Sin duda alguna, el web scraping tiene ventajas. Es rápido, rentable y puede recopilar datos de sitios web con una precisión de más del 90%. Le libera de copiar y pegar en documentos de diseño desordenado. Sin embargo, es posible que algo haya sido ignorado. Existen algunas limitaciones e incluso riesgos que se esconden detrás del web scraping.
¿Qué es el web scraping y para qué se utiliza?
Para aquellos que no están familiarizados con el web scraping, permítanme explicarles. El web scraping es una técnica que se utiliza para extraer información de sitios web a gran velocidad. Puede acceder a los datos extraídos y guardados en el local en cualquier momento. El web scraping funciona como uno de los primeros pasos en el análisis de datos, visualización de datos y minería de datos, ya que recopila datos de muchas fuentes. Preparar los datos es un requisito previo para la visualización o análisis en el futuro. Eso es obvio. ¿Cómo podemos empezar a hacer web scraping?
¿Cómo elegir el mejor método de extraer datos web?
Existen algunas técnicas comunes para extraer datos de las páginas web, que vienen con algunas limitaciones. Puede crear su propio rastreador utilizando lenguajes de programación, subcontratar sus proyectos de raspado web o utilizar una herramienta de raspado web. Sin un contexto específico, no existe “la mejor manera de hacer web scraping”. Piense en su conocimiento básico de codificación, su tiempo disponible y su presupuesto financiero, tendrá su propia elección.
Para Codificador
> Por ejemplo, si es un codificador experimentado y confía en sus habilidades de codificación, claro que puede extraer datos usted mismo. Pero como cada sitio web necesita un rastreador, tendrá que crear varios rastreadores para diferentes sitios. Esto le puede gastar mucho tiempo. Y debe estar equipado con suficientes conocimientos de programación para el mantenimiento de los rastreadores. Piénselo.
Para Gerente de empresas
> Si es dueño de una empresa con un gran presupuesto que desea obtener datos precisos, la historia sería diferente. Olvídese de la programación, simplemente contrata a un grupo de ingenieros o subcontrata tu proyecto a profesionales.
Para Freelancers
> Hablando de subcontratación, puede encontrar algunos freelancers en línea que ofrecen estos servicios de recolección de datos. El precio unitario parece bastante asequible. Sin embargo, si calcula cuidadosamente con la cantidad de sitios y la cantidad de artículos que planea obtener, el gasto total puede crecer exponencialmente. Las estadísticas muestran que para extraer información de 6000 productos de Amazon, las cotizaciones de las empresas de web scraping tienen un promedio de 250 dólares para la configuración inicial y 177 dólares para el mantenimiento mensual.
Para Pequeñas Compañías
> Si es propietario de una pequeña empresa o simplemente necesita datos sin conocimientos de codificación, la mejor opción es elegir una herramienta de raspado adecuada que se adapte a sus necesidades. Como referencia, puede consultar esta lista de Los 30 Mejores Software Gratuitos de Web Scraping.
¿Cuáles son las limitaciones de las herramientas de web scraping?
1. Curva de aprendizaje
Incluso la herramienta de raspado más fácil requiere tiempo para dominarla. Algunas herramientas, como Apify, aún requieren conocimientos de codificación para usarla. Algunas herramientas que no son fáciles de manejar pueden tardar semanas en aprender. Para raspar sitios web con éxito, es necesario tener conocimientos sobre XPath, HTML, AJAX. Hasta ahora, la forma más fácil de raspar sitios web es utilizar plantillas de raspado web prediseñadas para extraer datos con unos clics.
2. La estructura de los sitios web cambia con frecuencia
Los datos extraídos se organizan de acuerdo con la estructura del sitio web. A veces, vuelve a visitar un sitio y encontrará que el diseño ha cambiado. Algunos diseñadores actualizan constantemente los sitios web para mejorar la interfaz de usuario, algunos pueden hacerlo con el fin de anti-scraping.
