Entrenar un modelo de IA no empieza con el algoritmo.
Empieza con los datos.
En la mayoría de los proyectos de inteligencia artificial, más del 70% del tiempo se dedica a recopilar, limpiar y estructurar información antes del entrenamiento.
Si quieres crear un modelo de clasificación, predicción o un chatbot entrenado con datos específicos, necesitas primero construir un dataset sólido.
En esta guía te mostramos 10 herramientas esenciales con ejemplos prácticos para recopilar y preparar datos para entrenar modelos de IA en 2026.
¿Por qué los datos determinan el éxito de un proyecto de IA?
En la mayoría de los proyectos empresariales, el entrenamiento técnico del modelo no es el principal obstáculo. El verdadero desafío aparece mucho antes: en la construcción del dataset.
Pensemos en el caso de una empresa de ecommerce que decide entrenar un modelo de IA multilingüe para analizar automáticamente las opiniones de sus clientes en España, México y Brasil. El objetivo es detectar patrones de insatisfacción, identificar problemas recurrentes en productos y anticipar riesgos reputacionales.
En teoría, el planteamiento es simple. En la práctica, la empresa descubre que la mayor parte de las reseñas están en español, mientras que el volumen en portugués es mucho menor. Además, los formatos no son consistentes, algunas valoraciones están duplicadas, y abundan abreviaturas, errores ortográficos y expresiones locales que cambian el significado del texto.
El modelo no falla por falta de potencia técnica. Falla porque los datos no representan de forma equilibrada la realidad del mercado.
Si el entrenamiento se realiza con este conjunto de datos sin limpieza ni normalización, el sistema tenderá a interpretar mejor los patrones del mercado dominante y mostrará sesgos en los demás países. El resultado no será inteligencia artificial estratégica, sino automatización de errores.
Por eso, antes de elegir un framework de entrenamiento, la prioridad debe ser garantizar que los datos estén correctamente recopilados, estructurados y actualizados. En proyectos reales, la ventaja competitiva no suele estar en el algoritmo más sofisticado, sino en la calidad del dataset que lo alimenta.
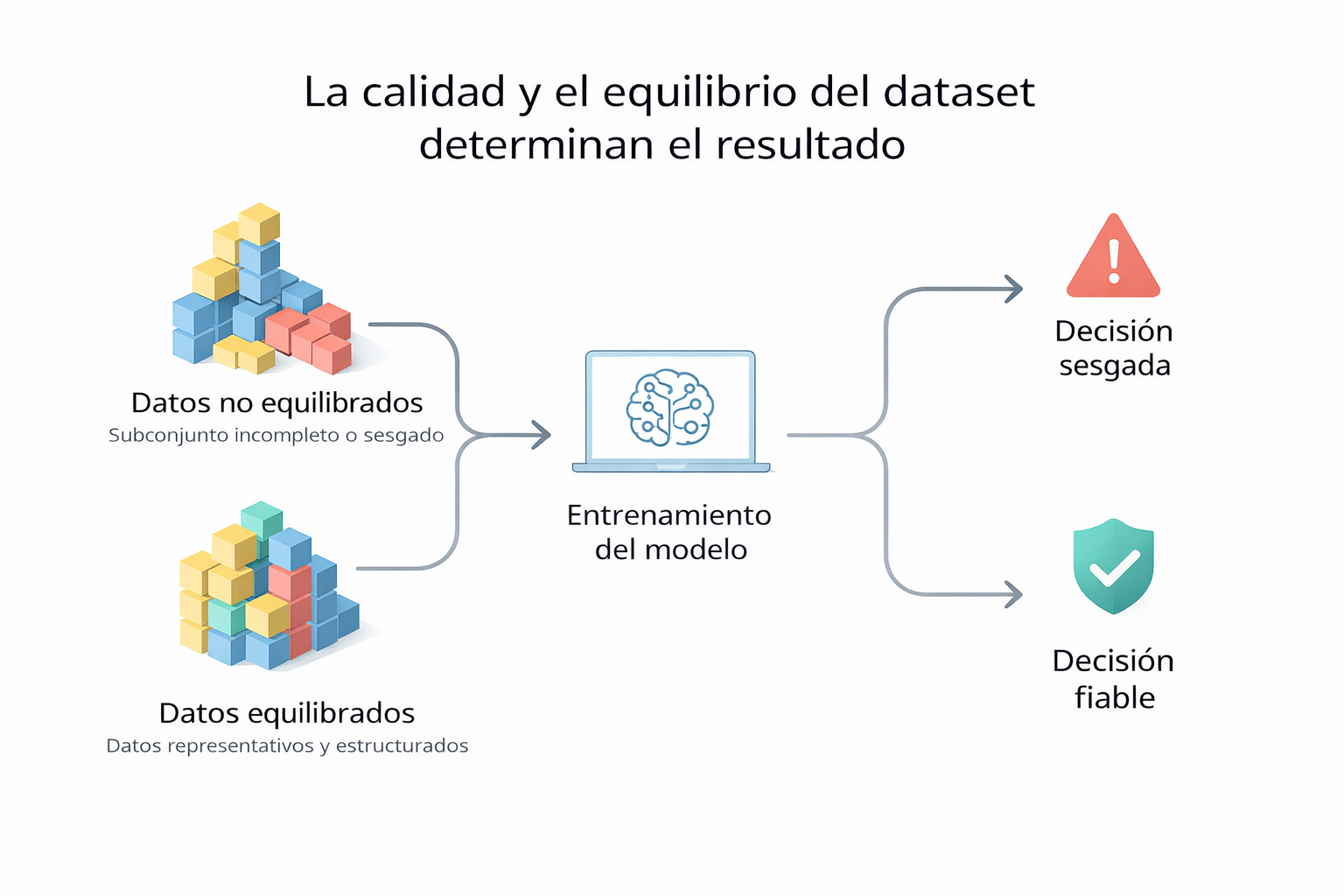
Comparación rápida y visión global del ecosistema de entrenamiento de IA
Antes de analizar cada herramienta en detalle, conviene entender cómo encajan dentro de un proyecto real de inteligencia artificial.
