El Web scraping (o raspado web ) es una técnica a través de web scraper para recopilar datos de una página web y ayudarte a realizar análisis de datos. Con el web scraping puedes convertir datos no estructurados en datos estructurados que pueden almacenarse en tu computadora local o en base de datos.
Para recopilar datos, en general se puede pasar por estas 9 instrumentos:
- Obersavación
- Cuestionarios o encuestas
- Focus group
- Entrevistas
- Formularios de contacto
- Fuentes abiertas
- Monitoreo de redes sociales
- Análisis del sitio web e historial de conversaciones
Si quieres recolectar al mismo tiempo millones de datos con esas técnicas, pues el web scraping será la herramienta para organizarlos y descargar automáticamente y en poco tiempo.
Puede ser difícil crear un web scraper para personas que no saben nada de la codificación. Afortunadamente, hay herramientas de web scraping disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 softwares de Web Scraping más populares y gratis, desde bibliotecas de código abierto hasta extensiones de navegador y webs scrapers de escritorio.
¿Por qué es necesario hacer el Web Scraping?
El web scraping se puede aplicar en una variedad de contextos donde se necesite recopilar información de la web de manera automatizada. ¿Y dónde se puede aplicar el web scraping? Algunos ejemplos de áreas donde se utiliza el web scraping son:
- Análisis de datos: el web scraping se puede utilizar para recopilar grandes cantidades de datos de la web, que luego se pueden analizar para obtener información valiosa.
- Investigación de mercado: el web scraping se puede utilizar para recopilar datos sobre productos, precios y tendencias en la web para ayudar a las empresas a tomar decisiones informadas sobre su estrategia de mercado.
- Monitorización de la marca: el web scraping se puede utilizar para monitorear la presencia en línea de una marca, incluyendo su reputación y menciones en la web.
- Generación de contenido: el web scraping se puede utilizar para recopilar información y estadísticas relevantes para la creación de contenido en la web, como artículos de noticias, blogs y contenido de redes sociales.
- Automatización de tareas: el web scraping se puede utilizar para automatizar tareas que requieren la recopilación de información de múltiples fuentes en la web, como la generación de informes y el seguimiento de precios
¿Puedo usar el web scraping si no sé codificación?
