Guardar una imagen de la página web es sencillo. Simplemente haga clic derecho y seleccione “save image as”. Pero, ¿qué pasa si tiene cientos o incluso miles de imágenes que deben guardarse? ¿Funcionará el mismo truco? ¡Al menos no para mí!
En este artículo, quiero mostrarle cómo crear rápidamente un rastreador de imágenes con CERO codificaciones. Incluso si no tienes absolutamente ningún conocimiento técnico, deberías ser capaz de lograrlo en 30 minutos. Es posible que necesite estas imágenes para volver a bloguear, revender o capacitar habilidades, el mismo truco puede extenderse literalmente a cualquier sitio web. Listo? Empecemos.
Preparación antes de crear el rastreador de imágenes
1. Instalaciones
Necesitará las siguientes herramientas:
• Octoparse: una herramienta de web scraping visual sin codificación
• TabSave: Complemento de Chrome para guardar imágenes al instante al proporcionar una lista de URL
2. Prerrequisitos
Sería mejor si está familiarizado con cómo funciona Octoparse en general. Echa un vistazo a Octoparse Scraping FAQ si eres nuevo en la herramienta.
Crear un proyecto
¡No todas las imágenes son iguales! Algunas imágenes se pueden obtener directamente de la página web, otras imágenes se activan solo haciendo clic en las miniaturas. Bueno, en este tutorial, le mostraré cómo lidiar con cada uno de estos escenarios a través de algunos ejemplos.
Ejemplo 1: Recuperar Imágenes Directamente de la página web
Para demostrarlo, vamos a scrape las imágenes de los perros de Pixabay.com. Para seguir, busque “dogs” en Pixabay.com, entonces debería llegar a esta página.
1) Haga clic en “+ Task” para comenzar una nueva tarea en Modo Avanzado. Luego, ingrese la URL de la página web de destino en el cuadro de texto y haga clic en “Guardar”.
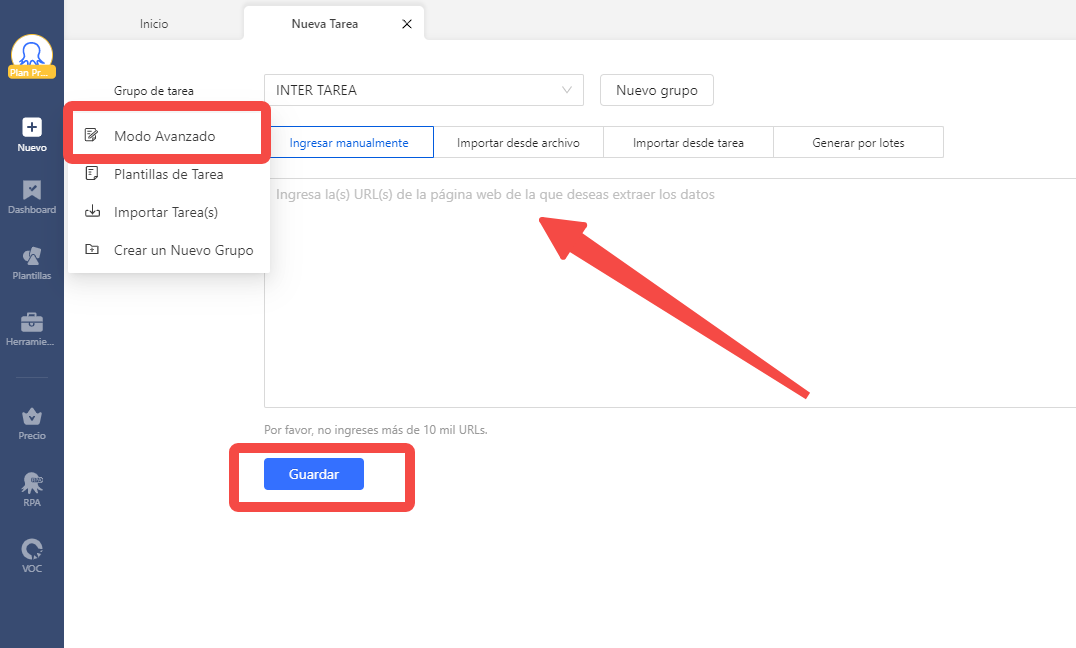
Deberías llegar aquí:.