Muchas veces se habla únicamente del modelo —TensorFlow, PyTorch o cualquier framework de entrenamiento— como si fuera el elemento central. Sin embargo, el entrenamiento es solo una fase dentro de un flujo mucho más amplio que comienza mucho antes, en la recopilación y preparación de datos, y continúa después, en la escalabilidad y despliegue.
Algunas herramientas están orientadas al modelado avanzado, otras a la limpieza de datos, otras a la exploración previa y otras a la infraestructura. Comprender esta diferencia es clave para elegir correctamente en función del objetivo del proyecto.
En la siguiente tabla encontrarás una comparación rápida de las principales herramientas utilizadas en cada etapa del proceso. Esto permite identificar de forma inmediata:
- En qué fase interviene cada solución
- Qué nivel técnico requiere
- Qué tipo de datos maneja
- Para qué tipo de proyecto resulta más adecuada
| Herramienta | Fase del proyecto | Nivel técnico | Tipo de datos | Escalabilidad | Uso principal |
|---|---|---|---|---|---|
| TensorFlow | Entrenamiento avanzado | Alto | Estructurados y no estructurados | Alta | Redes neuronales profundas |
| PyTorch | Experimentación y prototipado | Alto | Texto, imagen, multimodal | Media–Alta | Investigación y modelos personalizados |
| Scikit-learn | Modelos predictivos clásicos | Medio | Datos estructurados | Media | Clasificación y regresión empresarial |
| Cloud AI (AWS, GCP, Azure) | Infraestructura y despliegue | Medio–Alto | Grandes volúmenes | Muy alta | Escalabilidad y producción |
| Excel / Power BI | Exploración y validación | Bajo–Medio | Datos estructurados | Baja | Análisis exploratorio |
| Pandas | Limpieza y transformación | Medio | Datos estructurados | Media | Preparación técnica del dataset |
| Kaggle | Práctica y experimentación | Bajo–Medio | Públicos | Media | Aprendizaje y benchmarking |
| APIs oficiales | Recopilación estructurada | Medio | Datos estructurados | Media | Acceso controlado a datos |
| Herramientas de recopilación web | Construcción de datasets propios | Medio | Datos públicos web | Alta | Extracción y estructuración |
| Data labeling tools | Etiquetado supervisado | Medio | Texto, imagen, audio | Media | Preparación para modelos supervisados |
Además, el esquema posterior muestra el flujo completo de un proyecto de entrenamiento de IA, desde la recopilación de datos hasta el despliegue del modelo en producción.

