Si estás trabajando en un proyecto que requiere una gran cantidad de datos, el conocimiento de funcionamiento de las herramientas de web scraping es definitivamente una ventaja. Hoy veremos escenarios en los que necesitas extraer datos de varias URLs y cómo puedes hacerlo de una manera fácil.
La necesidad de scraping de Múltiples URLs
Se requiere el scraping de múltiples URLs principalmente en tres escenarios:
- Cuando necesitas recopilar datos que se extienden a lo largo de varias páginas
- Cuando tienes una lista de URLs en mano de las que deseas rastrear datos
- En algunos casos, las personas primero extraerán todas las URLs de las páginas web de las que desean obtener datos y comenzarán a rastrear datos de la lista en el siguiente paso.
Por ejemplo, cuando extraes información de listados de productos de comercio electrónico como Amazon, deberías recorrer varias páginas en una categoría o consulta. Y es muy probable que estas páginas web compartan la misma estructura de página.
Otro ejemplo es cuando necesitas agregar datos de varios sitios web, como noticias o publicaciones financieras. Puedes recopilar todas las URL de estas noticias y artículos para la tarea de raspado más adelante.
Formas de Extraer Datos de Múltiples URLs
- Lenguaje de Programación (Coding)
Si tienes conocimientos de programación, puedes hacer uso de paquetes similares a BeautifulSoup, Scrapy, Selenium disponibles en Python para crear tu propio Scraper de múltiples URLs. Pero la creación de scripts puede resultar intimidante para los que no saben codificar y también aumenta la complejidad incluso para los desarrolladores con diferentes páginas web.
- Herramienta de Web Scraping (Without Coding)
Si no dominas la codificación, las herramientas de web scraping serán más adecuadas y te facilitarán el raspado. Primero, deberás encontrar la herramienta de web scraping adecuada. Hay muchas herramientas en el mercado como Mozenda, Outwit Hub, Scrapinghub, etc. Pero no proporcionan todas las funciones necesarias como plantillas prediseñadas, crawlers ilimitados gratuitos, integración de API, extracción basada en la nube, raspado a gran escala, y no debería ser caro. Por lo tanto, recomendamos Octoparse, un raspador web potente y gratuito que puede extraer datos de cualquier sitio web.
Octoparse ofrece dos soluciones para extraer datos de múltiples URLs que son el Modo de Plantilla y el Modo Avanzado. Ahora veremos ambas soluciones una a una con más detalle.
Extraer datos de varias URLs mediante el Modo de Plantilla de Octoparse
El Scraping en Modo de Plantilla es útil para aquellos que prefieren saltarse el aprendizaje y necesitan extraer datos rápidamente de algunos de los sitios web más populares como Amazon, Instagram, Twitter, YouTube, Booking, TripAdvisor, Yellowpage, Walmart y muchos más.
Seguiremos los pasos necesarios para configurar un raspador web para extraer datos de varias URLs utilizando la plantilla Octoparse.
