Crear un Simple Web Crawler en PHP
Este artículo es para ilustrar cómo un principiante podría construir un rastreador web (web crawler) simple en PHP. Si planeas aprender PHP y usarlo para el web scraping, sigue los pasos a continuación.
Antes de comenzar, daré un resumen rápido del web scraping. El web scraping es extraer información del HTML de una página web. El web scraping con PHP no hace ninguna diferencia que cualquier otro tipo de lenguajes informáticos o herramientas de web scraping, como Octoparse.
Este artículo es para ilustrar cómo un principiante podría construir un rastreador web (web crawler) simple en PHP. Si planea aprender PHP y usarlo para el web scraping, siga los pasos a continuación.
Paso 1
Agregue un cuadro de entrada y un botón de envío a la página web. Podemos ingresar la dirección de la página web en el cuadro de entrada. Se necesitan expresiones regulares al extraer datos.
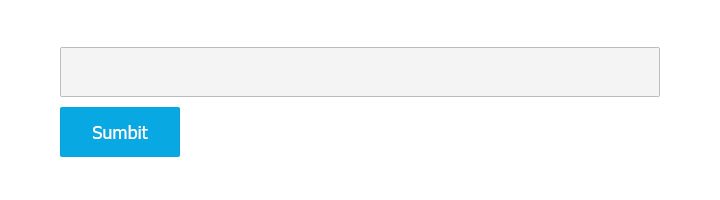
Paso 2
Se necesitan expresiones regulares al extraer datos.
function preg_substr($start, $end, $str) // Regular expression
{
$temp = preg_split($start, $str);
$content = preg_split($end, $temp[1]);
return $content[0];
}
Paso 3
La división de cadenas es necesaria al extraer datos.
function str_substr($start, $end, $str) // string split
{
$temp = explode($start, $str, 2);
$content = explode($end, $temp[1], 2);
return $content[0];
}
Paso 4
Agregue una función para guardar el contenido de la extracción:
function writelog($str)
{
@unlink(“log.txt”);
$open=fopen(“log.txt”,”a” );
fwrite($open,$str);
fclose($open);
}
Cuando el contenido que extraemos es inconsistente con lo que se muestra en el navegador, no pudimos encontrar las expresiones regulares correctas. Aquí podemos abrir el archivo .txt guardado para encontrar la cadena correcta.
function writelog($str)
{
@unlink(“log.txt”);
$open=fopen(“log.txt”,”a” );
fwrite($open,$str);
fclose($open);
}
Paso 5
También sería necesaria una función si necesita capturar imágenes.
function getImage($url, $filename=”, $dirName, $fileType, $type=0)
{
if($url == ”){return false;}
//get the default file name
$defaultFileName = basename($url);
//file type
$suffix = substr(strrchr($url,’.’), 1);
if(!in_array($suffix, $fileType)){
return false;
}
//set the file name
$filename = $filename == ” ? time().rand(0,9).’.’.$suffix : $defaultFileName;
//get remote file resource
if($type){
$ch = curl_init();
$timeout = 5;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$file = curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$file = ob_get_contents();
ob_end_clean();
}
//set file path
$dirName = $dirName.’/’.date(‘Y’, time()).’/’.date(‘m’, time()).’/’.date(‘d’,time()).’/’;
if(!file_exists($dirName)){
mkdir($dirName, 0777, true);
}
//save file
$res = fopen($dirName.$filename,’a’);
fwrite($res,$file);
fclose($res);
return $dirName.$filename;
}
Paso 6
Escribiremos el código para la extracción. Tomemos una página web de Amazon como ejemplo. Ingrese un enlace de producto.
if($_POST[‘URL’]){
//———————example——————-
$str = file_get_contents($_POST[‘URL’]);
$str = mb_convert_encoding($str, ‘utf-8’,’iso-8859-1’);
writelog($str);
//echo $str;
echo(‘Title:’ . Preg_substr(‘/<span id= “btAsinTitle”[^>}*>/’,’/<Vspan>/$str));
echo(‘<br/>’);
$imgurl=str_substr(‘var imageSrc = “’,’”’,$str);
echo ‘<img src=”’.getImage($imgurl,”,’img’ array(‘jpg’));
Entonces podemos ver lo que extraemos. A continuación se muestra la captura de pantalla.

No necesita codificar un rastreador web (web crawler) si tiene un rastreador web automático.