Aunque el web scraping se basa en el código para automatizar la extracción de datos de la web, hay herramientas y servicios disponibles que no requieren que el usuario tenga conocimientos de programación. Por ejemplo, herramientas de web scraping que ofrecen una interfaz gráfica de usuario para que el usuario pueda seleccionar los elementos que desea extraer de una página web y generar código automáticamente en el fondo. O extensiones de navegador y servicios de web scraping en línea.
A continuación, le enseñaremos 30 mejores herramientas de web scraping y sus características y defectos. Puede elegir la que más se ajuste a sus necesidades de datos.
30 Mejores Softwares Gratuitos de Web Scraping Recomendados
1. Octoparse
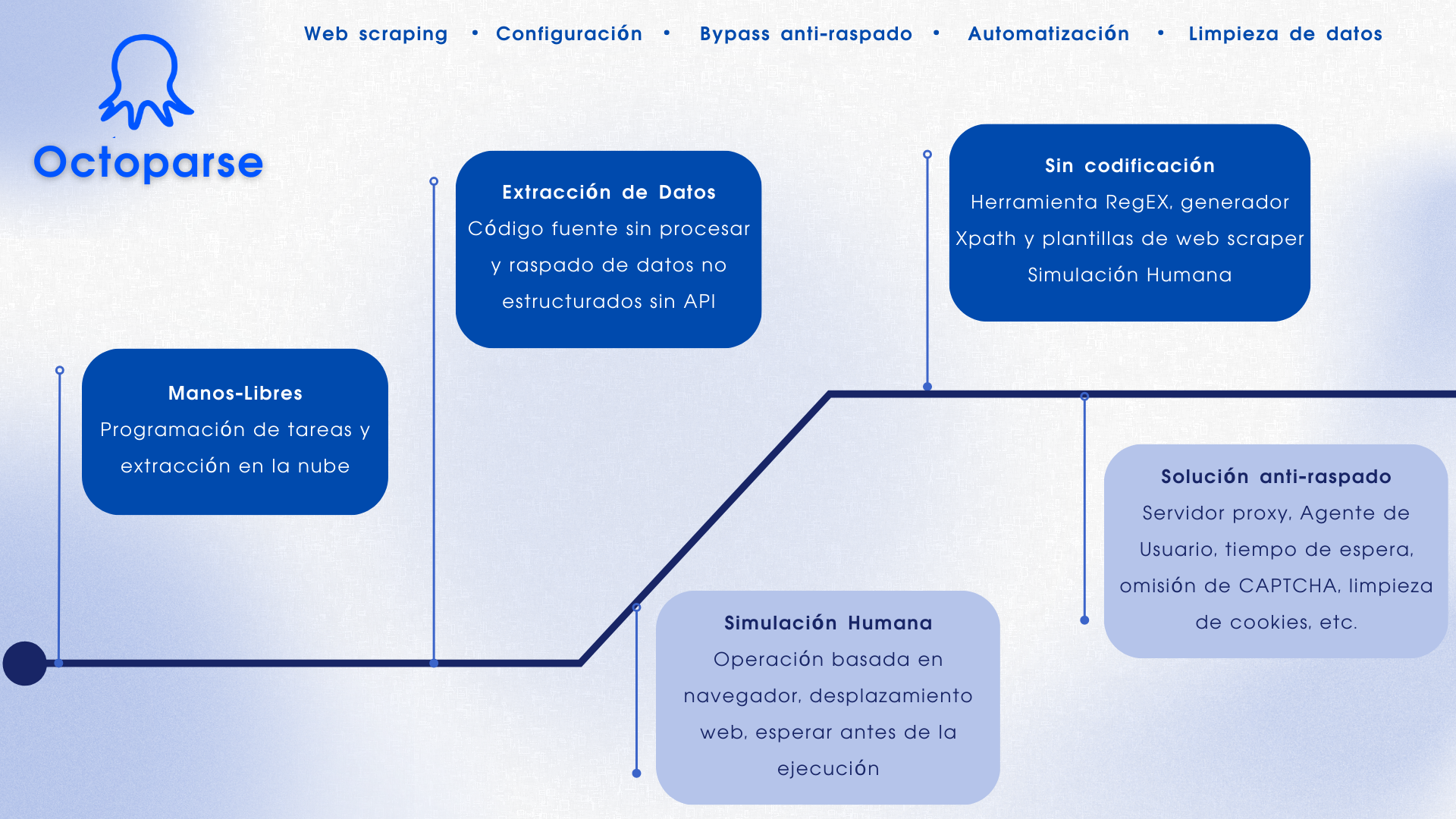
Para quién sirve: Las empresas o las personas tienen la necesidad de realizar el web scraping de estos sitios web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. y los usuarios que no son programadores ya que este software de Web Scraping no requiere habilidades de programación y codificación.
Por qué deberías usarlo: Octoparse es una herramienta de web scraping gratis para recopilar datos de una página web sin escribir códigos. Puedes usar sus plantillas gratuitas o pagas para capturar datos web y estructurar datos automáticamente con solamente hacer clics e ingresar URLs. Más de 300 plantillas prediseñadas cubren la mayoría de las necesidades de datos de los sitios web más populares internacionales, como Amazon, Idealista, Booking, LinkedIn, Mercadolibre y muchas otras.
Octoparse también proporciona el modo avanzado y la detección automática para facilitarles a los usuarios el proceso de personalizar el web scraper y sus datos. Puedes editar tu scraper según tus necesidades de web scraping.
| PROS | CONS |
| – Interfaz limpia y fácil de usar para descargar datos e imágenes por lotes – Su plan gratuito puede cubrir la mayoría de necesidades de web scraping – Sin necesidad de conocimientos sobre la codificación ni habilidades en la programación y el web scraping – Se ajusta a la mayoría de sitios web y los requisitos de extracción de datos de página web – Más de 300 plantillas de tareas que permiten a los usuarios recopilar datos con solo clics y URLs – Extracción en las nubes para descargar datos 24/7 sin necesitar quedarse frente a la computadora – Detección automática de datos con web scrapers auto-creados – Rotación de IPs para evitar el bloqueo de sitios web y la resolución automática de CAPTCHAs – Se puede guardar cookies sin necesitar iniciar sesión manualmente cada vez que se ejecute la tarea | Octoparse aún no proporciona el servicio de descargar vídeos |
2. Beautiful Soup