Esta visión global ayuda a evitar uno de los errores más comunes en proyectos de inteligencia artificial: centrarse exclusivamente en el algoritmo sin haber definido correctamente la estrategia de datos.
Con este contexto claro, a continuación analizamos cada herramienta en profundidad y su papel dentro del ecosistema de entrenamiento de modelos de IA con ejemplos prácticos.
Herramientas para entrenar modelos de IA
1. TensorFlow
TensorFlow es uno de los frameworks más robustos para entrenar modelos de deep learning en proyectos empresariales a gran escala. Desarrollado originalmente por Google, permite construir arquitecturas complejas capaces de procesar grandes volúmenes de datos estructurados y no estructurados.
¿Qué problema resuelve?
TensorFlow es especialmente útil cuando se requiere:
- Procesar millones de registros
- Entrenar redes neuronales profundas
- Implementar modelos en entornos productivos
- Escalar el entrenamiento en múltiples servidores
Es una solución orientada a proyectos donde la infraestructura y el volumen de datos son factores críticos.
Ejemplo práctico:
Una empresa fintech que opera en varios países decide entrenar un modelo para detectar transacciones sospechosas en tiempo real. Dispone de millones de registros históricos con datos como importe, ubicación, dispositivo y comportamiento previo del cliente.
El volumen parece suficiente, pero durante la preparación del dataset aparecen problemas comunes: registros duplicados, monedas no normalizadas, formatos de fecha inconsistentes y un claro desequilibrio entre transacciones legítimas y fraudulentas.
Si el modelo se entrena sin corregir estos puntos, aumentarán los falsos positivos o se ignorarán patrones minoritarios. En este escenario, TensorFlow aporta la potencia técnica, pero el rendimiento final depende mucho más de la calidad y el equilibrio del dataset que de la arquitectura elegida.
Nivel técnico requerido
Alto. Requiere conocimientos de Python, matemáticas básicas de machine learning y experiencia en manipulación de datos.
Recurso para aprender
- Documentación oficial en tensorflow.org
- Cursos prácticos en YouTube como “TensorFlow tutorial for beginners”
- Notebooks interactivos en plataformas como Kaggle
2. PyTorch
PyTorch es uno de los frameworks más utilizados en investigación y desarrollo de modelos avanzados de inteligencia artificial. Su enfoque dinámico y flexible permite experimentar con arquitecturas complejas de forma más intuitiva que otros entornos tradicionales.
A diferencia de soluciones más orientadas a producción masiva, PyTorch suele ser la elección de equipos que necesitan iterar rápidamente y probar nuevas ideas antes de escalar el modelo.
Ejemplo práctico:
Un laboratorio interno de una empresa de retail digital desarrolla un modelo de visión artificial para detectar automáticamente defectos en imágenes de productos enviadas por proveedores. El objetivo no es solo entrenar un clasificador, sino comparar distintas arquitecturas y ajustar hiperparámetros para mejorar la precisión en categorías como electrónica o moda.
PyTorch resulta especialmente útil en este entorno porque permite modificar componentes del modelo y experimentar con nuevas configuraciones sin rehacer todo el proceso desde cero.
Sin embargo, durante las pruebas surge un desafío habitual: algunas categorías cuentan con miles de imágenes, mientras que otras apenas disponen de unas pocas decenas. A ello se suman diferencias en iluminación y calidad visual. El resultado es un modelo que funciona bien donde hay volumen suficiente, pero pierde precisión en categorías con menor representación.
Así, aunque PyTorch facilita la experimentación técnica, el rendimiento final vuelve a depender del equilibrio y la consistencia del dataset más que de la arquitectura elegida.
Nivel técnico requerido
Alto. Es necesario dominar Python y comprender conceptos avanzados de machine learning y deep learning.
Recurso para aprender
- Documentación oficial en pytorch.org
- Tutoriales prácticos en YouTube como “PyTorch NLP tutorial”
- Proyectos open source disponibles en GitHub
3. Scikit-learn
Scikit-learn es una de las bibliotecas más utilizadas para proyectos de machine learning basados en datos estructurados. A diferencia de frameworks orientados al deep learning, está diseñada para trabajar con tablas, variables numéricas y modelos estadísticos clásicos.