El cambio puede ser pequeño como un cambio de posición de un botón o puede ser un cambio drástico del diseño general de la página. Incluso un cambio menor puede estropear sus datos. Como los rastreadores se construyen de acuerdo con el sitio anterior, debe ajustar sus rastreadores cada pocas semanas para obtener los datos correctos.
3. No es fácil manejar sitios web complejos
Aquí viene otro complicado desafío técnico. Si observa el raspado web en general, el 50% de los sitios web son fáciles de scraspear, el 30% son moderados y el último 20% es bastante difícil de hacer web scraping. Algunas herramientas de raspado están diseñadas para extraer datos de sitios web simples que aplican navegación numerada.
Sin embargo, hoy en día, más sitios web están comenzando a incluir elementos dinámicos como AJAX. Los sitios grandes como Twitter aplican un desplazamiento infinito y algunos sitios web necesitan que los usuarios hagan clic en el botón “cargar más” para seguir cargando el contenido. En este caso, los usuarios requieren una herramienta de raspado más funcional.
4. Extraer datos a gran escala es mucho más difícil
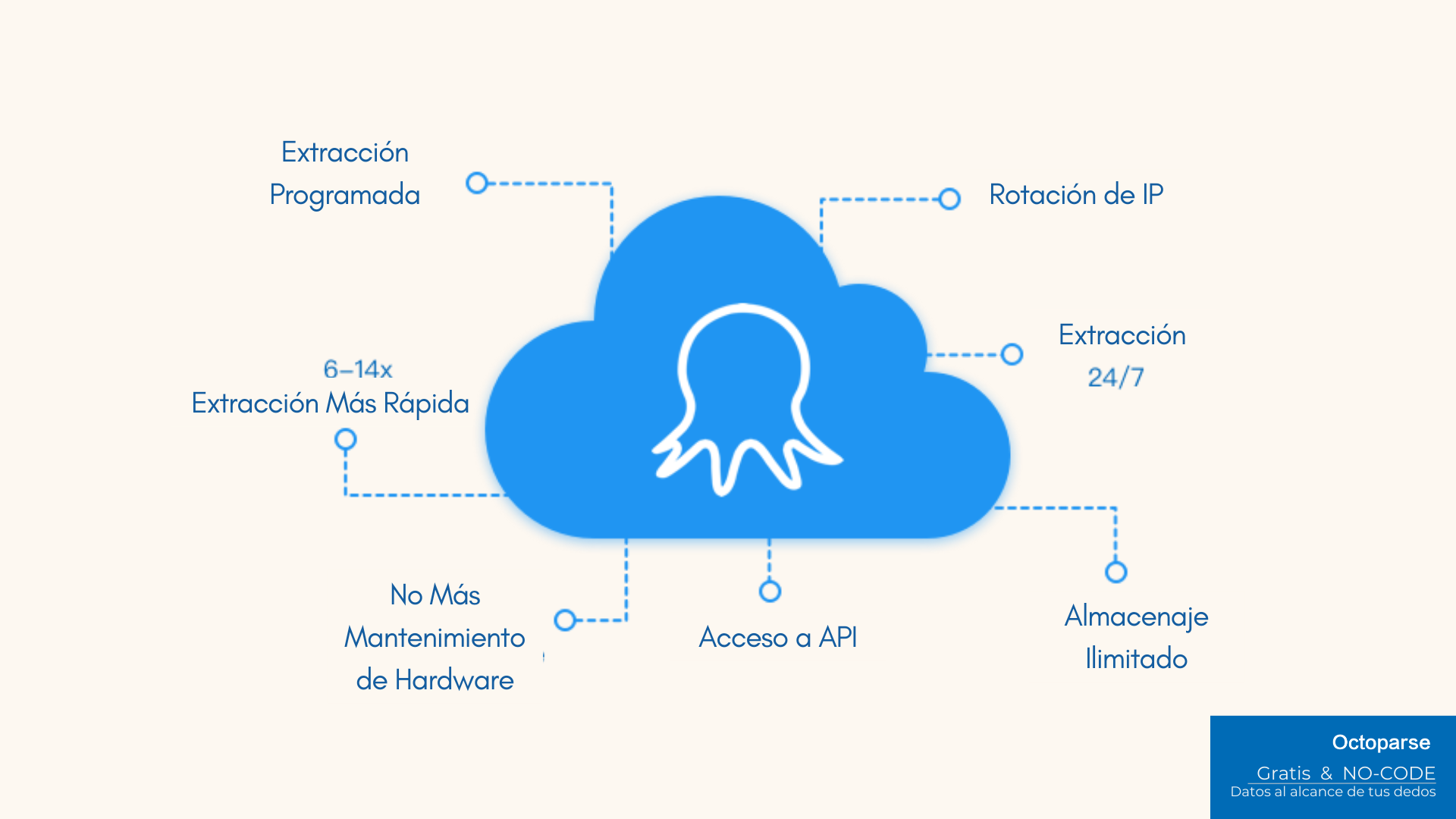
Algunas herramientas no pueden extraer millones de registros, ya que solo pueden manejar un raspado a pequeña escala. Esto causa dolores de cabeza a los propietarios de negocios de comercio electrónico que necesitan millones de líneas de datos regulares directamente en su base de datos. Los raspadores basados en la nube como Octoparse y Web Scraper funcionan bien en términos de extracción de datos a gran escala. Las tareas se ejecutan en varios servidores en la nube. Obtiene una velocidad rápida y un espacio gigantesco para la retención de datos.
5. Una herramienta de web scraping no es omnipotente
¿Qué tipo de datos se pueden extraer? Principalmente, los textos y URLs.
Las herramientas avanzadas pueden extraer textos del código fuente (HTML interno y externo) y usar expresiones regulares para reformatearlo. En el caso de las imágenes, solo se pueden extraer sus URLs y convertirlas en imágenes más tarde. Si tiene curiosidad sobre cómo extraer URL de imágenes y descargarlas en masa, puede echar un vistazo a Cómo construir un rastreador de imágenes sin codificación.
