¿Qué es Web Scraping?
Este artículo te presenta detallamente cómo funciona el web scraping con crawler para extraer los datos y te presenta algunas herrmaientas relacionadas para tu uso.
¿Alguna vez has querido comparar los precios de un mismo artículo en varios sitios web al mismo tiempo? ¿O extraer automáticamente información de tus blogs favoritos? El web scraping lo hace todo posible.
En la era de Bigdata, cada vez más empresas comienzan a aumentar el presupuesto de los servicios SaaS, en los que el web scraping como tipo básico de ellos, proporciona soporte de datos y comodidad para muchas empresas, así que ¿realmente sabes el web scraping?
Hoy queremos hablarte del web scraping, aprenderemos qué es, cómo funciona y para qué sirve.
¡Ahora empezamos!
¿Qué es el Web Scraping?
Dice el Wikipedia:
Web scraping o raspado web es una técnica utilizada ediante programas de software para extraer información de sitios web. Usualmente, estos programas simulan la navegación de un humano en la World Wide Web ya sea utilizando el protocolo HTTP manualmente, o incrustando un navegador en una aplicación.
El web scraping(o raspado web) es la operación de extracción automática de contenidos y datos de la web. En cierto modo, es una técnica utilizada en diferentes campos como el marketing digital y la investigación para extraer información valiosa de las páginas web y darle un buen uso. Por lo tanto, otros términos para el web scraping son “raspador de contenidos” o “datos scraper”.
Existen diferentes formas de intentar implementar el raspado web, siendo la más sencilla utilizar una herramienta de scraping de datos de pago o gratuita como Octoparse, o escribir tu propio código de rastreo (lo cual es complicado y tedioso). Los crawlers de datos te dan acceso a datos actualizados y relevantes para que puedas mejorar tu estrategia y tomar decisiones informadas y de apoyo.

¿Es legal el web scraping?
Al fin y al cabo, los datos y la información son muy sensibles en la era actual de Internet. Afortunadamente, las extracción de datos abiertos en Internet no son intrínsecamente ilegales. Cuando un sitio web publica datos, éstos suelen estar a disposición del público o se pueden ver libremente y, por tanto, se pueden “raspar” libremente.
Por ejemplo, Amazon publica los precios de sus listas de productos, por lo que es perfectamente legal buscar precios y extraer los datos. Además, hay muchas aplicaciones de compra populares y extensiones de navegador que utilizan el raspado web exactamente con este fin, para que los usuarios sepan que están obteniendo el precio correcto.
Sin embargo, no todos los datos de la web están disponibles públicamente, lo que significa que no todos los datos de la web son legítimos. Cuando se trata de datos personales y de propiedad intelectual, el acto de “web scraping” puede convertirse en “web scraping” malintencionado, lo que puede dar lugar a sanciones como avisos de infracción de la DMCA. Por esta razón, Octoparse generalmente sólo recopila datos disponibles públicamente cuando lleva a cabo la recopilación de datos.
¿Qué es el web scraping malicioso?
Un raspado web malicioso es un rastreo de datos web que el editor de un sitio web no ha accedido a compartir. Estos datos suelen ser personales o de propiedad intelectual, y un rastreo malicioso puede aplicarse a cualquier dato que no esté destinado al público.
Sin embargo, hay una zona gris en esta definición. Mientras que muchos tipos de datos personales están protegidos por leyes como el Reglamento General de Protección de Datos (GDPR) y la Ley de Privacidad del Consumidor de California (CCPA), otros tipos de datos personales no lo están. Pero eso no significa que el scraping sea ilegal en ningún caso. Por ejemplo, supongamos que un proveedor de alojamiento web publica “accidentalmente” información sobre sus usuarios. Esto podría incluir una lista completa de nombres, correos electrónicos y otra información que técnicamente es pública.