Es una herramienta especialmente popular en equipos de análisis de negocio y departamentos de datos que necesitan implementar modelos predictivos sin entrar en arquitecturas complejas.
Ejemplo práctico:
Una empresa de logística busca anticipar posibles retrasos en sus entregas para mejorar la planificación operativa. Para ello, el equipo de análisis trabaja con datos históricos como la distancia del envío, el tipo de producto, las condiciones climáticas, el día de la semana y los tiempos promedio por región.
Con esta información estructurada desarrollan un modelo de regresión utilizando Scikit-learn para estimar la probabilidad de retraso en cada caso. El proyecto no requiere arquitecturas complejas ni infraestructuras de alto coste, pero sí depende de que los datos estén correctamente preparados: las variables deben estar codificadas de forma consistente, los registros atípicos deben filtrarse y el conjunto de entrenamiento debe reflejar adecuadamente tanto entregas normales como retrasadas.
Cuando estas condiciones se cumplen, el modelo ofrece resultados sólidos y, sobre todo, fácilmente interpretables por el equipo de operaciones, que puede utilizar las predicciones para ajustar rutas y recursos.
Limitaciones y posibles desafíos
Sin embargo, Scikit-learn no es la mejor opción cuando:
- Se trabaja con imágenes o audio
- Se necesitan modelos de deep learning complejos
- El volumen de datos es extremadamente grande
- Se requiere entrenamiento distribuido a gran escala
Además, al depender principalmente de datos estructurados, cualquier inconsistencia en columnas, formatos o categorías puede afectar directamente el rendimiento del modelo.
En proyectos empresariales, la simplicidad de Scikit-learn es una ventaja, pero también impone límites en escenarios más avanzados.
Nivel técnico requerido
Medio. Se necesita conocimiento básico de Python y comprensión de conceptos estadísticos como regresión, clasificación y validación cruzada.
4. Google Cloud AI / AWS SageMaker / Azure ML
Las plataformas cloud de inteligencia artificial permiten entrenar y desplegar modelos sin necesidad de mantener infraestructura propia. Son especialmente relevantes cuando el volumen de datos supera la capacidad de un entorno local o cuando el proyecto requiere escalabilidad.
Ejemplo práctico:
Una aseguradora desarrolla un modelo para evaluar riesgos en tiempo real utilizando millones de registros históricos de pólizas y siniestros. Para entrenar y probar distintas versiones del modelo sin invertir en infraestructura propia, el equipo recurre a una plataforma cloud como AWS SageMaker.
La escalabilidad y la capacidad de cómputo aceleran la experimentación. Sin embargo, el principal desafío no está en la potencia técnica, sino en la gestión del pipeline de datos: integrar múltiples fuentes, controlar versiones del dataset y mantener coherencia entre entornos.
Las plataformas cloud facilitan el entrenamiento y despliegue, pero no reemplazan la necesidad de una estructura de datos sólida antes de iniciar el proceso.
Insight clave
En proyectos a gran escala, la infraestructura deja de ser el principal problema. La coherencia y trazabilidad del dataset se convierten en el factor crítico para evitar errores costosos en producción.
5. Power BI y Excel
Aunque no están diseñados para entrenar modelos directamente, Power BI (¿Qué es Power BI?) y Excel siguen desempeñando un papel clave en la fase previa de cualquier proyecto de IA.