Paso 1: Selecciona “Plantillas de Tarea” en la pantalla de inicio y elige una plantilla. Selecciona “Pruébala”
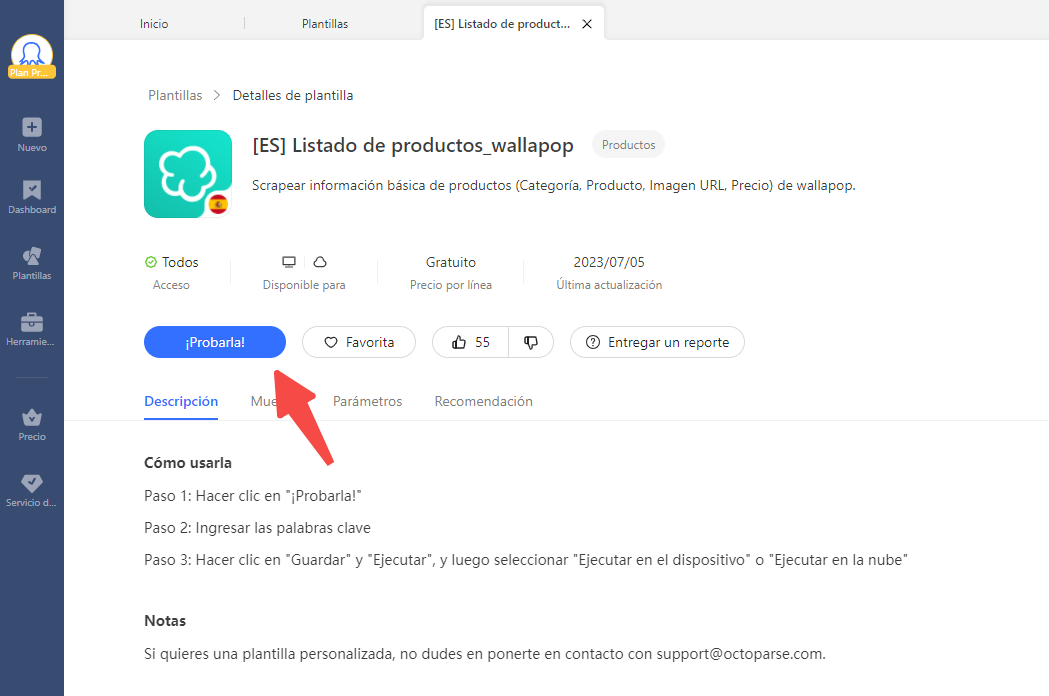
Paso 2: Escribe hasta 3 palabras clave en el campo “palabras clave”
Al usar el modo Plantilla, no es necesario que pongas URLs de 5 páginas si quieres extraer varias URLs, en su lugar, escribe 5 en el campo “Número de páginas”.
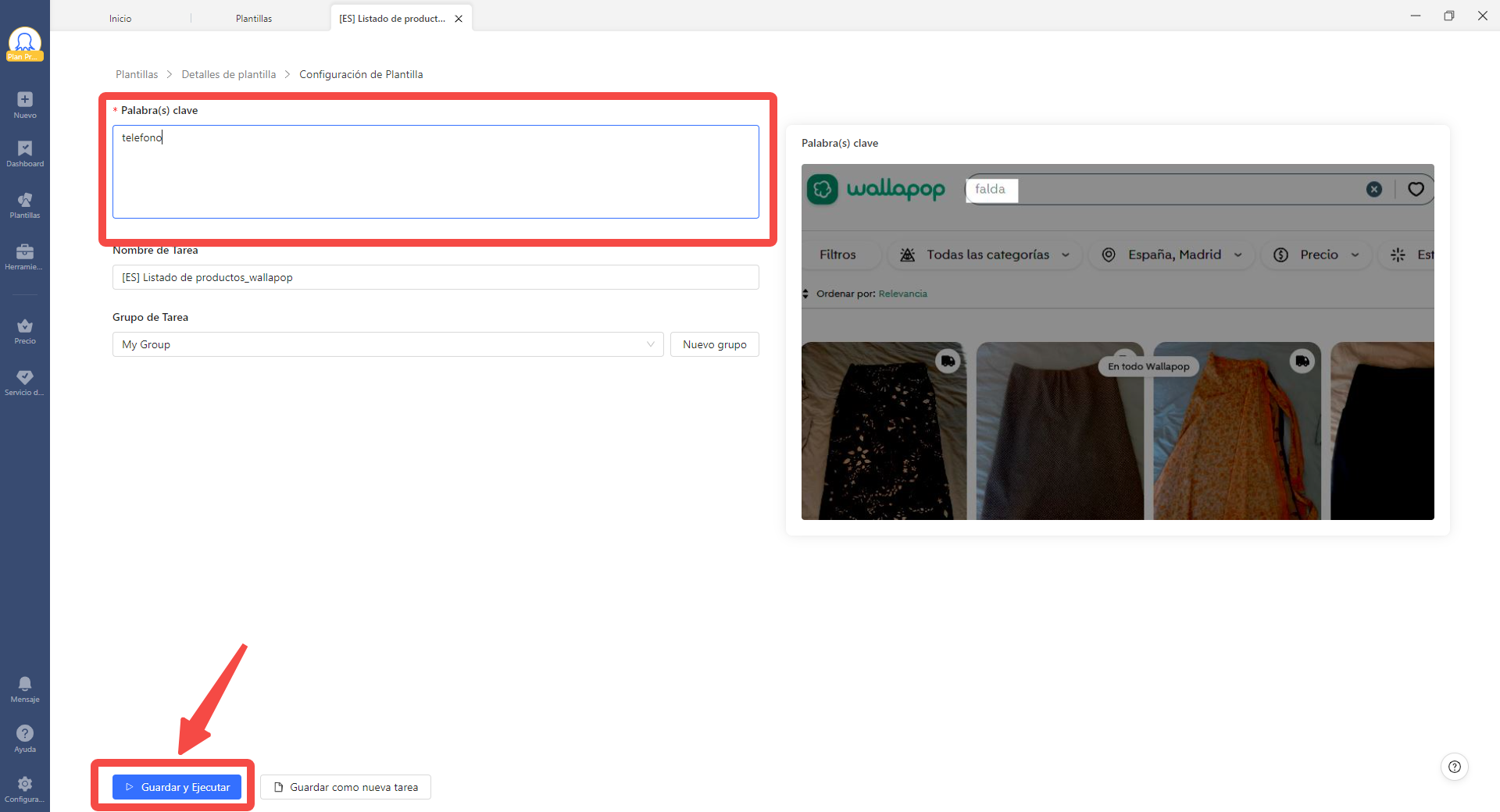
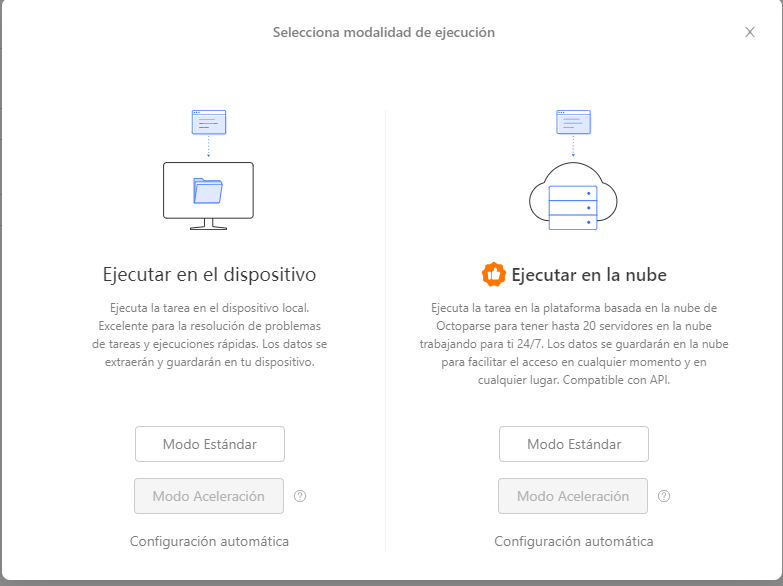
Paso 3: Ahora es el momento de “Guardar y Ejecutar” la tarea en la nube
Octoparse ahora irá y raspará los datos que has seleccionado. Te notificará en el Panel de control cuando haya terminado. Puede descargar tus datos a CSV, Excel, JSON o HTML.
Extraer datos de Múltiples URLs con el Modo Avanzado de Octoparse
El Modo Avanzado tiene más personalización y flexibilidad en comparación con el otro modo. El Modo Avanzado te permite crear un rastreador desde cero para un sitio web más complejo y también tiene una función de detección automática que facilita tu trabajo.
Ahora construimos el crawler usando el modo avanzado con los pasos necesarios.