Aunque técnicamente es legal hacerse con estos datos, puede que no sea la mejor idea. El hecho de que los datos sean públicos no significa necesariamente que el administrador de la red consintiera en su recopilación, aunque careciera de la supervisión necesaria para hacerlos públicos.
Esta “zona gris” ha dado al web scraping una reputación un tanto ambigua. Aunque el rastreo web es legal, puede utilizarse fácilmente con fines maliciosos o poco éticos. Por ello, a muchos ISP no les gusta que se rastreen sus datos, sea legal o no.
Over crawling
Otro tipo de rastreo web malicioso es el “overcrawling“, en el que una herramienta de rastreo envía demasiadas solicitudes en un periodo de tiempo determinado. Demasiadas peticiones pueden suponer una pesada carga para un ISP.
Por lo tanto, utilice el scraper web con precaución y sólo cuando esté absolutamente seguro de que los datos son de uso público. Recuerde que el hecho de que los datos sean públicos no significa que sea legal o ético rastrearlos.
¿Para qué sirve el web scraping?
Utilizando los datos como base, se pueden realizar análisis en profundidad y comprender múltiples campos e industrias. Por lo tanto, el scraper de datos también puede aplicarse a sitios web de diversas industrias, y los siguientes son algunos escenarios comunes de aplicación.
Para Comercio Electrónico – Comparación y análisis de precios
Para las empresas de comercio electrónico y los propietarios de tiendas web de productos agregados, el raspado web puede proporcionar datos de apoyo para su estrategia de precios mediante el seguimiento de los cambios de precios de los productos de la competencia.
Incluso a diario, los precios pueden fluctuar drásticamente. Al recopilar las tendencias históricas de los precios, los usuarios pueden comparar si el precio que están pagando es el ideal o no, así como juzgar el mercado actual por el patrón de fluctuaciones.
https://www.octoparse.es/template/mercadolibre-detalles-scraper
https://www.octoparse.es/template/wallapop-scraper-palabras-clave
Octoparse Ecommerce datos soluciones:
Scraper de Amazon Productos
Wallapop Scraper
Scraper de Mercado Libre Productos
Liverpool México Scraper
Para la Agregación de Información – Hoteles, viajes y inmobiliarios
Para muchos sitios web que agregan información, el acceso a los datos es algo muy importante. Y estos sitios suelen ser: información sobre viajes, reservas hoteleras y asesoramiento inmobiliario.
El scraping de datos puede ayudar a los propietarios de estos sitios web a obtener los datos más recientes de las principales plataformas, lo que resulta muy beneficioso para conocer el mercado y ofrecer información.
Por ejemplo, muchos sitios utilizan el scraping web para agregar listados inmobiliarios en una única base de datos y facilitar así el proceso. Algunos ejemplos comunes son idealista y fotocasa..
https://www.octoparse.es/template/airbnb-scraper-by-keyword
https://www.octoparse.es/template/idealista-listados-scraper
Para Marketing Digital – Generación de leads
El web scraping también puede utilizarse para generar valiosas listas de clientes potenciales sin mucho esfuerzo. En las plataformas de redes sociales hay un sinfín de usuarios potenciales y, aunque hay que ser preciso con la segmentación, se puede utilizar la recopilación de web datos para generar suficientes datos de usuarios como para crear listas de clientes potenciales estructuradas, y es mucho más fácil y prometedor que crear listas de clientes potenciales uno mismo.
Además de los canales de las redes sociales, google maps también puede proporcionar muchas pistas, y al captar los datos de las reseñas de los usuarios, podemos obtener más ideas y mejoras de los productos, y también ganar muchos usuarios potenciales.
https://www.octoparse.es/template/google-maps-contact-scraper
Octoparse Leads generación soluciones – redes sociales:
Twitter Scraper
Pinterest Pintura Scraper
Reddit Scraper
Quora Scraper
Lemon 8 Scraper
Para Gestión de Empleos – Investigación de las ofertas de empleos
El talento es el recurso más valioso de una empresa. Las empresas pueden utilizar rastreadores web para buscar empleo en distintas plataformas, analizar datos y comprender las condiciones actuales del mercado, las tendencias salariales y los requisitos en materia de competencias.
