En este artículo, quiero compartir contigo cómo rastrear Twitter a través de un rastreador o con la API y manejar los datos para el análisis de sentimientos.
Cómo Recopilar Datos de Twitter
Cuando hablamos de Análisis de Sentimientos, lo primero que nos viene a la mente es dónde y cómo podemos extraer los datos.
Tomemos como ejemplo uno de los sitios web de redes sociales más populares, Twitter. Hay varios métodos con los que podemos descargar datos de Twitter – Crear un rastreador web mediante programación o elegir una herramienta de extracción de datos automatizada, como Octoparse, Import.io, etc. También podemos utilizar las API públicas proporcionadas por ciertos sitios web para obtener acceso a su conjunto de datos.
Extraer los datos con herramienta de web scraping
Es posible que la API no sea familiar para todos y podría ser complicada para alguien sin conocimientos de codificación. Para eso, me gustaría recomendarte herramientas de rastreador web automatizadas que pueden ayudarte a rastrear sitios web sin conocimientos de codificación, como Octoparse, que proporciona a los usuarios oportunidades de descargar datos sin costos.
Para facilitarles a los usuarios en sacar los datos de Twitter que quieran, el equipo de Octoparse prediseñó un grupo de plantillas. Si quieres extraer tweets, números de seguidores, likes e imágenes de Twitter, podrías encontrar las correspondientes en Octoparse.
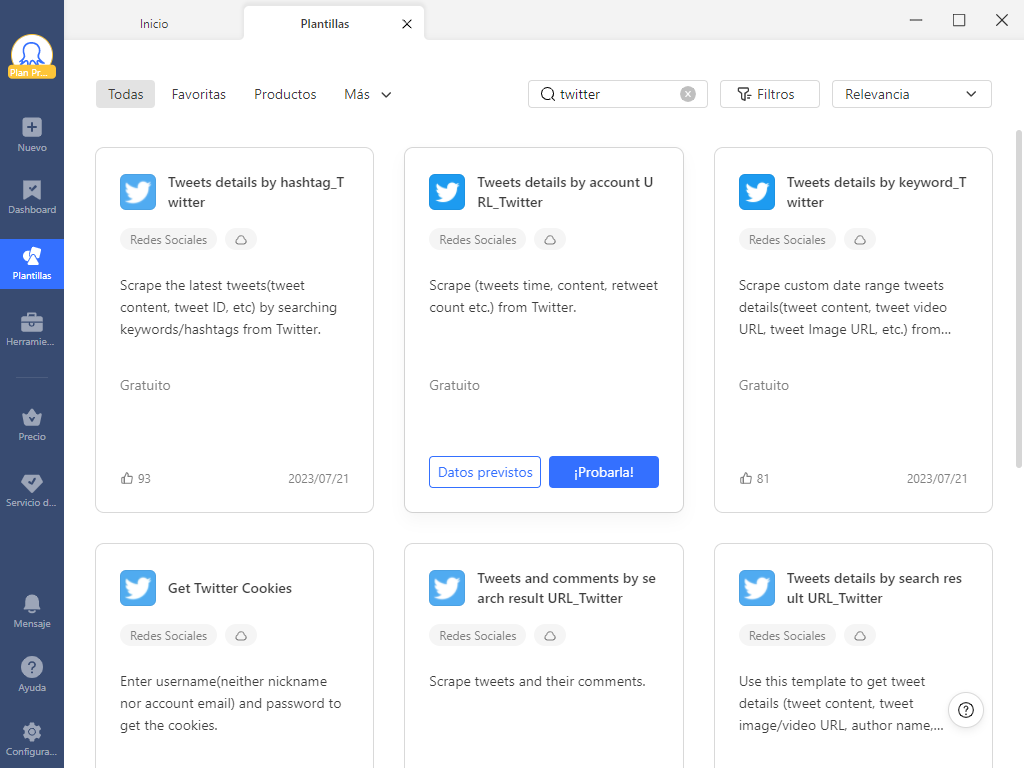
Tras seleccionar la plantilla que más convenga a tus requisitos de datos, lo único que tendrás que hacer es ingresar las URL o de los sitios web o palabras clave y Octoparse scrapeará y exportará por ti los datos extraídos a Excel, CSV, HTML, o los transmitirá a tu base de datos en tiempo real a través de las API de Octoparse.