Para quién sirve: desarrolladores que dominan la programación para crear un web crawler / web scraper
Por qué deberías usarlo: Beautiful Soup es una biblioteca de Python de código abierto diseñada para hacer web scraping de archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tienes habilidades de programación, funciona mejor cuando combinas esta biblioteca con Python durante el proceso de web scraping.
Esta tabla resume las ventajas y desventajas de cada parser:
| Parser | Uso estándar | Ventajas | Desventajas |
| html.parser (puro) | BeautifulSoup(markup, “html.parser”) |
| No es tan rápido como lxml, es menos permisivo que html5lib. |
| HTML (lxml) | BeautifulSoup(markup, “lxml”) |
| Dependencia externa de C |
| XML (lxml) | BeautifulSoup(markup, “lxml-xml”) BeautifulSoup(markup, “xml”) |
| Dependencia externa de C |
| html5lib | BeautifulSoup(markup, “html5lib”) |
|
|
3. Import.io

Para quién sirve: Empresas que busca una solución de integración en el web scraping de datos
Por qué deberías usarlo: Import.io es una plataforma de recopilación de datos popular en la industria de web scraping. Proporciona un software de web scraping que te permite extraer datos de una web y organizarlos en conjuntos de datos. Puede integrar los datos de una web en herramientas analíticas para ventas y marketing obteniendo información.
| PROS | CONS |
| – Permite el web scraping en colaboración con equipo – Eficaz y preciso cuando se trata de extraer datos de largas listas de URL – Scrapear páginas y raspar según los patrones que especificas a través de ejemplos | – Es necesario reintroducir una aplicación de escritorio, ya que se basa en la nube – Se requiere tiempo para aprender los pasos de usar esta herramienta de web scraping |
4. Mozenda

Para quién sirve: Empresas y negocios que hay necesidades de recopilar datos fluctuantes / datos en tiempo real
Por qué deberías usarlo: Mozenda proporciona una herramienta de web scraping que facilita la extracción de datos capturando el contenido de la web. También proporciona servicios de visualización de datos, lo que evita la necesidad de contratar a un analista de datos.
| PROS | CONS |
| – Creación dinámica de agentes – Interfaz gráfica de usuario limpia para el diseño de agentes – Excelente soporte al cliente cuando sea necesario | – La interfaz de usuario para la gestión de agentes se puede mejorar – Cuando los sitios web cambian, los agentes podrían mejorar en la actualización dinámica – Solo adapta el sistema Windows |
5. Parsehub

Para quién sirve: analistas de datos, comercializadores e investigadores que carecen de habilidades de programación
Por qué deberías usarlo: ParseHub es un software visual de web scraping que puedes usar para recopilar datos de la web. Puedes extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar tu dirección IP cuando se encuentre con sitios web con técnicas anti-scraping.
| PROS | CONS |
| Tener un excelente boarding que te ayude a comprender el flujo de trabajo y los conceptos dentro de las herramientas de web scraping Plataforma cruzada, para Windows, Mac y Linux No requiere conocimientos básicos de programación para comenzar Atención al cliente de alta calidad | No se pueden importar / exportar las plantillas Tener solamente una integración limitada de javascript / regex |
6. Crawlmonster

Para quién sirve: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software de web scraping gratis. Te permite recopilar datos escaneando sitios web y analizando el contenido de tu sitio web, el código fuente, el estado de la página y muchos otros.
| PROS | CONS |
| – Facilidad de usoAtención al cliente – Resumen y publicación de datos – Escanear el sitio web en busca de todo tipo de puntos de datos | Las funcionalidades no son completas |
7. DataShake

