Un web scraper (web crawler) es una herramienta o un fragmento de código que realiza el proceso para extraer datos de páginas web en Internet. Varios web scraper han jugado un papel importante en el auge de los grandes datos y facilitan a las personas raspar los datos que necesitan.
Entre varios webs scraper, los de open source(código abierto) permiten a los usuarios codificar en función de su código fuente o marco, y alimentan una parte masiva para ayudar a raspar de una manera rápida, simple pero extensa. Veamos las 10 mejores herramientas de web scraping de código abierto en 2024.
¿Qué es un Web Scraper de Código Abierto?
Antes de aprender acerca de la parte superior de código abierto raspadores web, usted puede aprender la mejor alternativa de ellos que puede raspar los datos sin ningún tipo de conocimientos de codificación. Los raspadores web de código abierto permiten a los usuarios codificar basándose en su código fuente o framework, pero también tienen sus límites. Especialmente para los usuarios que no saben codificar, es difícil de hacer con la personalización y lleva mucho tiempo. Por lo tanto, es necesaria una alternativa para el raspador web de código abierto.
Mejor Web Scraper sin Código
Octoparse, como una herramienta de raspado web fácil de usar, puede extraer datos de cualquier sitio web a Excel con auto-detectar o plantillas preestablecidas. Puede terminar todo el proceso de raspado en unos pocos clics, aunque no sepa nada de codificación.
Sin embargo, Octoaprse también es adecuado para aquellos que tienen conocimientos de codificación, ya que proporciona funciones avanzadas para personalizar sus necesidades de raspado de datos.
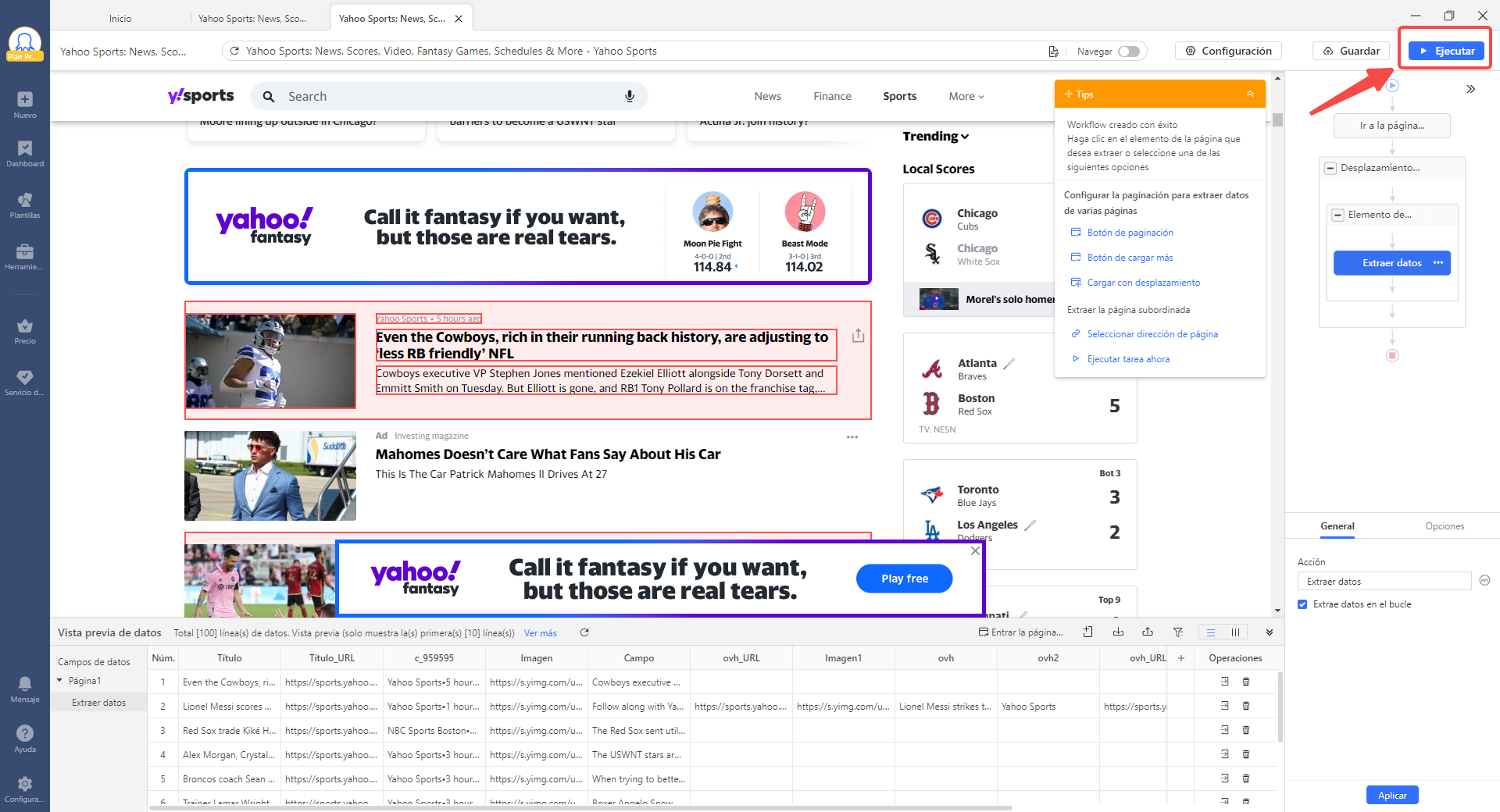
Pruebe el raspador de datos de correo electrónico y redes sociales preestablecido en línea que se muestra a continuación sin descargar ningún software, y sólo tiene que introducir los parámetros que le pide después de haber previsualizado la muestra de datos.
https://www.octoparse.es/template/email-social-media-scraper
Los TOP 10 Web Scraper de Open Source
1. Scrapy