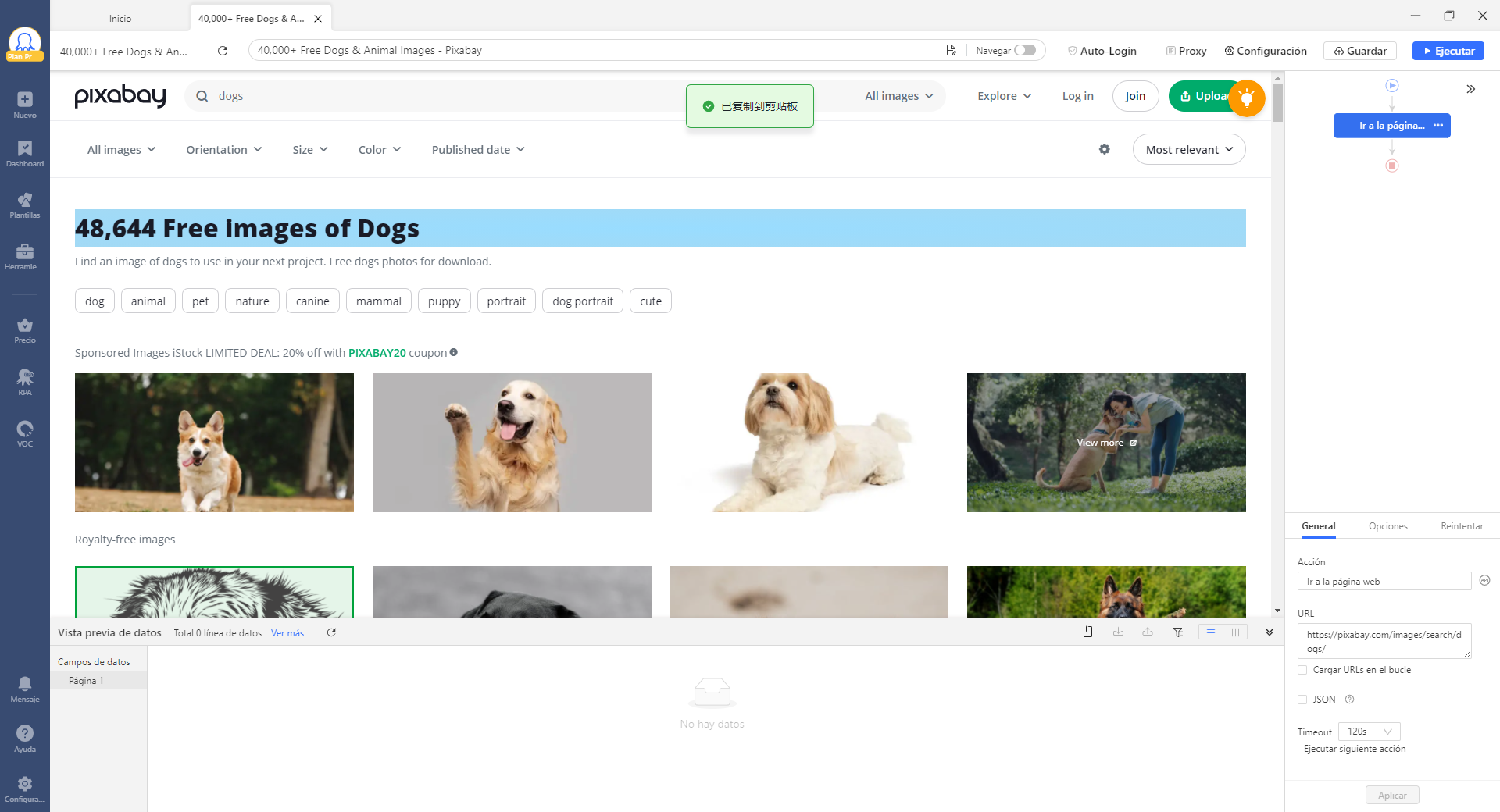
2) A continuación, le diremos al bot qué imágenes buscar.
Haga clic en la primera imagen. El panel de Tips ahora lee “Se ha seleccionado 1 elemento de imagen e identificado, 25 listado de elementos homogéneos“. Esto es genial, exactamente lo que necesitamos. Continúe para seleccionar “Elegir todos los elementos similares”, luego “Extraer enlace de imagen“.