Para quién sirve: Personas que tienen conocimientos de programación y desean obtener datos por API
Por qué deberías usarlo: Datashake puede utilizarse para comprender mejor a su base de clientes, obtener información profunda a partir de una gran cantidad de datos o simplemente para crear algo nuevo.
8. Common Crawl
Para quién sirve: Investigadores, estudiantes y profesores
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
Common Crawl es una organización sin fines de lucro 501(c)(3) que rastrea la web y proporciona libremente sus archivos y conjuntos de datos al público.
9. Crawly
Para quién sirve: Personas con requisitos de datos básicos pero sin hababilidad de codificación
Por qué deberías usarlo: Crawly proporciona un servicio automático que realiza el web scraping de un sitio web y recopila datos en formato estructurado como JSON o CSV. Puede extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
Características
- Análisis de demanda
- Investigación de fuentes de datos
- Informe de resultados
- Personalización del robot
- Seguridad, LGPD y soporte
10. Content Grabber
Para quién sirve: Desarrolladores de Python que son expertos en programación
Por qué deberías usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es flexible en el manejo de sitios web complejos y extracción de datos.
| PROS | CONS |
| – Fácil de usar y no requiere habilidades especiales de programación – Capaz de raspar sitios web de datos específicos en minutos – Debugging avanzado Ideal para extraer datos de bajo volumen de sitios web | – No se pueden realizar varias tareas de web scraping al mismo tiempo – Falta de soporte y atención al cliente |
11. Diffbot
Para quién sirve: Desarrolladores y empresas
Por qué deberías usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para recolectar datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
| PROS | CONS |
| – Información precisa actualizada – API confiable – Integración de Diffbot | La salida inicial fue en general bastante complicada, lo que requirió mucha limpieza antes de ser utilizable |
12. Dexi.io

Para quién sirve: Personas con habilidades de programación y codificación
Por qué deberías usarlo: Dexi.io es un web spider basado en navegador. Proporciona tres tipos de robots para recopilar datos: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite varios servicios de terceros (resolver captcha, almacenar en la nube, etc.) que puede integrar fácilmente en sus robots.
| PROS | CONS |
| – Fácil de empezar – El editor visual hace que la automatización de la web sea accesible para las personas que no están familiarizadas con la codificación Integración con Amazon S3 | – La página de ayuda y soporte del sitio no cubre todas las necesidades – Carece de alguna funcionalidad avanzada |
13. DataScraping.co
Para quién sirve: Analistas de datos, comercializadores e investigadores que carecen de habilidades de programación
Por qué deberías usarlo: Data Scraping Studio es un software de web scraping gratis para recolectar datos de páginas web, HTML, XML y pdf.
PROS
Una variedad de plataformas, incluidas en línea / basadas en la web, Windows, SaaS, Mac y Linux.
14. Easy Web Extract

Para quién sirve: comerciantes con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación
Por qué deberías usarlo: Easy Web Extract es un software de web scraping para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
Características
- Agregación y publicación de datos
- Extracción de direcciones de correo electrónico
- Extracción de imágenes
- Extracción de dirección IP
- Extracción de número de teléfono
- Extracción de datos de página web
15. FMiner

Para quién sirve: Analistas de datos, comercializadores e investigadores que carecen de habilidades de programación
Por qué deberías usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite scrapear desde sitios web dinámicos usando Ajax y Javascript.
| PROS | CONS |
| – Herramienta de diseño visual – No se requiere la codificación – Múltiples opciones de navegación de rutas de rastreo – Se puede recopilar datos con palabras clave | No ofrece la formación para los usuarios nuevos |
16. Scrapy

Para quién sirve: Desarrolladores de Python con habilidades de programación y web scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que te permitirá avanzar en la siguiente tarea antes de que finalice.
| PROS | CONS |
| – Construido sobre Twisted, un marco de trabajo de red asincrónico – Rápido, las arañas de scrapy no tienen que esperar para hacer solicitudes a la vez | – Scrapy es solo para Python 2.7. – La instalación es diferente para diferentes sistemas operativos |
17. Helium Scrape
Para quién sirve: Analistas de datos, comercializadores e investigadores que carecen de habilidades de programación
Por qué deberías usarlo: Helium Scraper es un software de web scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
Características:
- Extracción rápida. Realizado por varios navegadores web Chromium fuera de la pantalla
- Capturar datos en estructuras complejas
- Flujo de trabajo simple
18. Scrape.it