Paso 1 Haz clic en “+ Nuevo” y selecciona “Modo avanzado” para crear una nueva tarea
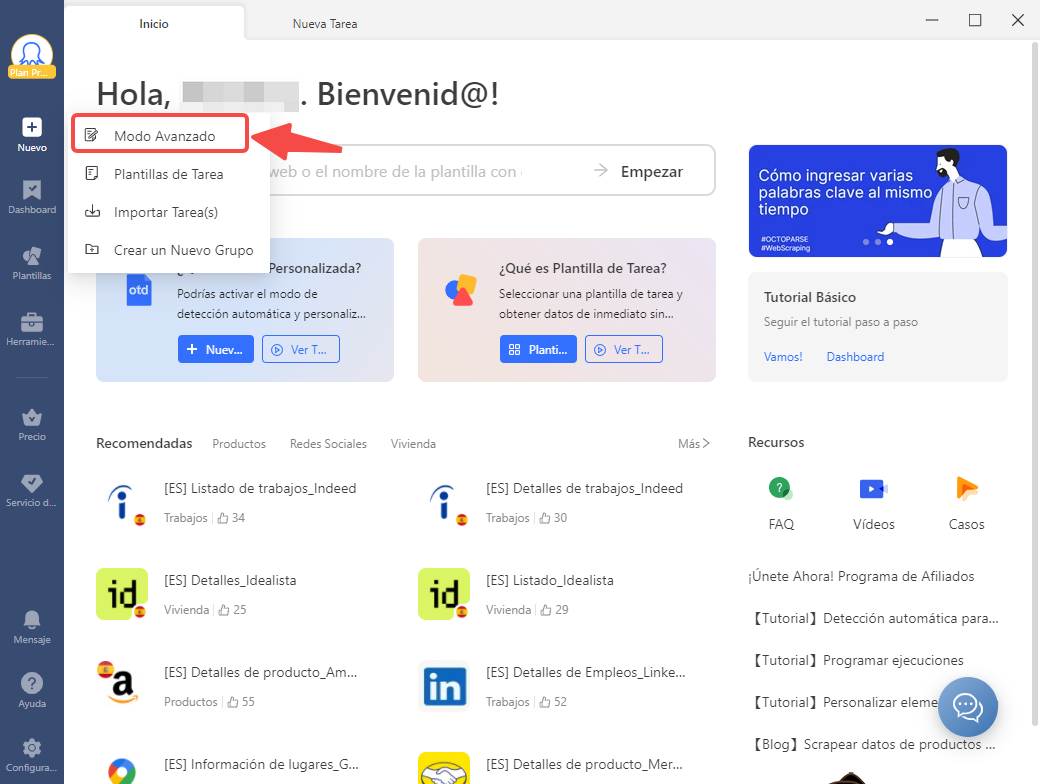
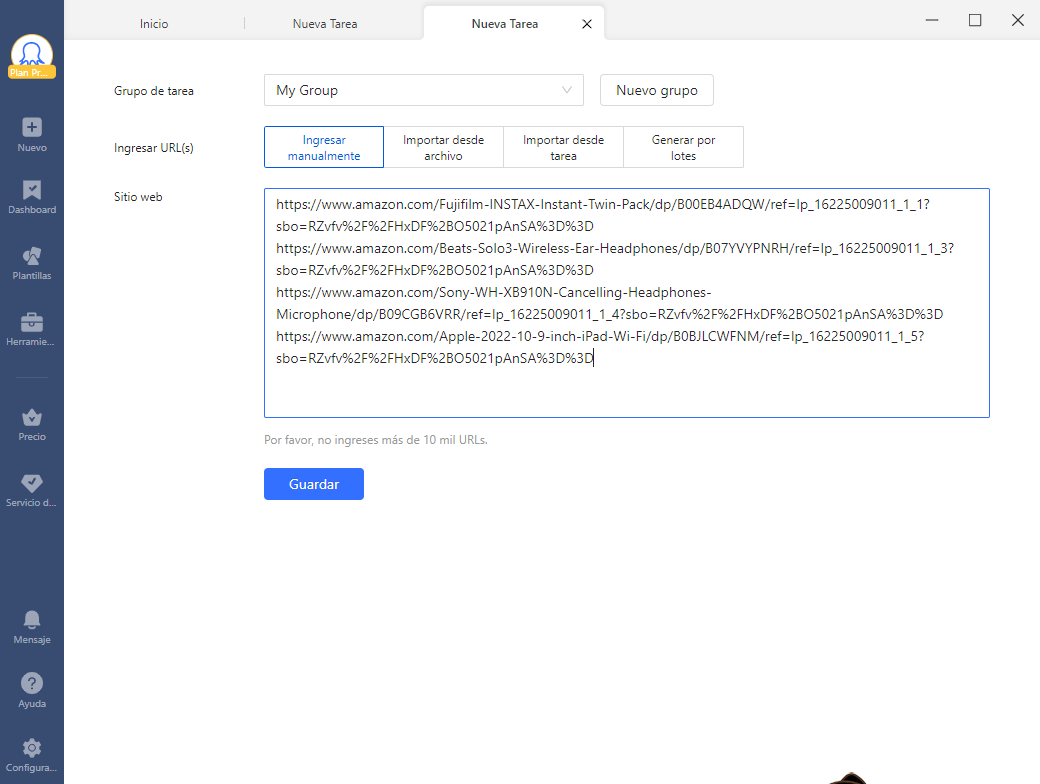
Paso 2 Pega la lista de URLs en el cuadro de texto y haz clic en “Guardar URL”
Paso 3 Después de hacer clic en “Guardar”, las “URL de bucle” (que recorre cada URL de la lista) se crean automáticamente en el flujo de trabajo
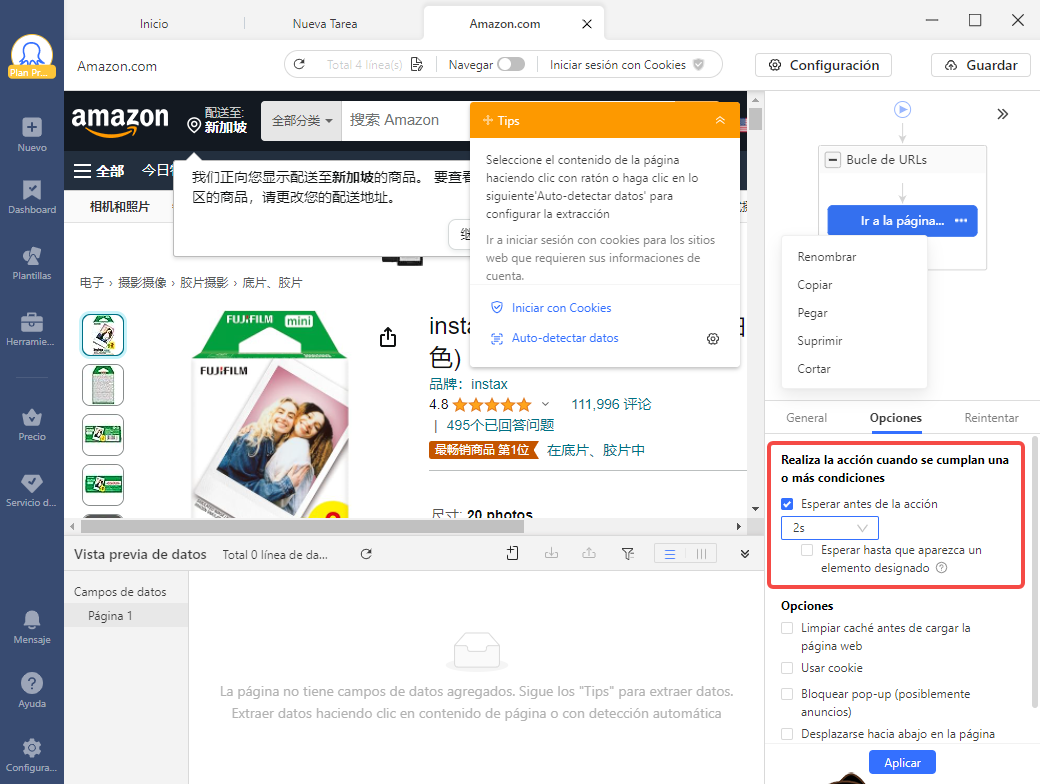
Paso 4. Haz clic en Ir a la Página Web
En “Antes de procesar la página”, establece un tiempo de “esperar antes de la acción” durante 2 segundos para evitar la interrupción de la carga de la página.
Para Terminar
¡Y eso es todo! Ahora sabes cómo extraer datos de varias URLs con Octoparse. Realmente esperamos que este artículo te haya ayudado y no olvides intentar raspar también en otros sitios. Si tienes algún problema, no dudes en ponerte en contacto con el servicio de atención al cliente en el centro de ayuda de Octoparse.