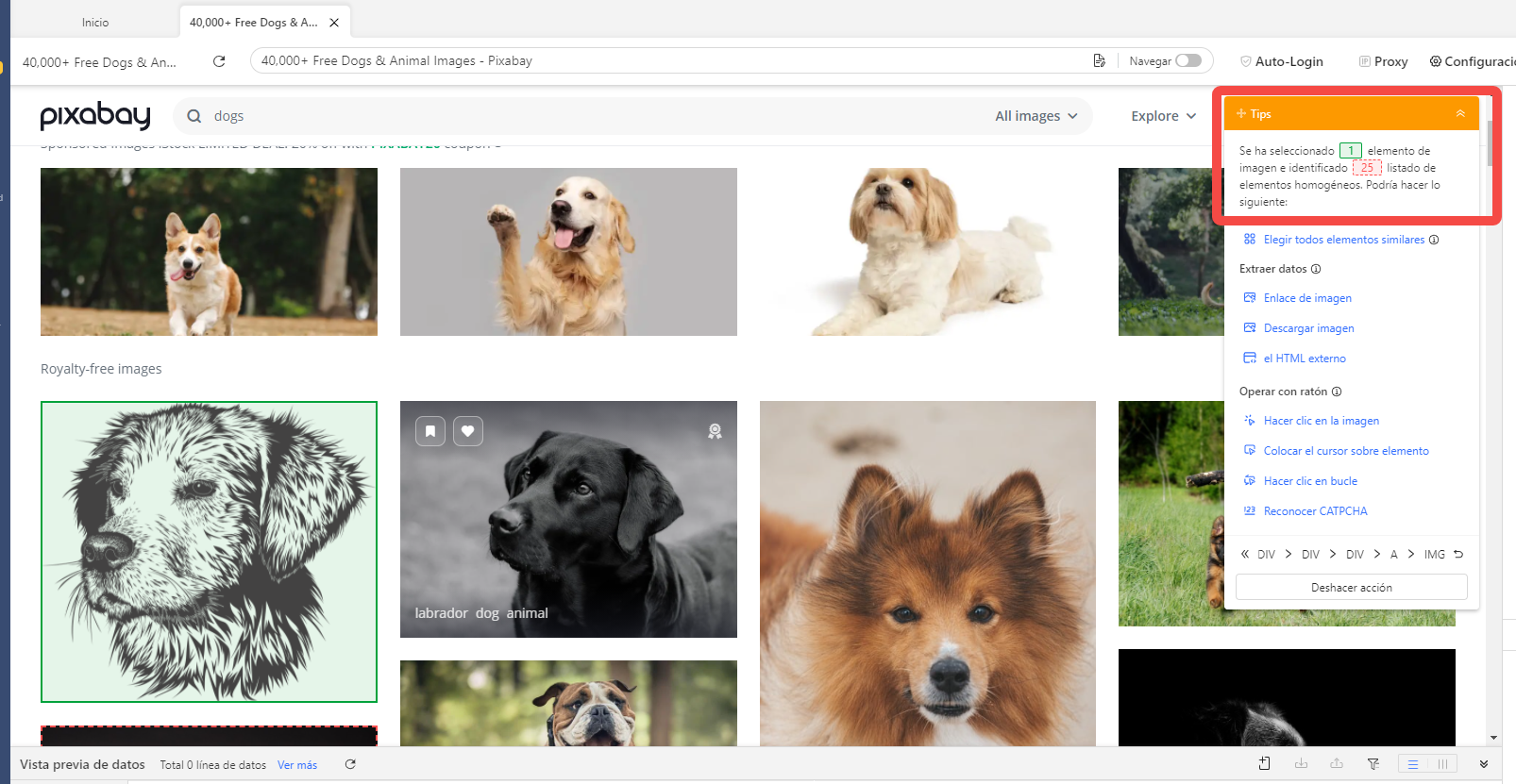
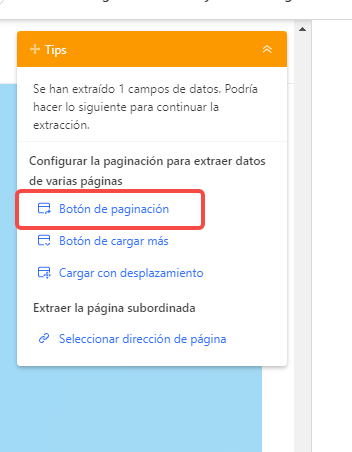
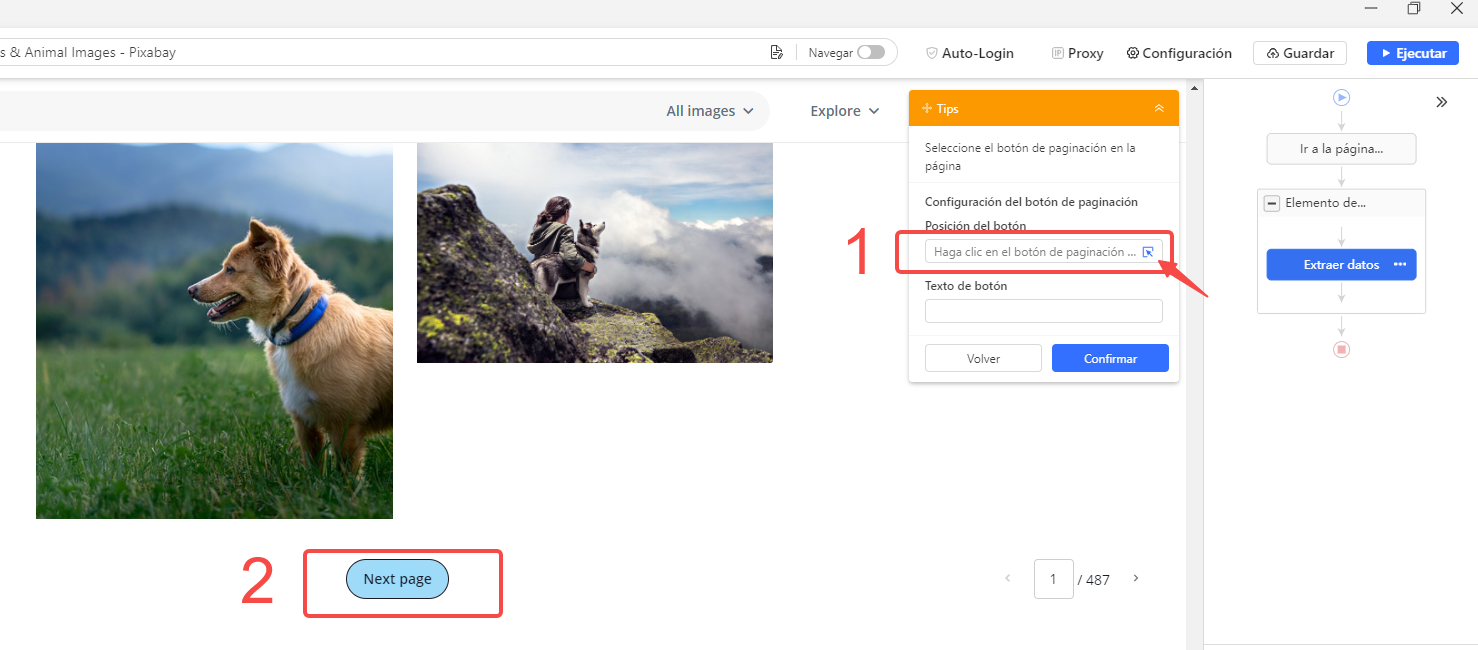
3) Por supuesto, no solo queremos las imágenes de la página 1, sino de imágenes de todas las páginas (o tantas páginas como sea necesario).
Para hacer esto, desplácese hacia abajo hasta la parte inferior de la página actual, ubique el botón “Next page” y haga clic en él.
Obviamente queremos hacer clic en el botón “Next page” muchas veces, por lo que tiene sentido seleccionar “Loop click the selected link” en el panel de Consejos de acción.
Ahora, solo para confirmar si todo se configuró correctamente. Cambie el interruptor de flujo de trabajo  en la esquina superior derecha.
en la esquina superior derecha.
Además, verifique el panel de datos y asegúrese de que los datos deseados se hayan extraído correctamente.