Para quién sirve: Personas que necesitan datos escalables sin codificación
Por qué deberías usarlo: Scrape.it permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tienes que estudiar la codificación. Es una buena opción y vale la pena intentarlo si estás buscando una herramienta de web scraping segura.
| PROS | CONS |
| – Soporte móvil – Agregación y publicación de datos – Automatizará todo el sitio web para ti | El precio es un poco alto |
19. ScraperWiki

Para quién sirve: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación y el web scraping
Por qué deberías usarlo:ScraperWiki tiene dos nombres
QuickCode: es el nuevo nombre del producto ScraperWiki original. Le cambiaron el nombre, ya que ya no es un wiki o simplemente para rasparlo. Es un entorno de análisis de datos de Python y R, ideal para recopilar datos con el web scraping para los economistas, estadísticos y administradores de datos.
The Sensible Code Company: es el nuevo nombre de su empresa. Diseñan y venden productos que convierten la información desordenada en datos valiosos.
20. Zyte (o Scrapinghub)

Para quién sirve: Desarrolladores de web scraping / Python
Por qué deberías usarlo: Zyte es una plataforma de web scraping basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Zyte ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
| PROS | CONS |
| – La integración (scrapy + scrapinghub) es realmente buena, desde una simple implementación a través de una biblioteca o un docker lo hace adecuado para cualquier necesidad – El panel de trabajo es fácil de entender La efectividad | – No hay una interfaz de usuario en tiempo real que pueda ver lo que está sucediendo dentro de Splash – No hay una solución simple para el rastreo distribuido / de gran volumen Falta de monitoreo y alerta de tareas |
21. Screen-Scraper

Para quién sirve: Usuarios que se enfocan en la industria automotriz, médica, financiera y de comercio electrónico
Por qué deberías usarlo: Screen Scraper puede proporcionar servicios de recopilación de datos que cubren las necesidades de datos de la industria automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping. Como Octoparse también tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
| PROS | CONS |
| – Sencillo de ejecutar: se puede recopilar una gran cantidad de información hecha una vez – Económico: el raspado brinda un servicio básico que requiere poco o ningún esfuerzo – Precisión: los servicios de raspado no solo son rápidos, también son exactos | – Difícil de analizar: el proceso de raspado es confuso para obtenerlo si no eres un experto de web scraping – Tiempo: dado que el software tiene una curva de aprendizaje – Políticas de velocidad y protección: una de las principales desventajas del rastreo de pantalla es que no solo funciona más lento que las llamadas a la API, pero también se ha prohibido su uso en muchos sitios web |
22. Demand AI

Para quién sirve: Comercializadores y vendedores
Por qué deberías usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Indeed, Angellist, Viadeo.
| PROS | CONS |
| – Crear procesos de seguimiento automático en Pipedrive basados en los acuerdos creados – Ser capaz de agregar prospectos a lo largo del camino al crear acuerdos en el CRM – Ser capaz de integrarse de manera eficiente con CRM Pipedrive | – La herramienta requiere cierto conocimiento de las estrategias de salida y no es fácil para todos al principio – El servicio necesita bastantes interacciones para obtener el valor total |
23. ScrapeHero
Para quién sirve: Inversores, Hedge Funds, analistas de marketing
Por qué deberías usarlo: ScrapeHero como proveedor de API te permite convertir sitios web en datos. Proporciona servicios de recopilar datos de web personalizados para empresas e individuales.
| PROS | CONS |
| – La calidad y consistencia del contenido entregado es excelente – Buena capacidad de respuesta y atención al cliente – Tiene buenos analizadores disponibles para la conversión de documentos a texto | – Funcionalidad limitada en términos de lo que puede hacer con RPA, lo que causa que es difícil de implementar en casos de uso que no es tradicional – Los datos solo vienen en archivo CSV |
24. UniPath

