¿Estás buscando una forma rápida y eficaz de extraer datos valiosos de Reddit? Por ello aquí estamos. Por su gran variedad de temas Reddit se ha convertido en una plataforma líder para recopilar datos sociales debido a su amplia variedad de temas de discusión.
Si eres un investigador social, un profesional de marketing en línea o simplemente alguien que busca datos interesantes, Reddit scraper es la herramienta que necesitas. Con Reddit scraper, podrás extraer fácilmente datos de Reddit en cuestión de minutos. Ya sea que estés buscando información sobre tendencias, estadísticas o patrones de comportamiento, Reddit scraper es la solución ideal para extraer datos precisos y útiles.
En este blog te ofrecemos una variedad de opciones y filtros personalizados para ayudarte a obtener los datos que necesitas de manera más eficiente.
¡Empezamos ahora mismo!
¿Reddit permite el scraping?
Reddit permite usar los datos disponibles públicamente a través de la API oficial de Reddit. Permite a los desarrolladores interactuar con el sitio en una variedad de formas útiles, aunque con varias limitaciones y restricciones.
Para usar la API de Reddit, debes estar autenticado y, para el uso comercial de la API, se necesita una autorización especial. Además, los desarrolladores deberán registrarse y obtener el token para usar la API oficial y eso también, según las reglas establecidas por el sitio.
Incluso puedes usar herramientas de web scraping para extraer datos de Reddit y otros sitios sin preocupaciones, ya que su uso no es ilegal. Solo asegúrate de cumplir con las pautas y las reglas establecidas por el sitio.
El mejor web scraper para Reddit sin codificación
Como se discutió en la parte anterior del tema, el uso de la API oficial de Reddit para el raspado de datos tiene muchas restricciones y el tipo de datos que se pueden extraer también es limitado. Aquí presentaremos un Reddit scraper fácil de usar para ayudarte a scrapear datos de Reddit sin codificar nada.
Octoparse es una herramienta basada en sistemas Windows y Mac para extraer datos automáticamente de sitios web como Reddit. El proceso de extracción de datos es simple y puede obtener rápidamente los datos, incluidos el nombre del grupo, el título, el artículo, el autor, etc.
Además admite la extracción en la nube para poder evitar el bloqueo de IP. También hay una opción para la extracción programada donde se puede establecer un tiempo específico para el raspado de datos. Los datos finales de Reddit raspados se pueden descargar como un archivo de Excel, CSV, JSON, HTML o exportar a Google Sheets o tu base de datos.
Tutorial de extraer datos de Reddit usando Octoparse
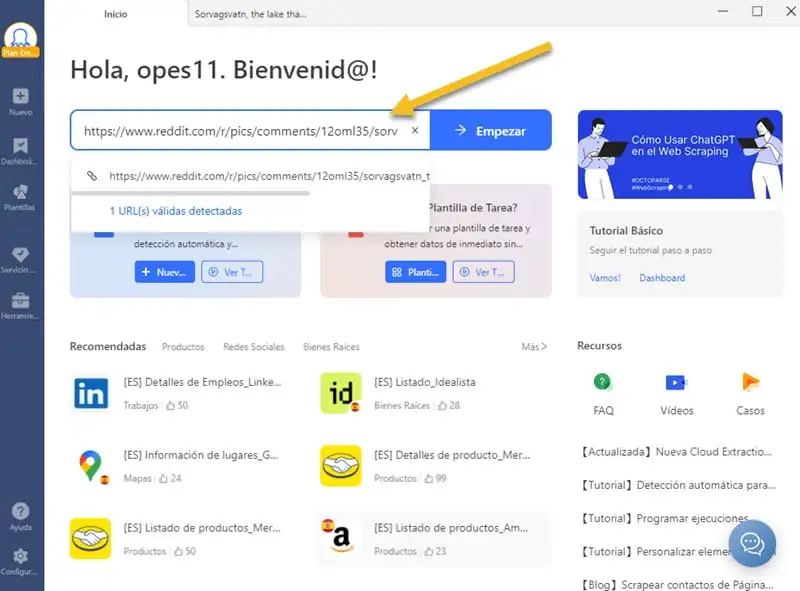
Paso 1: Iniciar Octoparse y pegar enlace de destino de Reddit
Primero, necesitas descargar e iniciar Octoparse. Al entrar en la página de inicio de Octoparse pegamos el enlace de Reddit donde quieres extraer datos y saltamos a la página virtual de raspado haciendo clic en el botón “Empezar”.