3) Solo hay una cosa más para ajustar antes de ejecutar el crawler.
Durante la depuración, noté que el código fuente HTML se actualiza dinámicamente a medida que uno se desplaza hacia abajo en la página web. En otras palabras, si la página web no se desplaza hacia abajo, no podremos obtener las URL de imagen correspondientes del código fuente. Por suerte para nosotros, Octoparse se desplaza automáticamente hacia abajo fácilmente.
Tendremos que agregar el desplazamiento automático tanto cuando el sitio web se carga por primera vez como cuando se pagina.
Haga clic en “Ir a la página web” desde el flujo de trabajo. En el lado derecho del flujo de trabajo, localice “Opciones“, marque “Desplazarse hacia abajo en la página después de que se cargue“.
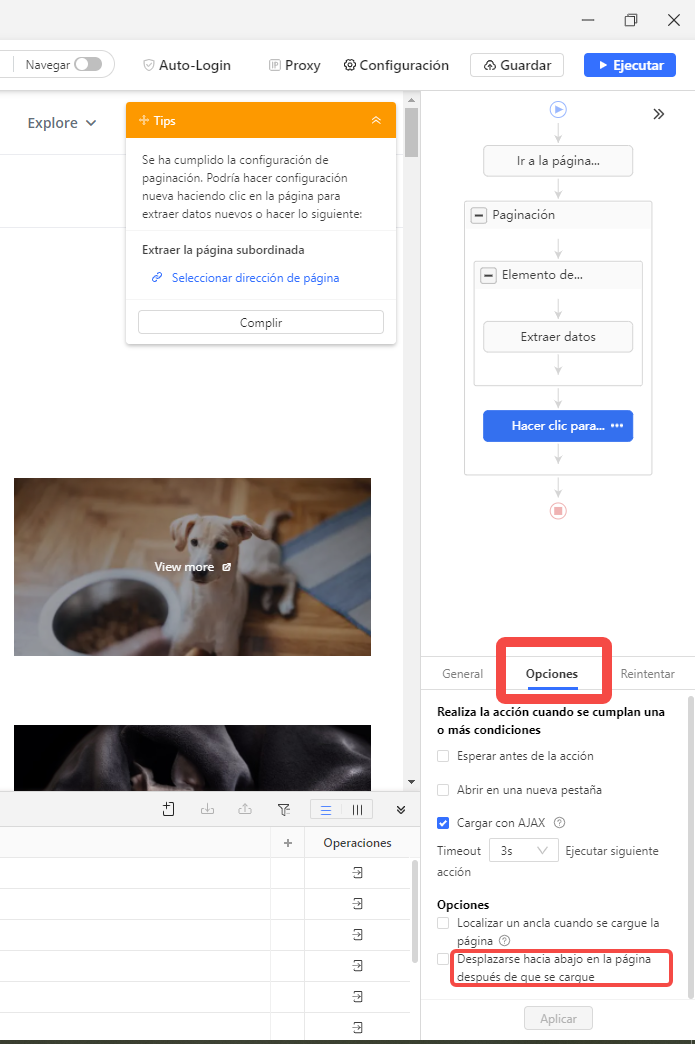
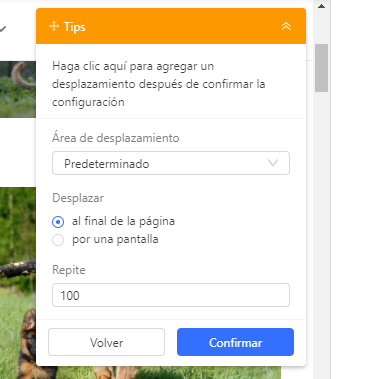
Luego, decida cuántas veces desplazarse y a qué ritmo. Aquí configuro tiempos de desplazamiento = 40, intervalo = 1 segundo, desplazamiento = desplazamiento hacia abajo para una pantalla. Esto básicamente significa que Octoparse se desplazará hacia abajo una pantalla 40 veces con 1 segundo entre cada desplazamiento.
No se me ocurrió esta configuración al azar, pero hice un pequeño ajuste para asegurarme de que esta configuración funciona. También noté que era esencial usar “por una pantalla” en lugar de “al final de la página“. Principalmente porque solo necesitamos actualizar gradualmente la URL de la imagen en el código fuente.
