Introducción
Extraer datos de sitios web dinámicos no siempre fácil, sobre todo si no eres programador. AJAX, Javascript, el desplazamiento infinito (infinite scroll) o los botones de “Cargar más” hacen que la tarea parezca imposible.
La buena noticia es que hoy existen herramientas sin código como Octoparse que permiten manejar incluso los sitios más complejos- sin necesidad de escribir una sola línea de código.
En este artículo aprenderás cómo funciona el scraping en sitios dinámicos, por qué es desafiante, y cómo Octoparse lo simplifica con flujos visuales y automatización inteligente.
¿Qué es AJAX y por qué complica el web scraping?
AJAX (Asynchronous JavaScript and XML) es una técnica que permite partes de una página web se actualicen sin recargarla por completo.
Exto significa que la información que ves (por ejemplo, productos, precios o comentarios) se carga en segundo plano después de que la página ya está visible.
Por eso, cuando intentas hacer scraping tradicional, esos datos pueden no aparecer en el código HTML inicial y necesitas herramientas o estrategias que esperen, ejecuten Javascript o simulen interacciones de usuario.
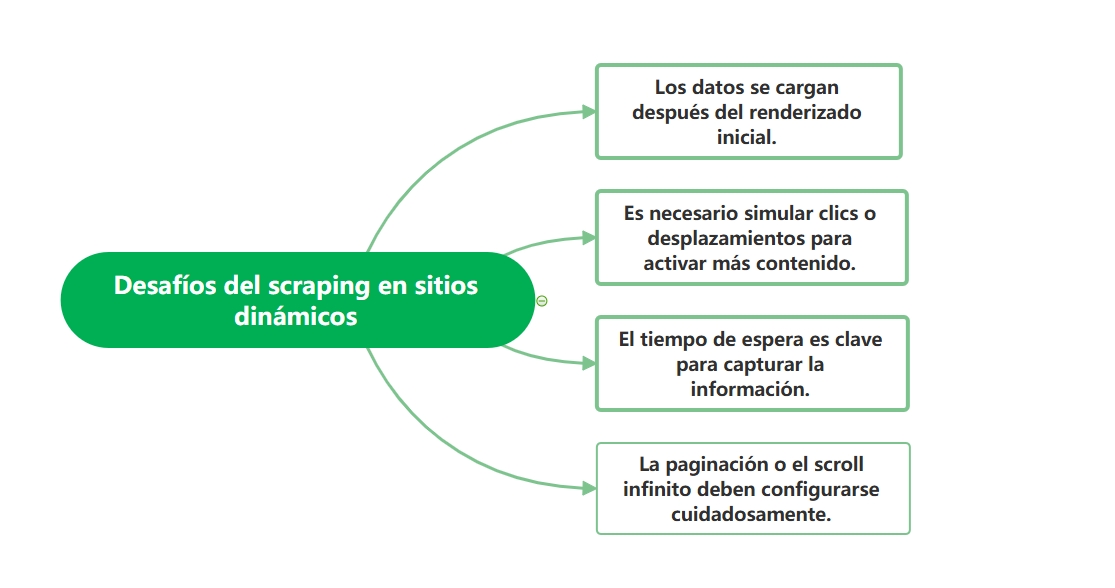
Preguntas más frecuentes sobre el scraping de contenido dinámico
1. ¿Cómo hacer scraping en sitios con desplazamiento infinito?
Muchos sitios usan desplazamiento infinito para cargar más datos conforme el usuario baja.
Aunque podrías usar herramientas como Selenium o Puppeteer para simular el scroll, hay un método más eficiente:
- Abre las DevTools del navegador (F12).
- En la pestaña Network, busca solicitudes XHR o Fetch cuando te desplaces.
- Casi siempre verás endpoints como /api/products?offset=20. Esa es la API que carga los datos.
En lugar de hacer scroll durante minutos, puedes extraer esos datos directamente desde la API. Si el sitio exige desplazamiento real, Octoparse ofrece una acción de scroll automático, con tiempos de espera y límites configurables.
2. ¿Cómo manejar botones de “Cargar más” o “Siguiente”?
Muchos sitios muestran los resultados en bloques, con un botón “Cargar más”.