Con el acceso regular del web scraping para monitorizar miles de portales de empleo (Linkedin, Glassdoor y otros portales de empleo importantes), puede proporcionar información valiosa para ayudar a las empresas a diseñar paquetes de remuneración competitivos y atraer mejor el talento. Diseñar paquetes retributivos competitivos para atraer mejor el talento.
https://www.octoparse.es/template/linkedin-job-search-scraper-by-url
Octoparse datos de empleos soluciones:
LinkedIn Scraper
Glassdoor Scraper
Indeed Scraper
Para SEO Estrategias – Seguimiento y mejora la posición en motores de búsquedas
Recopilar datos de los resultados de los motores de búsqueda puede ayudar a los creadores de contenidos y a los profesionales del marketing a optimizar los títulos, las descripciones y las palabras clave(Títulos, descripción, Keywords), perfeccionar las estrategias de SEO y mejorar la generación de oportunidades para los resultados de los motores de búsqueda, las páginas web o los contenidos. Además, mediante la búsqueda de productos relacionados, se pueden recopilar contenidos relacionados con los productos y conocer las tendencias y dinámicas del mercado.
https://www.octoparse.es/template/google-search-scraper
Octoparse datos de búquedas soluciones:
Google Search Scraper
Bing Scraper
DuckDuckGo Scraper
Para Estudio Profesional – Investigación Académico y Contenidos
En la investigación académica y la recopilación de noticias, el raspado web puede utilizarse para actualizar datos periódicamente, lo que permite a los creadores de noticias e integradores de contenidos ser los primeros en acceder a la información y los contenidos más recientes.
La organización de bases de datos académicas mediante web crawling proporciona una fuente de información más amplia y completa y una base más científica para la investigación académica.
Octoparse datos académicos soluciones:
Google Scholar Scraper
Aprender más sobre los escenarios de web scraping con Octoparse>>
¿Cómo funciona el scraping web?
Los actores importantes en el raspado web son los crawlers web y los scrapers.
Utilizando Crawler Web
Cuando hablamos de web scraping, ¿qué le viene a la mente? — Solemos imaginarlo como una araña que se arrastra por la web. Este es como el trabajo de un rastreador web, que encuentra la red de la estructura en la web tipo de una araña y se arrastra a través de la web para obtener información. Se llama “raspador web” porque “rastreador” es un término utilizado para describir el acto de acceder automáticamente a una página web y obtener datos a través de una herramienta de scraper.

Si queremos dar una definición precisa de un rastreador web, podemos decir que es un tipo de robot de Internet, también conocido como araña web, auto indexador, robot web, que escanea automáticamente toda la web en busca de información para crear un índice de datos. Y este proceso es lo que llamamos web crawling.
Utilizando Web Scraper
Trabaje en la extracción rápida de información relevante de los sitios web. Dado que los sitios web se construyen con HTML, los scrapers utilizan expresiones regulares (regex), XPath, selectores CSS y otros localizadores para encontrar y extraer rápidamente determinados contenidos. Por ejemplo, puede proporcionar a los rastreadores web expresiones regulares para palabras clave específicas.
El flujo de trabajo básico del web scraping
En el nivel más básico, el rastreo web puede reducirse a unos sencillos pasos:
- Especificar la URL del sitio y la página que se va a rastrear.
- Realizar una petición HTML a la URL (es decir, “visitar” la página)
- Extraer la información necesaria del HTML utilizando localizadores como expresiones regulares o programación como python y Json
- Guardar los datos en un formato estructurado (por ejemplo, CSV o JSON)
Sin embargo, las cosas no siempre son tan sencillas, especialmente cuando se realiza un rastreo web a gran escala. Uno de los mayores retos del rastreo web es mantener la flexibilidad de las herramientas de scrapers a medida que los sitios cambian de diseño o adoptan medidas contra el rastreo (no se puede recopilar todo el contenido). Aunque esto no es demasiado difícil si sólo se rastrean unos pocos sitios a la vez, scrapear más sitios puede convertirse rápidamente en una tarea engorrosa.