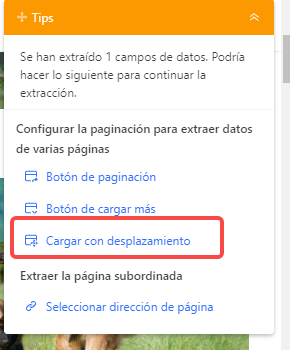
Aplique la misma configuración al paso de paginación.
Haga clic en “Click to paginate” en el flujo de trabajo, use exactamente la misma configuración que el desplazamiento automático
4) Eso es todo. ¡Estás listo! ¿No es esto demasiado bueno para ser verdad? Ejecutemos el crawler y veamos si funciona.
Haga clic en “Start Extraction” en la esquina superior izquierda. Elija “extracción local”. Básicamente significa que ejecutará el crawler en su propia computadora en lugar del servidor de la nube. [Descargue el archivo del crawler utilizado en este ejemplo y pruébelo usted mismo]
Ejemplo 2: Scrape imágenes de tamaño completo
Pregunta: ¿Qué sucede si necesita imágenes de tamaño completo?
Para este ejemplo, utilizaremos el mismo sitio web: https://pixabay.com/images/search/dogs/ para demostrar cómo puede obtener imágenes de tamaño completo.
1) Inicie una nueva tarea haciendo clic en “+ Task” en el modo Avanzado.
2) Ingrese la URL de la página web de destino en el cuadro de texto y luego haga clic en “Save URL” para continuar.
3) A diferencia del ejemplo anterior donde (podíamos capturar las imágenes directamente), ahora necesitaremos hacer clic en cada imagen individual para ver/captuar la imagen a tamaño completo.
Haga clic en la primera imagen, el panel de Consejos de acción debería leer “Image selected, 100 similar images found”.
Seleccione “Elegir todos elementos similares“.
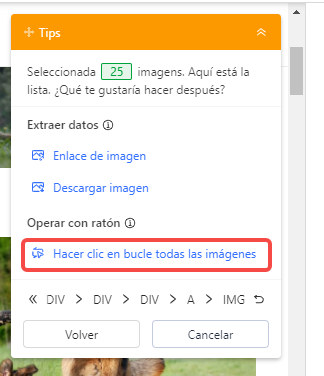
Luego, “Hacer clic en bucle todas las imágenes“.
4) Ahora que tenemos a la página con la imagen a tamaño completo, las cosas son mucho más fáciles.
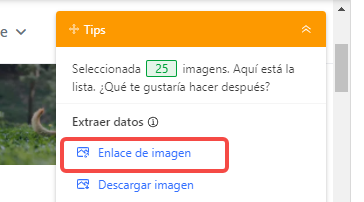
Haga clic en la imagen a tamaño completo, luego seleccione “Extract the URL of the selected image”.
Como siempre, verifique el panel de datos y asegúrese de que los datos deseados se hayan extraído correctamente.
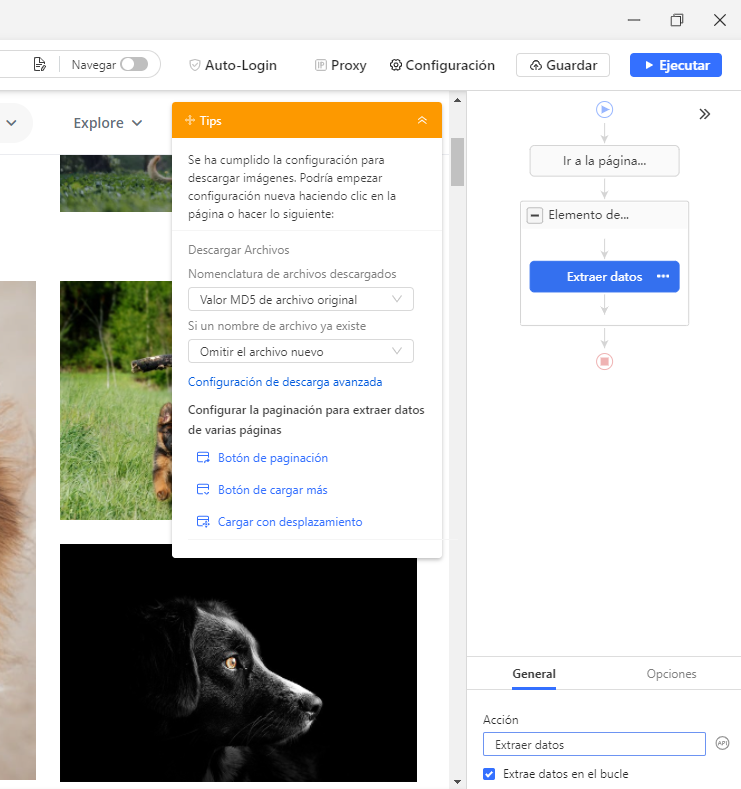
5) Siga los mismos pasos en el Ejemplo 1 para agregar pasos de paginación.