Lenguaje: Python
Scrapy es la herramienta de web scraping colaborativa y de código abierto más popular en Python. Ayuda a extraer datos de manera eficiente de los sitios web, los procesa según lo necesite y los almacena en su formato preferido (JSON, XML y CSV). Está construido sobre un marco de red asincrónico retorcido que puede aceptar solicitudes y procesarlas más rápido. Con Scrapy, podrá manejar grandes proyectos de raspado web de una manera eficiente y flexible.
Ventajas:
- Rápido y potente
- Fácil de usar con documentación detallada
- Capacidad para conectar nuevas funciones sin tener que tocar el núcleo
- Una comunidad saludable y abundantes recursos.
- Entorno en la nube para ejecutar los scrapers
2. Heritrix

Lenguaje: JAVA
Heritrix es un scraper de código abierto basado en JAVA con alta extensibilidad y diseñado para el archivo web. Respeta altamente las directivas de exclusión robot.txt y Meta robot tags y recopila datos a un ritmo adaptado y medido que es poco probable que interrumpa las actividades normales del sitio web. Proporciona una interfaz de usuario basada en la web accesible con un navegador web para el control del operador y el monitoreo de los rastreos.
Ventajas:
- Módulos reemplazables enchufables
- Interfaz basada en web
- Respeto a robot.txt y Meta robot tags
- Excelente extensibilidad
3. Web-Harvest

Lenguaje: JAVA
Web-Harvest es un scraper de código abierto escrito en Java. Puede recopilar datos útiles de páginas específicas. Para hacerlo, utiliza principalmente técnicas y tecnologías como XSLT, X Query y Expresiones regular para operar o filtrar contenido de sitios web basados en HTML/XML. Podría complementarse fácilmente con bibliotecas Java personalizadas para aumentar sus capacidades de extracción.
Ventajas:
- Potentes procesadores de texto y manipulación de XML para el manejo de datos y el flujo de control
- El contexto variable para almacenar y usar variables
- Se admiten lenguajes de script reales, que se pueden integrar fácilmente en configuraciones de raspador
4. MechanicalSoup

Lenguaje: Python
MechanicalSoup es una biblioteca de Python diseñada para simular la interacción del ser humano con los sitios web cuando se usa un navegador. Fue construido alrededor de Python giants Requests (para sesiones HTTP) y BeautifulSoup (para navegación de documentos). Almacena y envía cookies automáticamente, sigue los redireccionamientos y sigue los enlaces y envía formularios. Si intenta simular comportamientos humanos como esperar un determinado evento o hacer clic en ciertos elementos en lugar de simplemente raspar datos, MechanicalSoup es realmente útil.
Ventajas:
- Capacidad para simular el comportamiento humano
- Ardiente rápido para scraping sitios web bastante simples
- Admite selectores CSS y XPath
5. Apify SDK