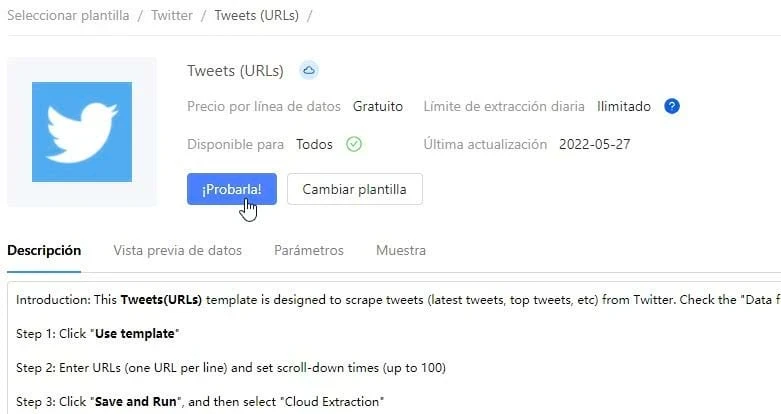
También puedes configurar tu propio crawler de Twitter haciendo solo clics en el web scraper software si necesitas personalizar los datos por extraer. Los pasos detallados podrías ver en Cómo Extraer Datos de Twitter | Descargar a Excel o contactar con el equipo de soporte(support@octoparse.com) para empezar tus proyectos de datos de Twitter con Octoparse.
Extraer los datos con API
Se sabe que Twitter proporciona API públicas para que los desarrolladores lean y escriban tweets cómodamente. La API REST identifica las aplicaciones y los usuarios de Twitter utilizando OAuth. Por lo tanto, podemos utilizar las API REST de Twitter para obtener los tweets más recientes y populares.
Twitter proporciona la API REST de Twitter para scrapear datos. Los datos de Twitter se pueden scrapear según un intervalo de tiempo específico, una ubicación u otros campos de datos. Los datos rastreados se devolverán en formato JSON. Ten en cuenta que los desarrolladores de aplicaciones deben generar cuentas de aplicaciones de Twitter para obtener el acceso autorizado a la API de Twitter.
Mediante el uso de un específico Token de Acceso, la aplicación realizará una solicitud al POST OAuth2 para intercambiar credenciales para que los usuarios puedan obtener acceso autenticado a la API REST. Este mecanismo nos permite extraer información de los usuarios del recurso de datos. Luego, podemos usar la función de búsqueda para rastrear estos tweets estructurados relacionados con temas universitarios.
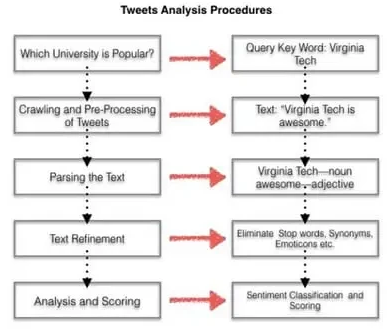
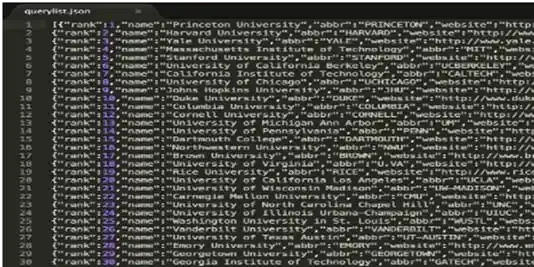
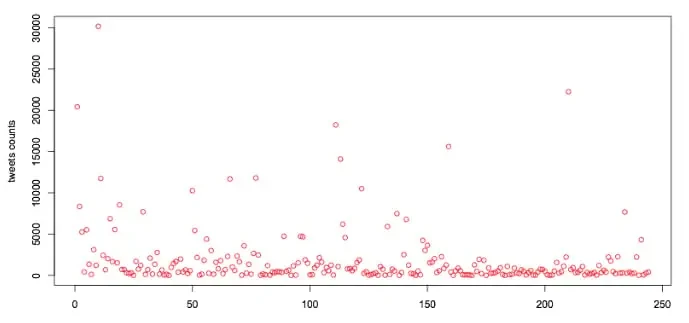
Luego, generará un conjunto de consultas para rastrear tweets, que se muestra en la siguiente figura. Recopilamos datos del ranking universitario de USNews 2016, que incluye 244 universidades y sus rankings. Luego, personalizamos los campos de datos que se necesita usar para rastrear tweets en formato JSON.