Haga clic en “Go to the webpage”, ubique el botón “Next page” y luego haga clic en él. Seleccione “Loop clicked the selected link” en el panel “Action Tips”.
6) ¡Listo! Prueba ejecutar el crawler. [Descargue el archivo del crawler utilizado en este ejemplo y pruébelo usted mismo]
Ejemplo 3: Obtener imagen a tamaño completo de la miniatura
Estoy seguro de que ha visto algo similar cuando compra en línea o si tiene una tienda en línea. Para las imágenes de productos, las imágenes en miniatura son definitivamente las formas más comunes de visualización de imágenes. El uso de miniaturas reduce sustancialmente el ancho de banda y el tiempo de carga, lo que hace que sea mucho más amigable para las personas navegar a través de diferentes productos.
Hay dos formas de extraer las imágenes de tamaño completo de las miniaturas usando Octoparse.
Opción 1– Puede configurar un clic de bucle para hacer clic en cada una de las miniaturas y luego extraer la imagen a tamaño completo una vez cargada.
Opción 2– Como la mayoría de las imágenes en miniatura comparten exactamente el mismo patrón de URL con el de las imágenes de tamaño completo correspondientes, pero solo con un número diferente indicativo de los diferentes tamaños, tiene sentido extraer la URL de la miniatura y luego reemplazar el número de tamaño de la miniatura a ese de las contrapartes de tamaño completo. Esto se puede hacer fácilmente con la herramienta de limpieza de datos integrada de Octoparse.
Como ya hemos visto algo similar a la Opción 1 en el Ejemplo 2, elaboraré la Opción 2 en este ejemplo. Usaremos una página de producto en Flipcart.com para demostrarlo.
Antes de comenzar el trabajo, vale la pena confirmar si esta táctica se puede aplicar mirando la URL de la imagen para la miniatura y su contraparte de tamaño completo. Así que elegí una de las miniaturas para verificar.
| Thumbnail URL: https://rukminim1.flixcart.com/image/128/128/jatym4w0/speaker/mobile-tablet-speaker/v/u/7/philips-in-bt40bk-94-original-imafybc9ysphpzhv.jpeg?q=70Full-size URL: https://rukminim1.flixcart.com/image/416/416/jatym4w0/speaker/mobile-tablet-speaker/v/u/7/philips-in-bt40bk-94-original-imafybc9rqhdna8z.jpeg?q=70 |
Observe que la única diferencia entre estas dos URL es el número indicativo del tamaño de la imagen. “128” para la miniatura y “416” para la imagen a tamaño completo. Esto significa que después de extraer la URL de la miniatura, simplemente reemplace “128” con “416” para convertir la miniatura a una URL de tamaño completo. Vamos a verlo en acción.
1) Inicie la aplicación Octoparse, inicie una nueva tarea, luego ingrese la URL de destino en el cuadro de texto.
2) Haga clic en la primera imagen en miniatura. El panel de Action Tips ahora lee “Element selected. 5 similar buttons found”. ¡Bravo! Octoparse reconoció las miniaturas restantes automáticamente.
Seleccione “Seleccionar todo”.
Luego, seleccione “Extract the text of the selected elements”. Obviamente, esto no es lo que queremos, pero podemos cambiarlo más tarde.
Mueva el interruptor “Workflow” en la esquina superior derecha. Tenga en cuenta que no teníamos extraído nada.