Como se mencionó anteriormente, PHP es solo una herramienta que se utiliza para crear un rastreador web. Los lenguajes de computadora, como Python y JavaScript, también son buenas herramientas para quienes están familiarizados con ellos. Hoy en día, con el desarrollo de la tecnología de web scraping, cada vez surgen más herramientas de web scraping, como Octoparse, Beautiful Soup, Import.io y Parsehub. Simplifican el proceso de creación de un rastreador web (web crawler).
Tome las plantillas de tareas de Octoparse como ejemplo, permite a todos raspar datos usando plantillas preconstruidas, no más configuraciones de rastreadores, simplemente ingrese las palabras clave para buscar y obtener datos al instante.
Posts populares
 Las 7 mejores herramientas de IA gratis para buscar artículos científicos en 2026
Las 7 mejores herramientas de IA gratis para buscar artículos científicos en 2026 Scraping de datos para mejorar estrategias de ventas B2B
Scraping de datos para mejorar estrategias de ventas B2B Las Mejores Herramientas de Seguimiento de Precios en Amazon: Las Probamos Todas
Las Mejores Herramientas de Seguimiento de Precios en Amazon: Las Probamos Todas Cómo extraer reseñas de Google Maps y exportarlas a Excel automáticamente
Cómo extraer reseñas de Google Maps y exportarlas a Excel automáticamente Cómo exportar todos los comentarios de YouTube
Cómo exportar todos los comentarios de YouTube
Explorar temas
Empiece a utilizar Octoparse enseguida
Artículos relacionados

Paulina Tobella
En esteblog se recomiendan los 10 mejores cursos online de big data analytics en 2024 para principiantes, especialmente para aquellos que planean hacer la transición a trabajos de análisis de datos.2024-12-06T00:00:00+00:00 · 8 min
Elena Allende
Este blog trata de si puede y cómo ChatGPT te ayuda a realizar Web Scraping y sus pros y cons comparando con las herramientas de Web Scraping.2023-02-09T00:00:00+00:00 · 5 min Es importante controlar el precio por hora o por día. Octoparse es una gran herramienta gratuita para que pueda extraer datos de cualquier sitio web de comercio electrónico, incluidos Amazon, eBay, Costco, B&H Photo, Frys y muchos más. Puede programar una tarea de raspado para lograr la supervisión de precios en tiempo real. Por último, pero no menos importante, estas estrategias no son mutuamente excluyentes. Funciona mejor cuando aplica estas estrategias por completo.2020-07-01T00:00:00+00:00 · 7 min
Es importante controlar el precio por hora o por día. Octoparse es una gran herramienta gratuita para que pueda extraer datos de cualquier sitio web de comercio electrónico, incluidos Amazon, eBay, Costco, B&H Photo, Frys y muchos más. Puede programar una tarea de raspado para lograr la supervisión de precios en tiempo real. Por último, pero no menos importante, estas estrategias no son mutuamente excluyentes. Funciona mejor cuando aplica estas estrategias por completo.2020-07-01T00:00:00+00:00 · 7 min ¿Qué piensa si te digo que hay un truco que funciona bien y puede obtener miles de clientes potenciales casi al instante? Internet ha cambiado la forma en que hacemos negocios. De hecho, las personas generan 2.5 quintillones de bytes de datos cada día (IBM, 2016) y más de 150 zettabytes (150 trillones de gigabytes) de datos necesitarán análisis para 2025. (Forbes, 2019) Estos números pueden sonar asombrosos, no es difícil creer que desarrollar negocios con datos se haya convertido en la corriente principal de hoy. El web scraping puede ayudarlo fácilmente a lograr miles y decenas de miles de mensajes válidos, ayudándole a encontrar clientes potenciales.2019-12-08T00:00:00+00:00 · 15 min
¿Qué piensa si te digo que hay un truco que funciona bien y puede obtener miles de clientes potenciales casi al instante? Internet ha cambiado la forma en que hacemos negocios. De hecho, las personas generan 2.5 quintillones de bytes de datos cada día (IBM, 2016) y más de 150 zettabytes (150 trillones de gigabytes) de datos necesitarán análisis para 2025. (Forbes, 2019) Estos números pueden sonar asombrosos, no es difícil creer que desarrollar negocios con datos se haya convertido en la corriente principal de hoy. El web scraping puede ayudarlo fácilmente a lograr miles y decenas de miles de mensajes válidos, ayudándole a encontrar clientes potenciales.2019-12-08T00:00:00+00:00 · 15 min