En este caso, hemos extraído 462,413 tweets en total. El número de tweets de la mayoría de las universidades rastreados es inferior a 2000.
Twitter Análisis de Sentimiento
Volvamos al Ranking Universitario de mi aplicación diseñada. La tecnología de clasificación en mi aplicación es analizar los tweets rastreados de Twitter y luego clasificar los tweets relacionados de acuerdo con su relevancia para una universidad específica. Podemos filtrar los tweets altamente relacionados (topK) para hacer el Análisis de sentimiento, lo que evitará tweets triviales que hacen que nuestros resultados sean inexactos.
Puedes clasificarlos según la similitud de TF-IDF, el resumen de texto, los factores espaciales y temporales, o puede elegir el método de clasificación de aprendizaje automático. Incluso Twitter proporciona un método basado en el tiempo o la popularidad. Sin embargo, necesitamos un método más avanzado que pueda filtrar la mayor parte del spam y los tweets triviales.
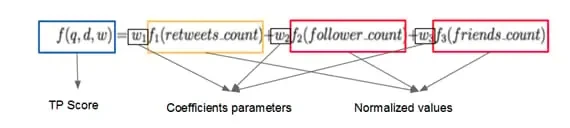
Para medir la confianza y la popularidad de un tweet, utilizaremos las siguientes funciones de los tweets: número de retweets, número de seguidores y número de amigos. Suponiendo que un usuario de confianza debe publicar un tweet de confianza. Como un usuario de confianza debe tener suficientes amigos y seguidores, un tweet popular debería tener un alto número de retweets.
Vamos a construir un modelo que combina confianza y popularidad (TP Score) para un tweet. Luego clasificamos esos tweets según la puntuación TP. Ten en cuenta que las noticias de informes suelen tener una gran cantidad de retweet, y este tipo de puntuación será inútil para nuestro Análisis de Sentimiento.
Por lo tanto, asignaremos un peso relativamente menor a esta parte al calcular la puntuación TP. La fórmula diseñada se muestra a continuación. Los tweets que rastreamos se filtran por palabras de consulta y tiempo de publicación. Todo lo que necesitamos es considerar el número de retweets, el número de seguidores y el número de amigos.
Hemos hecho el ranking universitario de acuerdo con la reputación pública que está representada por la puntuación de sentimiento. Sin embargo, la reputación pública es solo uno de los factores que deben tenerse en cuenta al evaluar una universidad. Por lo tanto, quiero presentar una clasificación general que combina tanto la clasificación comercial como nuestra clasificación.
Hay tres tipos principales de textos de tweets:

Puntuación de Sentimiento: la Puntuación de Sentimiento se calcula para la reputación pública. La tasa positiva de cada universidad se utiliza como puntaje de sentimiento para el ranking de reputación pública. La siguiente fórmula define la tasa positiva. Deberíamos tener en cuenta que la polaridad negativa no se considera ya que es igual a cero.
Después de completar el Análisis de Sentimiento, procedería a crear un clasificador para el Análisis de Sentimiento utilizando un algoritmo de aprendizaje automático. Hablaré del clasificador de Máxima Entropía más adelante en otro artículo.