Bueno, esto es de esperarse ya que aparentemente no hubo texto para extraer. Lo que realmente necesitamos obtener es la URL de la imagen oculta en el código fuente HTML. Entonces ahora necesitaremos cambiar el tipo de datos a extraer.
3) Presione el ícono “Customize” (lápiz pequeño)![]() en la parte inferior, haga clic en “Define data extracted”, marque “Extract outer HTML, including source code, text for format and image”. Haga clic en “OK” para guardar.
en la parte inferior, haga clic en “Define data extracted”, marque “Extract outer HTML, including source code, text for format and image”. Haga clic en “OK” para guardar.
4) Haga clic en el icono ![]() “Customize” nuevamente. Esta vez, haga clic en “Refine extracted data”. Hay un par de pasos de limpieza de datos para agregar.
“Customize” nuevamente. Esta vez, haga clic en “Refine extracted data”. Hay un par de pasos de limpieza de datos para agregar.
Haga clic en “Add step”, luego seleccione “Coincidir con expresión regular”. Si no está familiarizado con la expresión regular, siéntase libre de usar la herramienta RegEx  incorporada que me gusta mucho.
incorporada que me gusta mucho.
La herramienta RegEx es bastante autoexplicativa. Ingrese el comienzo y el final de la cadena de datos deseada. Haga clic en “Generate” y luego se genera la expresión regular correspondiente. Haga clic en “Match” para ver si los datos deseados pueden coincidir con éxito. Si espera obtener más de una línea coincidente, marque “Match all”.
5) ¿Hemos terminado? Cerca, pero aún no. Recuerde que esta es solo la URL en miniatura y aún necesitamos reemplazar “128” con “416” para convertirlas en las URL de imagen de tamaño completo.
Haga clic en “Add step” una vez más. Seleccione “Replace”. Reemplace “128” con “416”. Haga clic en “Evaluar”. Finalmente, tenemos la URL que necesitamos.
Verifique los datos extraídos.
6) Ejecute la prueba del crawler
En el ejemplo anterior, extrajimos cada URL de imagen como una fila individual. ¿Qué sucede si necesita extraer todas las URL juntas? Esto se puede hacer extrayendo el HTML externo de todas las miniaturas a la vez. Luego, use RegEx para hacer coincidir las URL individuales, reemplace el número de tamaño, luego obtendrá todas las URL de imágenes de tamaño completo obtenidas en una sola fila.
1) Cargue el sitio web y haga clic en una de las miniaturas. Haga clic en el icono “Expand” en la esquina inferior derecha del panel Consejos de acción hasta que toda la sección de miniaturas se resalte en verde, lo que básicamente significa que están seleccionados.
2) Seleccione “Extraer HTML externo del elemento seleccionado” en el panel Action Tips.
3) Vuelva al modo de flujo de trabajo .
Repita los mismos pasos de limpieza de datos para hacer coincidir las URL de las miniaturas individuales.
Marque “Match All” esta vez, ya que necesitamos hacer coincidir más de una URL del código HTML extraído.
Nuevamente, reemplace “128” con “416”. Por último, tenemos todas las URL de imágenes de tamaño completo extraídas en una sola línea. [Descargue el archivo del crawler utilizado en este ejemplo y pruébelo usted mismo]
Ahora que hemos extraído las URL de las imágenes, vamos a obtener los archivos de imágenes reales descargados utilizando una de mis herramientas favoritas, TabSave. También hay otros descargadores de imágenes similares disponibles en la web y la mayoría de ellos son gratuitos.
1) Exportar los datos extraídos a Excel o formatos similares.
2) Copie y pegue las URL de las imágenes en TabSave.
3) Comience a descargar los archivos haciendo clic en el icono de descarga en la parte inferior.
Conclusión
Espero que este tutorial le brinde un buen comienzo para extraer imágenes/datos de la web. Dicho esto, cada sitio web es diferente. Dependiendo de los sitios web de destino, pueden ser necesarios algunos ajustes para que funcione. Sin embargo, el concepto general y el flujo de trabajo se pueden extender a la mayoría de los sitios web. Si tiene alguna pregunta sobre cómo configurar un crawler dentro de Octoparse, siempre puede consultar el Centro de ayuda de Octoparse o comunicarse con support@octoparse.com.




