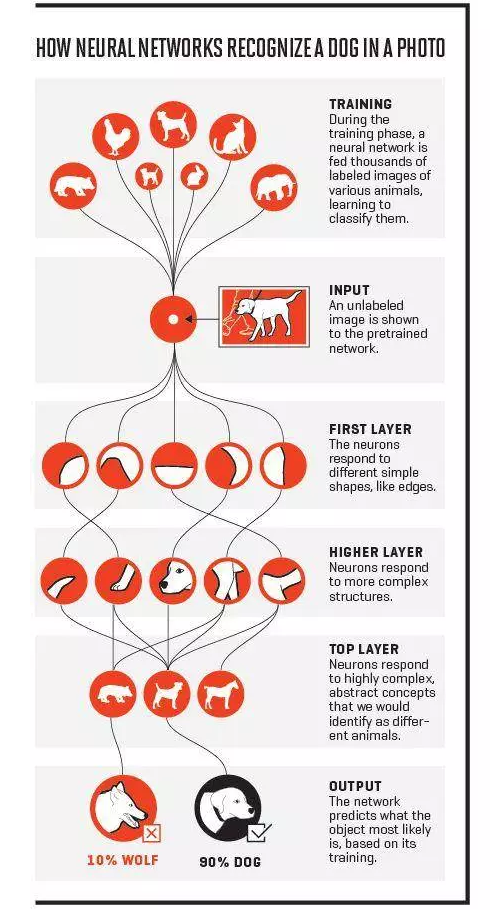
NNs tienen muchas variantes, las de uso común son:
- Convolutional Neural Network – hizo grandes avances en la visión por computadora
- Recurrent neural network – creada para procesar datos con función de secuencia, como texto y precios de acciones.
- Red totalmente conectada – es el modelo más sencillo utilizado para procesar datos estáticos/tabulares.
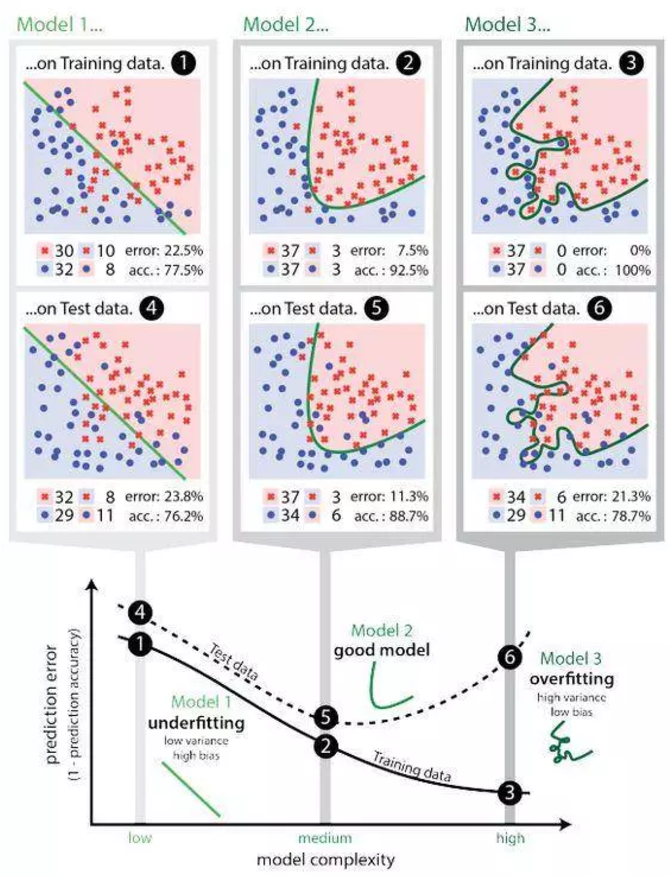
Overfitting
El sobreajuste es “la producción de un análisis que corresponde demasiado o exactamente a un conjunto particular de datos y, por lo tanto, puede no ajustarse a datos adicionales o predecir observaciones futuras de manera confiable”. En otras palabras, cuando un modelo aprende de datos insuficientes, se produciría una desviación, que puede afectar negativamente al modelo.
Este es un problema común pero crítico.
Cuando se produce un sobreajuste, generalmente significa que el modelo tomará ruidos aleatorios como entrada de datos, y lo tomará como una señal importante para encajar, y es por eso que el modelo puede comportarse peor en los datos nuevos (también hay desviaciones en los ruidos aleatorios). Esto sucede mucho en algunos modelos complicados, como las redes neuronales o los modelos de gradiente de aceleración.