Para minimizar el trabajo extra, es importante entender cómo los sitios web intentan bloquear la herramienta de rastreo.
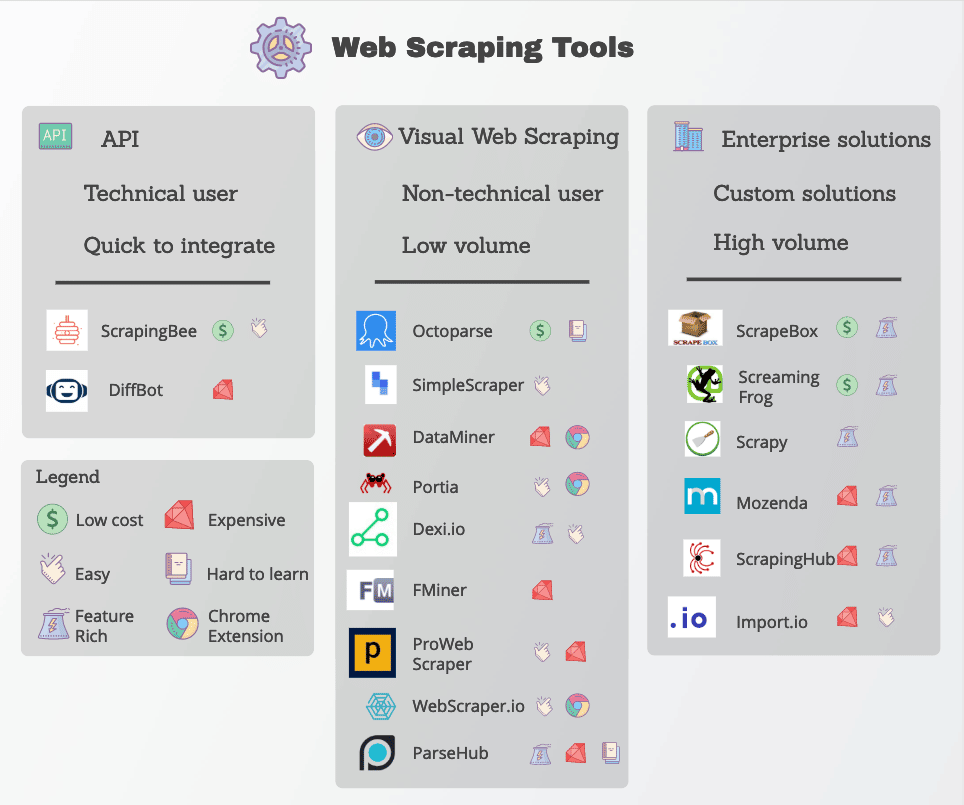
Herramientas adecuadas de web scraping
En un mundo de desarrollo tan rápido y basado en datos, las personas tienen una gran demanda de datos. Sin embargo, no todos tienen buenos conocimientos sobre el rastreo de un determinado sitio web para obtener los datos deseados. En esta sección, me gustaría presentar algunas herramientas útiles y poderosas de rastreo web para ayudarlo a superarlo.
Si usted es un programador o está familiarizado con el web crawler o el web scraping, open-source web crawlers podrían ser más adecuados para que los manipule. Por ejemplo, Scrapy, uno de los raspadores web de código abierto más famosos disponibles en la Web, es un marco de raspado web gratuito escrito en Python.