Ejemplo práctico:
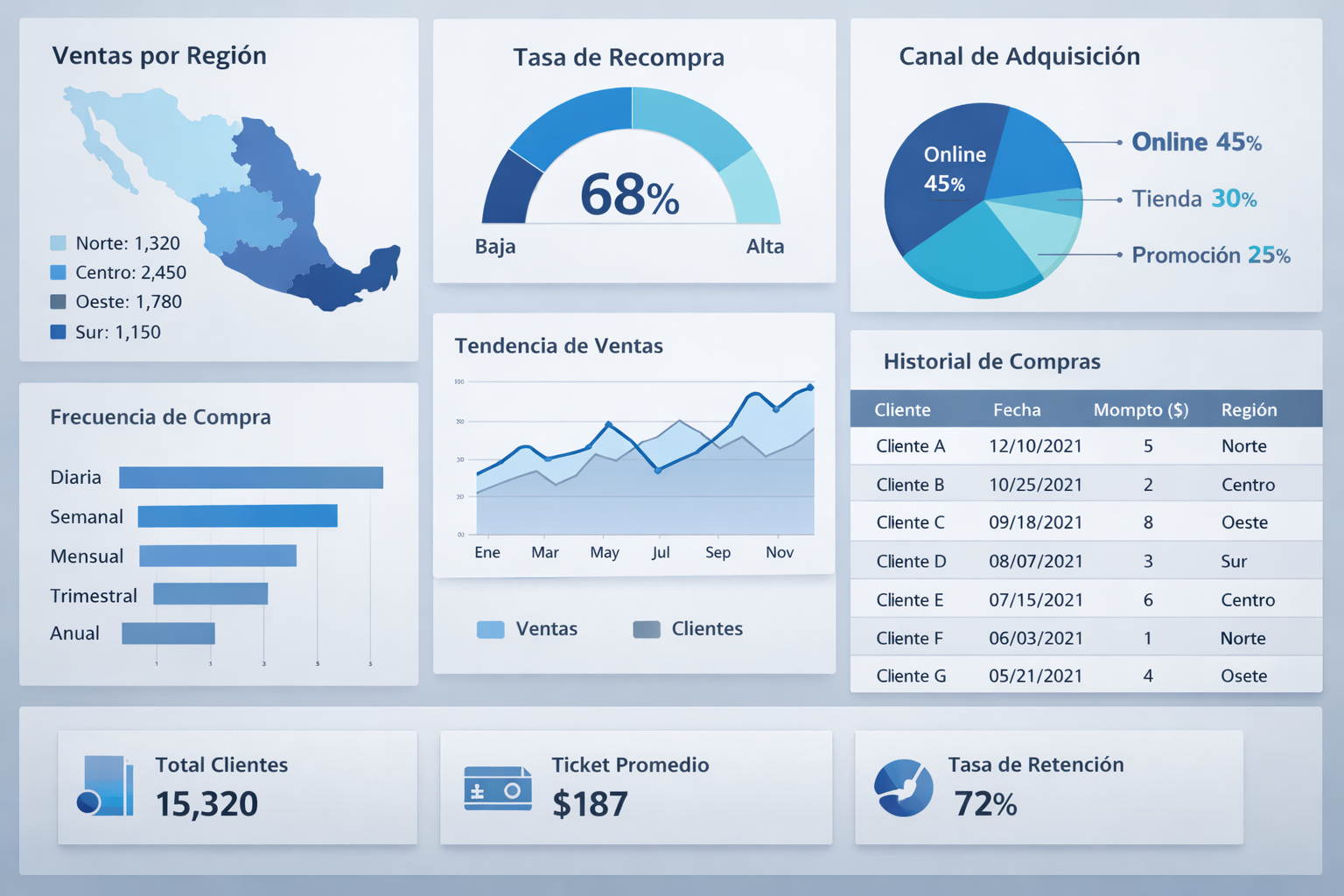
Un equipo de marketing quiere desarrollar un modelo predictivo para estimar la probabilidad de recompra de clientes. Antes de entrenar cualquier algoritmo, comienza analizando el comportamiento histórico en Excel: frecuencia de compra, ticket promedio, canal de adquisición y segmentación por región.
Durante esta fase exploratoria detectan inconsistencias en los datos, valores faltantes y duplicaciones que podrían distorsionar cualquier modelo posterior. Utilizan tablas dinámicas, filtros y visualizaciones en Power BI para comprender patrones antes de exportar el dataset limpio al entorno de entrenamiento.
Aunque estas herramientas no construyen el modelo, permiten validar hipótesis, detectar anomalías y asegurar que los datos tengan coherencia interna.