En esos casos:
- Primero, revisa si existe un patrón de URL o parámetro que cambie. Si lo hay, puedes acceder directamente a esos enlaces.
- Si no, Octoparse puede automatizar los clics y esperar a que el nuevo contenido se cargue antes de continuar.
- Puedes configurar bucles, tiempos de espera AJAX y límites para evitar duplicados.
👉 Consejo: siempre verifica que el número de resultados cambie después de cada clic. Si no cambia, probablemente el botón no está cargando datos nuevos.
3. ¿Cómo manejo sitios que utilizan AJAX pesado como Facebook o Gumtree?
Algunos sitios, como Facebook, están diseñados específicamente para evitar el scraping automatizado. Usan detección de bots, cambios constantes en el DOM y límites agresivos.
Sin embargo, plataformas más abiertas como Gumtree son manejables.
El flujo recomendado es:
- Usa las DevTools para observar cómo se cargan los datos.
- Busca APIs o solicitudes JSON,
- Si no hay una API visible, usa un navegador automatizado como Playwright o Puppeteer.
- Maneja las limitaciones de velocidad (rate limits) agregando pausas entre solicitudes.
Con Octoparse, puedes realizar todo esto visualmente: detectar contenido AJAX, hacer clics automáticos y configurar esperas sin escribir código.
4. ¿Puedo extraer contenido paginado que se carga bajo demanda?
✅Absolutamente, y de hecho, este es uno de los patrones más sencillos una vez que lo entiendes.
Básicamente existen tres tipos de paginación:
Tipo 1: Paginación basada en URL Por ejemplo: ?page=2, ?offset=20. Este es un regalo. Simplemente crea un bucle que recorra los parámetros. Verifica la última página para encontrar el límite superior y luego itera. Puedes hacerlo con apenas 10 líneas de código.
Tipo 2: Paginación basada en solicitudes POST La página envía solicitudes POST con los datos de paginación en el cuerpo del mensaje. Es un poco más complicado, pero solo necesitas replicar esas solicitudes POST. Copia los encabezados (especialmente Content-Type y cualquier token de autenticación), copia la estructura del cuerpo (payload), y repite el proceso en bucle.
Tipo 3: Paginación basada en cursores Cada respuesta incluye un campo next_cursor o un token para la siguiente página. Necesitas la respuesta anterior para obtener la siguiente. Mantén una variable de cursor y actualízala con cada respuesta hasta que el valor sea nulo.
👉Consejo: Después de años haciendo esto, siempre empiezo buscando parámetros en la URL. Revisa el código fuente de la página, los enlaces <a> de paginación o los formularios. Si encuentras un patrón, puedes evitar el 90% de la complejidad.
5. ¿Es posible hacer scraping en sitios controlados por JavaScript?
✅Sí, y si alguien te dice lo contrario en 2025, está atrapado en el 2010.
Cuando el contenido se genera mediante JavaScript, necesitas que el scraper renderice la página completa antes de extraer los datos.
En orden de preferencia, puedes optar por:
- Encontrar la API (la opción más eficiente).
- Usar un renderizador ligero como requests-html.
- Usar herramientas de automatización como Playwright o Puppeteer.
- O bien, usar una plataforma en la nube como Octoparse, que ya maneja todo eso automáticamente.
6. ¿Octoparse permite extraer contenido dinámico o interactivo?