1. Octoparse
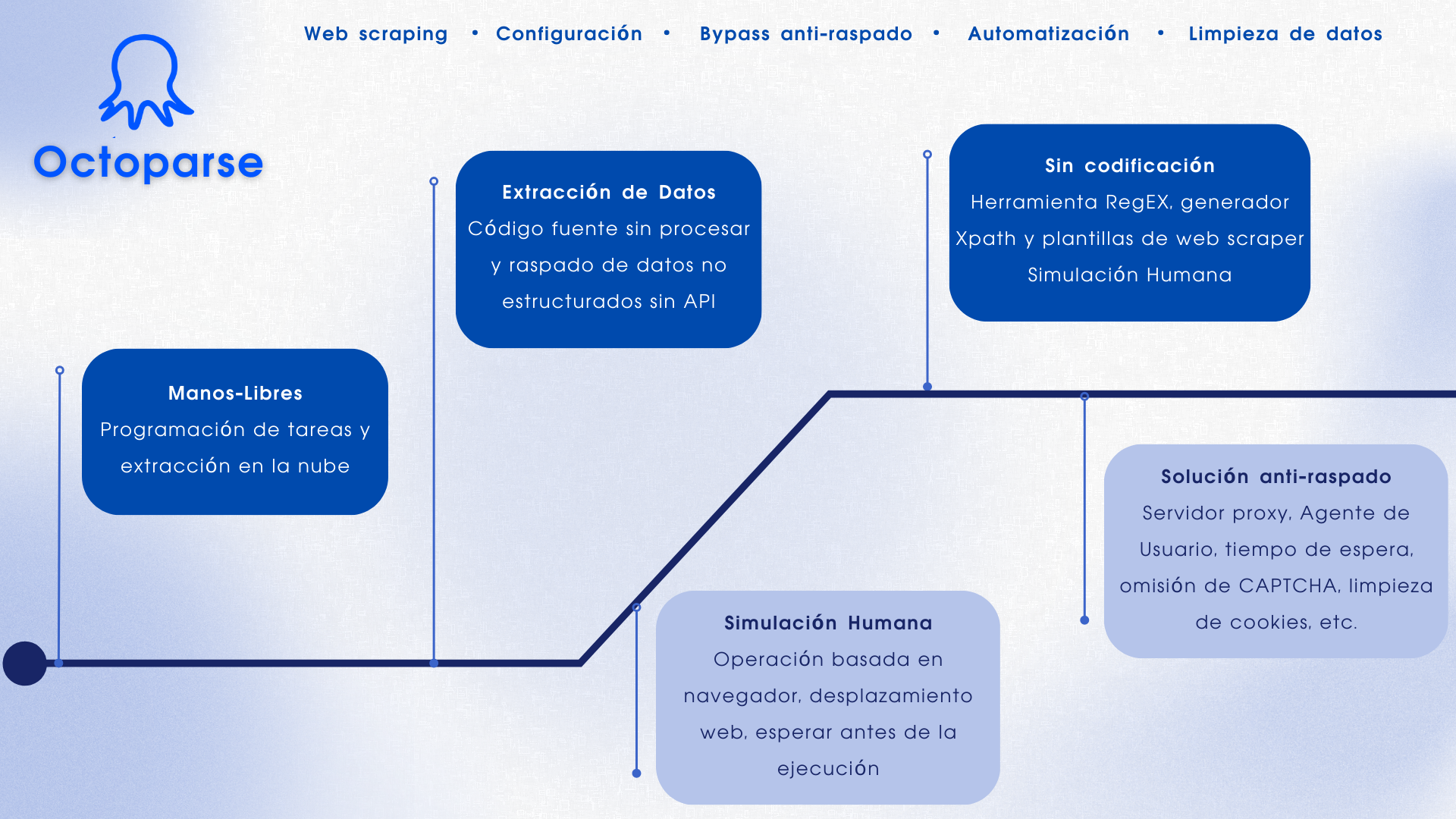
Si tú eres muy nuevo en el web scraping y no tienes conocimientos de codificación, permítame presentarte una poderosa herramienta del web scraping que es Octoparse.