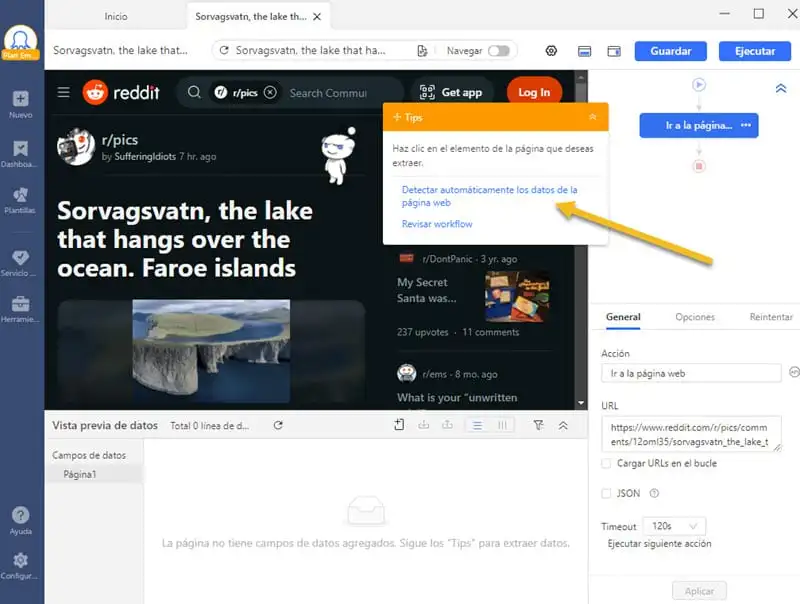
Paso 2: Crear un flujo de trabajo y personalice campos de datos
Podemos ver en el panel naranja de Tips el botón para activar el modo de detección automática. O puedes ir al Modo avanzado para obtener más opciones. A continuación, se creará un flujo de trabajo activando la detección automática. También se pueden realizar opciones personalizadas en el panel de funciones. Por ejemplo, puedes configurar el desplazamiento hacia abajo que te permitirá cargar todos los elementos en una página.
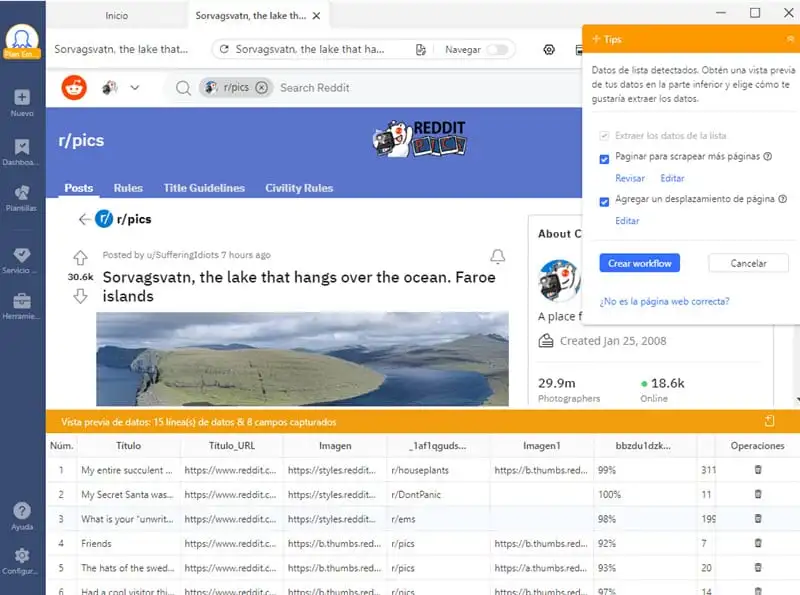
Paso 3: Extraer datos
Una vez completados los pasos anteriores, es el momento de extraer los datos y exportarlos. Hacemos clic en el botón crear workflow y luego ejecutar la tarea para iniciar el proceso de raspado.
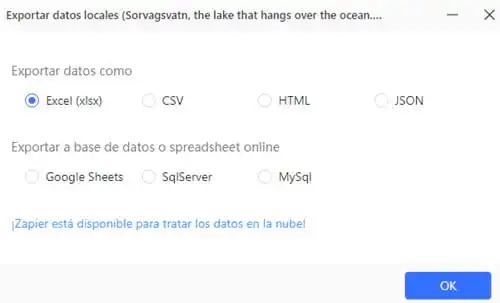
Cuando la tarea termine de correr, puedes descargar los datos a Excel, CSV, JSON, HTML, Google Sheets o tu base de datos.
Extraer datos de Reddit con Python
Si eres bueno con la codificación, entonces otra forma de scraper datos de Reddit es desarrollar tu scraper usando Python, el lenguaje de programación avanzado. También puedes obtener bibliotecas y marcos de trabajo de terceros que ayudan a crear scrapers y web crawlers.
Para scrapear los datos de Reddit usando Python, se usa el módulo PRAW (Python Reddit API Wrapper) que facilita el uso de la API de Reddit usando los scripts de Python.
¿Cómo extraer datos con Python?
Paso 1. En primer lugar, deberías instalar PRAW y, para ello, debes primero ejecutar la línea de comando pip install praw en el símbolo del sistema.
Paso 2. A continuación, para la extracción de datos, se debe crear una aplicación Reddit. Elija la opción de ser desarrollador y crear una aplicación.
Paso 3. Después de crear la aplicación, se deben crear instancias de gambas que son de 2 tipos: instancia de solo lectura e instancia autorizada.
Paso 4. Dependiendo del tipo de datos a extraer, se dará el comando. A medida que se procesa el comando, se realizará la extracción de datos.
Puede ir a la página aquí para obtener más detalles: Scraping Reddit using Python.
Conclusión
Creemos que el scraping de datos de Reddit seguramente te ayudará a recopilar información para tu negocio. Un Reddit scraper eficiente asegura que todos los datos necesarios se pueden extraer de manera fácil y segura. Espero que el contenido de este blog te sea útil para encontrar una forma rápida y eficaz de extraer datos de Reddit.