He probado prácticamente todas las herramientas de web scraping del mercado, y aquí va mi opinión honesta:
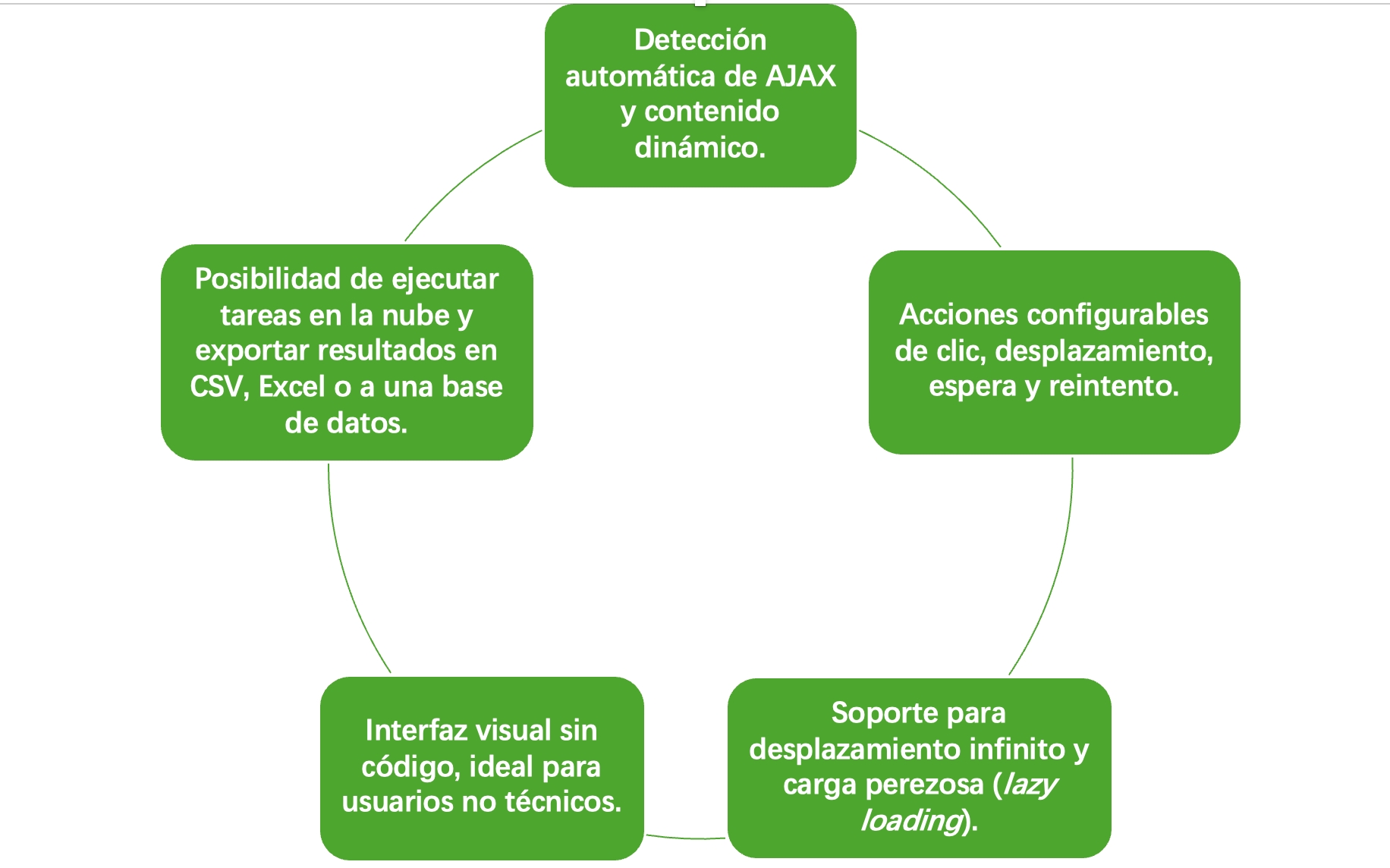
✅ Sí, Octoparse maneja perfectamente el contenido dinámico. Y lo hace muy bien.
Tiene detección de AJAX, flujos de trabajo con paginación, soporte para desplazamiento infinito, automatización de clics y una potente programación de tareas. Más importante aún: está diseñado específicamente para manejar los sitios web cargados de JavaScript y AJAX que suelen causar dolores de cabeza a los scrapers más básicos.
Así es Octoparse gestiona el contenido dinámico:
¿Cómo manejar sitio AJAX y JavaScript sin programar?
A continuación, te muestro cómo hacerlo con Octoparse, sin escribir una sola línea de código.