Kinsta nos ha resumido algunos de los programas de captura de datos más habituales del mercado. Para mejorar el ineficiente tiempo de aprendizaje, Octoparse ha lanzado los nuevos tutoriales Octoparse 101, y el centro de tutoriales se ha renovado por completo para ofrecer más recursos y oportunidades a los novatos.
- Detección Automática
Reconocimiento automático de la estructura de las páginas web, fácil de tratar con muchos tipos de páginas web y métodos de recopilación.
- Plantillas prediseñadas
Para cada sitio de recopilación principal, establezca una plantilla de recopilación común, sólo tiene que introducir las palabras clave para obtener los datos, sin necesidad de un aprendizaje excesivo de software.

- Proxies IP y Anti-bloqueado
La rotación de IP residenciales garantiza un proceso de cobro fluido y reduce la probabilidad de accesos prohibidos. Mejorar la eficacia de la recogida
- Exportación Fácilmente
Proporciona una variedad de métodos de exportación de datos para satisfacer una variedad de necesidades, si usted necesita hacer la organización de datos o la construcción de bases de datos, Octoparse puede hacerlo por usted.

2. Import.io
Import.io es una plataforma de recopilación de datos popular en la industria de web scraping. Proporciona un software de web scraping que te permite extraer datos de una web y organizarlos en conjuntos de datos. Puede integrar los datos de una web en herramientas analíticas para ventas y marketing obteniendo información.
PROS
- Permite el web scraping en colaboración con equipo
- Eficaz y preciso cuando se trata de extraer datos de largas listas de URL
- Rastrear páginas y raspar según los patrones que especificas a través de ejemplos
CONS
- Es necesario reintroducir una aplicación de escritorio, ya que se basa en la nube
- Se requiere tiempo para aprender los pasos de usar esta herramienta de web scraping
3. Parsehub
ParseHub es un software visual de web scraping que puedes usar para recopilar datos de la web. Puedes extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar tu dirección IP cuando se encuentre con sitios web con técnicas anti-scraping.
PROS
- Tener un excelente boarding que te ayude a comprender el flujo de trabajo y los conceptos dentro de las herramientas de web scraping
- Plataforma cruzada, para Windows, Mac y Linux
- No requiere conocimientos básicos de programación para comenzar
- Atención al cliente de alta calidad
CONS
- No se pueden importar / exportar las plantillas
- Tener solamente una integración limitada de javascript / regex
¿Cómo detectar y bloquear el web scraping?
Después de hablar mucho sobre cómo funciona el web scraping, cambiemos de marcha por un momento: supongamos que eres el creador de un sitio web y no quieres que otras personas rastreen tus datos utilizando los métodos mencionados anteriormente. ¿Qué puede hacer para proteger tu sitio?
Aparte de instalar plugins de seguridad básicos, hay algunas formas de bloquear eficazmente los crawlers web y los robots scrapers.
Bloqueo de direcciones IP: Muchos proveedores de alojamiento web rastrean las direcciones IP de los visitantes. Si el host observa que un visitante en particular está generando muchas peticiones al servidor (como es el caso de algunos rastreadores o bots), puede bloquear la IP por completo.
Configurar el archivo robots.txt: El archivo robots.txt permite a los hosts web indicar a los rastreadores, arañas y otros bots a qué pueden acceder y a qué no. Por ejemplo, algunos sitios web utilizan archivos robots.txt para mantenerse en privado e indicar a los motores de búsqueda que no los indexen. Aunque la mayoría de los motores de búsqueda respetan estos archivos, muchas formas maliciosas de rastreo web no lo hacen.
Filtrado de peticiones: cada vez que alguien visita un sitio web, “solicita” una página HTML a un servidor web. Estas peticiones suelen ser visibles para el servidor web, que ve determinados identificadores (por ejemplo, la dirección IP) y agentes de usuario (por ejemplo, los navegadores web). Aunque ya hemos hablado del bloqueo por IP, los servidores web también pueden filtrar por agentes de usuario.