Lenguaje: JavaScript
Apify SDK es uno de los mejores web scrapers incorporado en JavaScript. La biblioteca de scraping escalable permite el desarrollo de trabajos de extracción de datos y automatización web con headless Chrome y Puppeteer. Con sus poderosas herramientas únicas como RequestQueue y AutoscaledPool, puede comenzar con varias URL y seguir de forma recursiva enlaces a otras páginas y puede ejecutar las tareas de scraping a la capacidad máxima del sistema, respectivamente.
Ventajas:
- Scrape con gran escala y alto rendimiento
- Apify Cloud con un grupo de servidores proxy para evitar la detección
- Soporte incorporado de complementos de Node.js como Cheerio y Puppeteer
6. Apache Nutch

Lenguaje: JAVA
Apache Nutch, otro rascador de código abierto codificado completamente en Java, tiene una arquitectura altamente modular, lo que permite a los desarrolladores crear complementos para el análisis de tipo de medios, recuperación de datos, consultas y agrupación. Al ser enchufable y modular, Nutch también proporciona interfaces extensibles para implementaciones personalizadas.
Ventajas:
- Altamente extensible y escalable
- Obedecer las reglas txt
- Comunidad vibrante y desarrollo activo
- Análisis, protocolos, almacenamiento e indexación enchufables
7. Jaunt

Lenguaje: JAVA
Jaunt, basado en JAVA, está diseñado para el web scraping, la automatización web y las consultas JSON. Ofrece un navegador rápido, ultraligero y headless browser que proporciona funcionalidad de raspado web, acceso al DOM y control sobre cada solicitud/respuesta HTTP, pero no es compatible con JavaScript.
Ventajas:
- Procesar solicitudes/respuestas HTTP individuales
- Fácil interfaz con las API REST
- Soporte para HTTP, HTTPS y autenticación básica
- Consulta habilitada para RegEx en DOM y JSON
8. Node-crawler

Lenguaje: JavaScript
Node-crawler es un web crawler potente, popular y de producción basado en Node.js. Está completamente escrito en Node.js y admite de forma non-blocking asynchronous I/O, lo que proporciona una gran comodidad para el mecanismo de operación de la tubería del crawler. Al mismo tiempo, admite la selección rápida de DOM (no es necesario escribir expresiones regulares) y mejora la eficiencia del desarrollo del rastreador.
Ventajas:
- Control de clasificación
- Diferentes prioridades para solicitudes de URL
- Tamaño de agrupación configurable y reintentos
- Server-side DOM e automatic jQuery inserción con Cheerio (default) o JSDOM
9. PySpider
Lenguaje: Python
PySpider es un poderoso sistema de web crawler en Python. Tiene una interfaz de usuario web fácil de usar y una arquitectura distribuida con componentes como planificador, captador y procesador. Admite varias bases de datos, como MongoDB y MySQL, para el almacenamiento de datos.
Ventajas:
- Potente interfaz de usuario web con editor de scripts, monitor de tareas, administrador de proyectos y visor de resultados
- RabbitMQ, Beanstalk, Redis, y Kombu como la cola de mensajes
- Arquitectura distribuida
10. StormCrawler

Lenguaje: JAVA
StormCrawler es un web crawler de código abierto completo. Consiste en una colección de recursos y componentes reutilizables, escritos principalmente en Java. Se utiliza para construir soluciones de raspado web optimizadas, de baja latencia y en Java y también es perfectamente adecuado para servir flujos de entradas donde las URL se envían a través de flujos para el crawler.
Ventajas:
- Altamente escalable y se puede usar para rastreos recursivos a gran escala
- Fácil de ampliar con bibliotecas adicionales
- Excelente gestión de hilos que reduce la latencia del rastreo
Conclusión
Los web scraper de código abierto son bastante potentes y extensibles, pero están limitados a los desarrolladores. Hay muchas herramientas sin codificación como Octoparse, lo que hace que el scraping ya no sea un privilegio para los desarrolladores. Si no dominas la programación, estas herramientas serán más adecuadas y te facilitarán el scraping.

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.