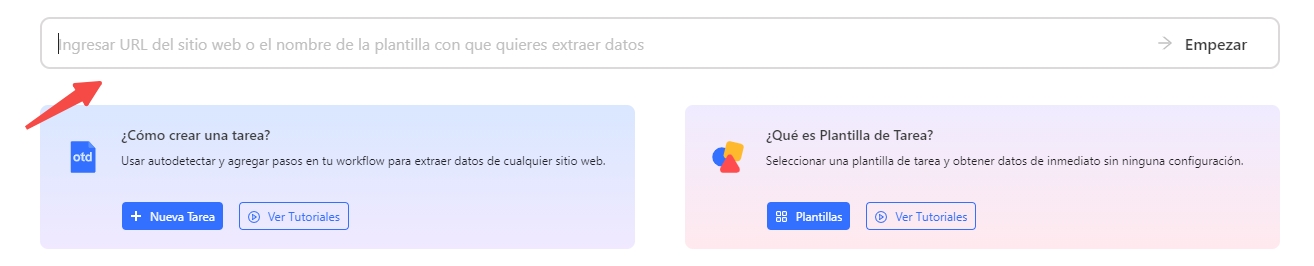
Paso 1: Crear una nueva tarea o ingresar la URL
- Abre Octoparse y crea una nueva tarea pegando la URL del sitio dinámico que quieras extraer.
- El sitio se cargará dentro del navegador integrado de Octoparse, el cual renderiza completamente el contenido JavaScript y AJAX.
Paso 2: Detección automática o selección manual de datos
- Usa la función “Detección automática de datos web” para que Octoparse identifique automáticamente los elementos de datos de la página (nombres de productos, precios, titulares, etc.).
- Si la detección automática no encuentra todo, puedes hacer clic manualmente en los campos de datos que desees extraer.
Paso 3: Activar la carga de más contenido (si es necesario)
Para contenido dinámico detrás de botones de “Cargar más”
- Selecciona el botón “Cargar más”
- Añade una acción de “Hacer clic en elemento” (Click Item) sobre ese botón.
- Configura un bucle para que Octoparse repita los clics hasta que el botón desaparezca o no se cargue más contenido.
- Añade un tiempo de espera AJAX (por ejemplo, de 8 a 15 segundos) después de cada clic para que los datos tengan tiempo de cargarse.
Paso 4: Configurar los tiempos de espera y carga AJAX
Después de los clics o desplazamientos, configura tiempos de espera o selecciona la opción “Esperar hasta que el elemento aparezca” para asegurarte de que Octoparse extrae los datos solo después de que el contenido AJAX haya terminado de cargar. Ajusta los tiempos de espera según la velocidad del sitio.
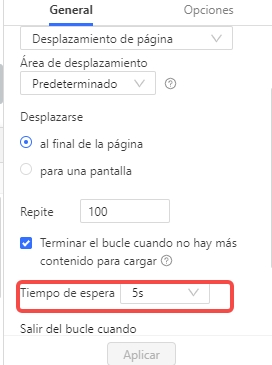
Paso 5: Configurar el bucle de paginación (si aplica)
Si el sitio utiliza paginación con botones “Siguiente” o números de página, selecciónalos. Añade una acción de clic y bucle para navegar entre páginas hasta que se hayan extraído todos los datos.
Paso 6: Vista previa y extracción de datos
Usa el Modo de Vista Previa (Preview Mode) para confirmar que todo el contenido se carga correctamente y que los datos se extraen de forma completa. Ajusta las selecciones, tiempos de espera o bucles si faltan datos o aparecen duplicados.
Paso 7: Ejecutar la tarea y exportar
Ejecuta la tarea localmente o en la nube de Octoparse para obtener velocidad y escalabilidad. Cuando finalice, exporta tu lista completa de datos a CSV, Excel o directamente a tu base de datos.
Conclusión
El web scraping de sitios dinámicos con AJAX y JavaScript puede parecer complicado, pero con las herramientas adecuadas, no lo es. Octoparse elimina la necesidad de programar, ofreciendo una plataforma visual que automatiza clics, desplazamientos, esperas y extracciones.
Si eres desarrollador, Playwright o Puppeteer te darán control total. Pero si buscas velocidad, practicidad y escalabilidad, Octoparse es la solución ideal para empezar a extraer datos en minutos. Pruébalo gratis y comprueba cómo el scraping sin código puede ahorrarte horas (o días) de trabajo manual.

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.