Mostrar CAPTCHA: ¿Alguna vez has tenido que introducir una extraña cadena de texto o hacer clic en al menos seis veleros antes de visitar una página? Entonces se encuentra con los “captchas” o pruebas públicas totalmente automatizadas que distinguen entre ordenadores y humanos. A pesar de su sencillez, son muy eficaces para filtrar rastreadores web y otros bots.
Honeypots: los honeypots son trampas utilizadas para atraer e identificar visitantes no deseados. En el caso del rastreo web, los webmasters pueden incluir enlaces invisibles en sus páginas. Aunque los usuarios humanos no se darán cuenta, los robots los visitarán automáticamente mientras se desplazan, lo que permitirá al webmaster recopilar (y bloquear) su dirección IP o agente de usuario.
¿Qué debe hacer un web scraper ante estos obstáculos?
- Utilizar rotación de IP proxy o VPN
- Comprobar periódicamente la estructura y la documentación del sitio de captura
Conclusión
En resumen, web scraping juegan un papel muy importante en la era de Internet. Sin los web crawlers, no puedes imaginar lo difícil que es encontrar la información que deseas entre ese océano de información.
Si quieres hacer alguna colección específica o no sabes por dónde empezar. Entonces merece la pena probar Octoparse, un software gratuito de recopilación de datos, ¡que te encontrará una solución de datos más adecuada para ti!

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.
Posts populares
 Las 7 mejores herramientas de IA gratis para buscar artículos científicos en 2026
Las 7 mejores herramientas de IA gratis para buscar artículos científicos en 2026 Scraping de datos para mejorar estrategias de ventas B2B
Scraping de datos para mejorar estrategias de ventas B2B Las Mejores Herramientas de Seguimiento de Precios en Amazon: Las Probamos Todas
Las Mejores Herramientas de Seguimiento de Precios en Amazon: Las Probamos Todas Cómo extraer reseñas de Google Maps y exportarlas a Excel automáticamente
Cómo extraer reseñas de Google Maps y exportarlas a Excel automáticamente Cómo exportar todos los comentarios de YouTube
Cómo exportar todos los comentarios de YouTube
Explorar temas
Empiece a utilizar Octoparse enseguida
Artículos relacionados

Elena Allende
Es fácil encontrar herramientas de venta de Amazon en línea, pero no todas están diseñadas para novatos. Este blog te guiará a construir un negocio exitoso en Amazon Seller.2024-11-18T00:00:00+00:00 · 9 min
Paulina Tobella
Sin duda alguna, el web scraping es rápido, rentable y puede recopilar datos de sitios web con una precisión de más del 90%. Le libera de copiar y pegar en documentos de diseño desordenado. Sin embargo, es posible que algo haya sido ignorado. Existen algunas limitaciones e incluso riesgos que se esconden detrás del web scraping.2024-09-29T00:00:00+00:00 · 6 min ¿Estás buscando una forma rápida y eficaz de extraer datos valiosos de Reddit? Por ello aquí estamos. Con Reddit scraper, podrás extraer fácilmente datos de Reddit en cuestión de minutos.2023-04-17T00:00:00+00:00 · 10 min
¿Estás buscando una forma rápida y eficaz de extraer datos valiosos de Reddit? Por ello aquí estamos. Con Reddit scraper, podrás extraer fácilmente datos de Reddit en cuestión de minutos.2023-04-17T00:00:00+00:00 · 10 min Si estás buscando opiniones de los mejores hoteles de TripAdvisor, en este blog te enseñaré cómo extraer datos de TripAdvisor utilizando Python y TripAdvisor scraper.2023-04-13T00:00:00+00:00 · 6 min
Si estás buscando opiniones de los mejores hoteles de TripAdvisor, en este blog te enseñaré cómo extraer datos de TripAdvisor utilizando Python y TripAdvisor scraper.2023-04-13T00:00:00+00:00 · 6 min