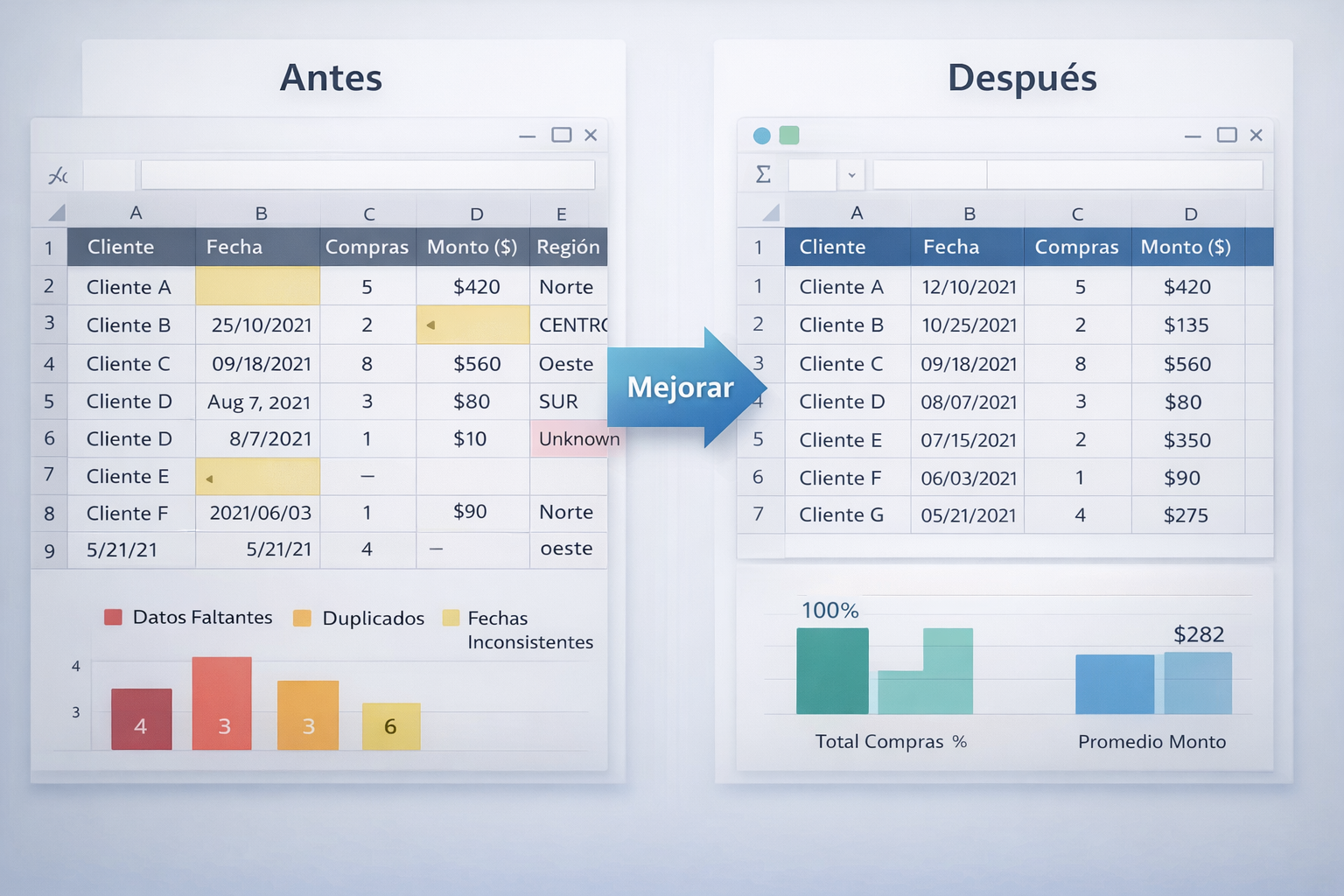
Limitaciones
No están pensadas para manejar grandes volúmenes ni para automatizar flujos complejos de datos. Cuando el dataset crece o requiere actualización continua, es necesario integrar soluciones más avanzadas.
Insight clave
Muchas veces, los errores del modelo no se originan en el algoritmo, sino en una fase exploratoria insuficiente. Comprender los datos antes de entrenar puede ahorrar semanas de ajustes posteriores.
6. Pandas (Python)
Pandas es una biblioteca fundamental para la manipulación y transformación de datos en Python. En la práctica, actúa como puente entre la recopilación y el entrenamiento.
