Como novato, construí un web crawler y extraje con éxito 20k datos de Amazon. ¿Quiere saber cómo hacer un web crawler y crear una base de datos que eventualmente se convierta en su activo sin costo alguno? Este artículo compartirá paso a paso con usted las diferentes formas, incluidas la codificación y la sin codificación.
¿Qué es web crawler?
Un web crawler, o sea araña web, es un bot de Internet que indexa el contenido de los sitios web de forma metódica y automatizada. Puede extraer automáticamente información y datos de destino de sitios web y exportar datos a formatos estructurados (lista/tabla/base de datos). Aquí dejo un video que explica el web crawler y la diferencia entre web crawlers y web scrapers.
Puede que tenga curiosidad acerca de si el web crawler es legal o no, bueno, depende. Pero, en términos generales, es totalmente legal en la mayoría de los países rastrear los datos públicos de un sitio web.
¿Por qué necesita un web crawler?
Imagine un mundo sin Google. ¿Cuánto tiempo cree que tomará obtener una receta vegetariana por Internet? Cada día se crean en línea 2,5 quintillones de bytes de datos. Sin motores de búsqueda como Google, será como buscar una aguja en un pajar.
De Hackernoon por Ethan Jarrell
Un motor de búsqueda es un tipo único de web crawler que indexa sitios web y busca páginas web para nosotros. Además de los buscadores, también puede crear un web crawler personalizado para lograr:
- Agregación de contenido: Funciona para compilar información sobre temas de diferentes fuentes en una sola plataforma. Como tal, es necesario rastrear sitios web populares para alimentar su plataforma a tiempo.
- Análisis de sentimiento: Conocido como minería de opinión, es el proceso para analizar las actitudes del público hacia un producto o servicio. Requiere un conjunto monótono de datos para evaluarlos con precisión. Un web crawler puede extraer tweets, opiniones y comentarios para su análisis.
- Lead generation: También se le llama Generación de prospectos. Cualquier negocio necesita prospectos de ventas. Así es como sobreviven y prosperan. Supongamos que planea realizar una campaña de marketing dirigida a una industria específica. Puede extraer el correo electrónico, el número de teléfono y los perfiles públicos de una lista de expositores o asistentes a ferias comerciales, como los asistentes a Expo Dubai 2020.
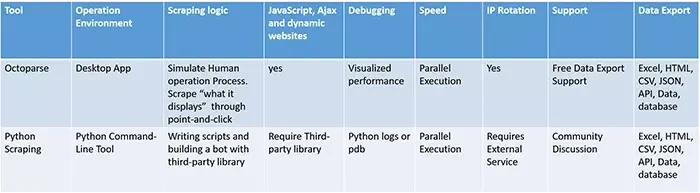
Cómo se construye un web crawler con codificación
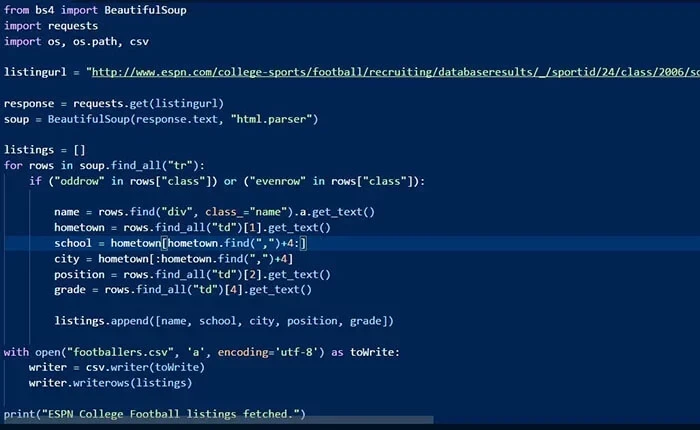
Los programadores utilizan predominantemente scripts con lenguajes informáticos. Puede ser tan poderoso como creas que sea. Este es un ejemplo de un fragmento de códigos de bot.
De Kashif Aziz
3 pasos para construir un web crawler usando Python
Paso 1: envíar una solicitud HTTP a la URL de la página web y responder a su solicitud devolviéndole el contenido de las páginas web.
Paso 2: analizar la página web. Un analizador creará una estructura de árbol del HTML a medida que las páginas web se entrelazan y anidan juntas. Una estructura de árbol ayudará al bot a seguir las rutas que creamos y navegar para obtener la información.
Paso 3: usar la biblioteca de Python para la búsqueda en el árbol de análisis.
Entre los lenguajes informáticos para un web crawler, Python es fácil de implementar en comparación con PHP y Java. Aun así, todavía tiene una curva de aprendizaje empinada que impide que muchos que no son programadores la usen. A pesar de que es una solución económica escribir códigos, todavía no es sostenible con respecto al ciclo de aprendizaje extendido dentro de un marco de tiempo limitado.
Herramienta de web crawler sin codificación gratis
Si no desea aprender a codificar, puede intentar usar las herramientas de web crawler disponibles en el mercado. Aquí recomendamos Octoparse, que es una herramienta de extracción de datos gratuita y no les requiere conocimientos de codificación a los usuarios. Apoya en sus dispositivos Windows/Mac y los datos se pueden exportar en formatos como Excel, CVS, HTML, Json o a su base de datos.
Cómo se crea un web crawler gratis con Octoparse sin codificación
Paso 1. Abra Octoparse y pegue la URL de destino en la página de inicio y después podrías activar modo de la detección automática. O puede seleccionar el Modo avanzado para probar opciones más personalizadas.
Paso 2. Puede obtener una vista previa de los datos detectados y haciendo clic en el flujo de trabajo podría modificar el rastreador. Puede personalizar el campo de datos según lo necesite haciendo clic en la posición de los datos de destino con las sugerencias. Octoparse admite la configuración de la paginación haciendo clic en el botón “Página siguiente” para que el crawler pueda navegar por ella.
Paso 3. Una vez que termine de configurar los campos de extracción, haga clic en el botón “Ejecutar” para ejecutar el rastreador. Puede descargar los datos a sus dispositivos locales o base de datos.
Si aún tiene preguntas, podrías ir al centro de ayuda para configurar paso a paso su crawler consultando los tutoriales. Octoparse también proporciona más de 300 plantillas que cubren las necesidades de extraer datos desde sitios web populares para facilitar a lo máximo la construcción de crawler para los principiantes. Estas plantillas permiten a los usuarios capturar los datos con solo ingresar URLs o palabras clave.
Conclusión
Escribir scripts puede ser fastidioso ya que tiene altos costos iniciales y de mantenimiento ya que necesitaremos escribir cada vez un script específico para cada sitio y tendríamos que ajustar el crawler con frecuencia cuando los sitios web cambien de estructura. Una herramienta de web crawler como Octoparse es más práctica para la extracción de datos a nivel empresarial con menos esfuerzos y costos más bajos.