Para quién sirve: Comerciantes de diferentes industrias
Por qué deberías usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales tras recopilar datos. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
Características:
- Conversión del valor FPKM de expresión génica en valor P
- Combinación de valores P
- Ajuste de valores P
- ATAC-seq de celda única
- Puntuaciones de accesibilidad global
- Conversión de perfiles scATAC-seq en puntuaciones de enriquecimiento de la vía
25. Web Content Extractor

Para quién sirve: Analistas de datos, comerciantes e investigadores que carecen de habilidades de la programación y el web scraping
Por qué deberías usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días.
| PROS | CONS |
| – Fácil de usar para la mayoría de los casos que puede encontrar en el web scraping – Raspar un sitio web con un simple clic y obtendrás tus resultados de inmediato – Con su soporte se responderán la mayoría de tus preguntas relacionadas con el software | El tutorial de youtube fue limitado |
26. Webharvy

Para quién sirve: Analistas de datos, comerciantes e investigadores que carecen de habilidades de programación
Por qué deberías usarlo: WebHarvy es una herramienta de recopilación de datos. Está diseñado para los usuarios que no son programadores. El extractor no necesita que escribas códigos. Tiene tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
| PROS | CONS |
| – Webharvey es realmente útil y eficaz. Viene con una excelente atención al cliente – Perfecto para raspar correos electrónicos y clientes potenciales – La configuración se realiza mediante una GUI que facilita la instalación inicialmente, pero las opciones hacen que la herramienta sea aún más poderosa | – A menudo no es obvio cómo funciona una función – Tienes que invertir mucho esfuerzo en aprender a usar el producto correctamente |
27. Web Scraper.io

Para quién sirve: Analistas de datos, comerciantes e investigadores que carecen de habilidades de programación
Por qué deberías usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos en la web. Es un software gratuito de web scraping para descargar páginas web dinámicas.
| PROS | CONS |
| – Los datos que se raspan se almacenan en el almacenamiento local y, por lo tanto, son fácilmente accesibles – Funciona con una interfaz limpia y sencilla – El sistema de consultas es fácil de usar y es coherente con todos los proveedores de datos | – Tiene alguna curva de aprendizaje – No es una buena opción para organizaciones |
28. Web Sundew

Para quién sirve: Empresas, comerciantes e investigadores
Por qué deberías usarlo: WebSundew es una herramienta de web scraping visual que funciona para el raspado estructurado de datos web. La edición Enterprise te permite ejecutar el web scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
Caraterísticas:
- Interfaz fácil de apuntar y hacer clic
- Extraer cualquier dato web sin una línea de codificación
- Desarrollado por Modern Web Engine
- Software de plataforma agnóstico
29. Winautomation

Para quién sirve: Desarrolladores, líderes de operaciones comerciales, profesionales de IT.
Por qué deberías usarlo: Winautomation es un web scraper de Windows que le permite automatizar tareas de escritorio y basadas en la web.
| PROS | CONS |
| – Automatizar tareas repetitivas – Fácil de configurar – Flexible para permitir una automatización más complicada – Se notifica cuando un proceso ha fallado | – Podría vigilar y descartar actualizaciones de software estándar o avisos de mantenimiento – La funcionalidad FTP es útil pero complicada – Ocasionalmente pierde la pista de las ventanas de la aplicación |
30. Web Robots
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación y web scraping.
Por qué deberías usarlo: Web Robots es una plataforma de web scraping basada en la nube para scrape sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
| PROS | CONS |
| – Ejecutarse en tu navegador Chrome o Edge como extensión – Localizar y extraer automáticamente datos de páginas web – SLA garantizado y excelente servicio al cliente – Puedes ver datos, código fuente, estadísticas e informes en el portal del cliente | – Solo en la nube, SaaS, basado en web – Falta de tutoriales, no tiene videos |
Conclusión
En general, bajo la influencia de la era de los macrodatos, la recopilación de datos se ha convertido en un comportamiento fundamental del procesamiento de datos. Si necesitas recopilar datos pero no sabes programación ni python, creo que Octoparse, scrape.it y FMiner son buenas opciones. Si ya tienes alguna base de programación, import.io y scrapy son sistemas operativos relativamente maduros. Espero que puedas encontrar la herramienta de raspado de datos adecuada para ti y obtener los datos que deseas.