Además, es importante tener en cuenta que la mayoría de los raspadores web no pueden rastrear archivos PDF, ya que analizan elementos HTML para extraer los datos. Para extraer datos de archivos PDF, necesita otras herramientas como Smallpdf y PDFelements.
6. Su IP puede ser prohibida por el sitio web de destino.
Captcha molesta. ¿Alguna vez se le ocurre que necesita superar un captcha al raspar de un sitio web? Tenga cuidado, eso podría ser una señal de detección de IP. Raspar un sitio web genera mucho tráfico, lo que puede sobrecargar un servidor web y causar pérdidas económicas al propietario del sitio. Para evitar bloquearse, existen muchos trucos. Por ejemplo, puede configurar su herramienta para simular el comportamiento de navegación normal de un humano.
7. Incluso hay algunos problemas legales involucrados
¿Es legal el web scraping? Es posible que un simple “sí” o “no” no cubra todo el tema. Digamos que … depende. Si está extrayendo datos públicos para usos académicos, debe estar bien. Pero si extrae información privada de sitios que indican claramente que no se permite el scraping automático, puede meterse en problemas. LinkedIn y Facebook se encuentran entre los que afirman claramente que “no damos la bienvenida a los scrapers aquí” en su archivo robots.txt / términos y servicio (ToS). Cuide sus actos mientras hace web scraping.
Para terminar
En pocas palabras, existen muchas limitaciones en el web scraping. Si desea obtener datos de sitios web difíciles de extraer, como Amazon, Facebook e Instagram, puede recurrir a una empresa de datos como servicio como Octoparse. Este es el método más conveniente para extraer sitios web que aplican fuertes técnicas anti-raspado. Un proveedor de DaaS ofrece un servicio personalizado de acuerdo a sus necesidades. A través de proporcionarle los datos, lo libera del estrés de construir y mantener sus rastreadores. No importa en qué industria se encuentre, comercio electrónico, redes sociales, periodismo, finanzas o consultoría, si necesita datos, no dude en contactarnos.

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.