Ejemplo práctico:
Una empresa de análisis inmobiliario quiere entrenar un modelo para estimar precios de alquiler en distintas ciudades. Ha recopilado datos desde múltiples fuentes online, pero los formatos no son homogéneos: algunas columnas contienen texto donde deberían ser numéricas, existen valores faltantes y ciertas categorías están escritas de formas distintas.
Con Pandas, el equipo puede normalizar formatos, convertir tipos de datos, eliminar registros inconsistentes y unificar categorías antes de alimentar el modelo.
Este proceso no es visible en la fase final del proyecto, pero determina directamente la estabilidad del entrenamiento.
Limitaciones
Pandas es potente, pero depende completamente del criterio del analista. Si la limpieza se realiza sin una metodología clara, se pueden introducir nuevos sesgos o eliminar información relevante por error.
Además, cuando el volumen de datos crece significativamente, puede requerir herramientas complementarias para procesamiento distribuido.
Insight clave
La preparación manual o semiautomática con Pandas suele ser el punto donde realmente se define la calidad del dataset. No es la parte más visible del proyecto, pero sí una de las más determinantes.
7. Kaggle Datasets
Kaggle es una plataforma ampliamente utilizada para acceder a datasets públicos y participar en competiciones de machine learning. Para muchos profesionales, es el punto de partida para experimentar y validar modelos.
Ejemplo práctico
Un analista que quiere desarrollar un modelo de predicción de precios inmobiliarios descarga un dataset público desde Kaggle que incluye información sobre superficie, ubicación, número de habitaciones y año de construcción.
El entorno es ideal para probar algoritmos y comparar métricas rápidamente. Sin embargo, pronto surge una limitación: el dataset no refleja las particularidades del mercado local ni incluye variables relevantes para su negocio específico.
El modelo puede funcionar bien en el entorno de prueba, pero pierde precisión cuando se enfrenta a datos reales.
Limitaciones
- Los datasets públicos no siempre están actualizados
- Pueden no representar tu mercado específico
- No incluyen variables estratégicas internas
Insight clave
Kaggle es excelente para aprender y experimentar, pero rara vez sustituye la necesidad de construir un dataset propio alineado con los objetivos del negocio.
8. APIs oficiales
Muchas plataformas digitales ofrecen APIs para acceder a datos estructurados de forma controlada y documentada.
Ejemplo práctico
Una empresa que analiza tendencias en redes sociales utiliza la API oficial de una plataforma para recopilar métricas de interacción, publicaciones y crecimiento de cuentas.
La ventaja es clara: los datos llegan en formato estructurado y con menor riesgo de inconsistencias técnicas. Sin embargo, el acceso suele estar sujeto a límites de solicitudes, restricciones de uso o acceso parcial a información crítica.
En algunos casos, ciertos campos no están disponibles a través de la API o requieren niveles avanzados de suscripción.
Limitaciones
- Límites de uso
- Costes asociados
- Acceso restringido a determinados datos
Insight clave
Las APIs son una fuente estable y estructurada, pero dependen de las políticas del proveedor. Cuando el modelo requiere información más específica o granular, pueden resultar insuficientes.
9. Herramientas de recopilación de datos web
Cuando los datos están disponibles públicamente en sitios web pero no en formato descargable o vía API, es necesario estructurarlos antes del entrenamiento.
Ejemplo práctico
Una empresa de análisis de mercado quiere entrenar un modelo para detectar tendencias de precios en marketplaces internacionales. La información relevante —precios, valoraciones, categorías y disponibilidad— está visible públicamente en las páginas de producto, pero no puede descargarse directamente en formato estructurado.
En estos casos, las herramientas de recopilación de datos web permiten extraer la información de forma automatizada y convertirla en tablas organizadas y exportables en formatos como CSV o Excel. Soluciones visuales como Octoparse facilitan este proceso incluso sin necesidad de programación, permitiendo construir datasets personalizados a partir de múltiples fuentes online.
Una vez estructurado el dataset, puede integrarse directamente en el flujo de entrenamiento del modelo.
Desafíos
- Cambios en la estructura del sitio web
- Necesidad de actualización periódica
- Control de calidad del dataset recopilado
Insight clave
En muchos proyectos de IA, la ventaja competitiva no proviene del algoritmo, sino del acceso y estructuración de datos que otros no están utilizando.
10. Herramientas de etiquetado de datos (Data Labeling)
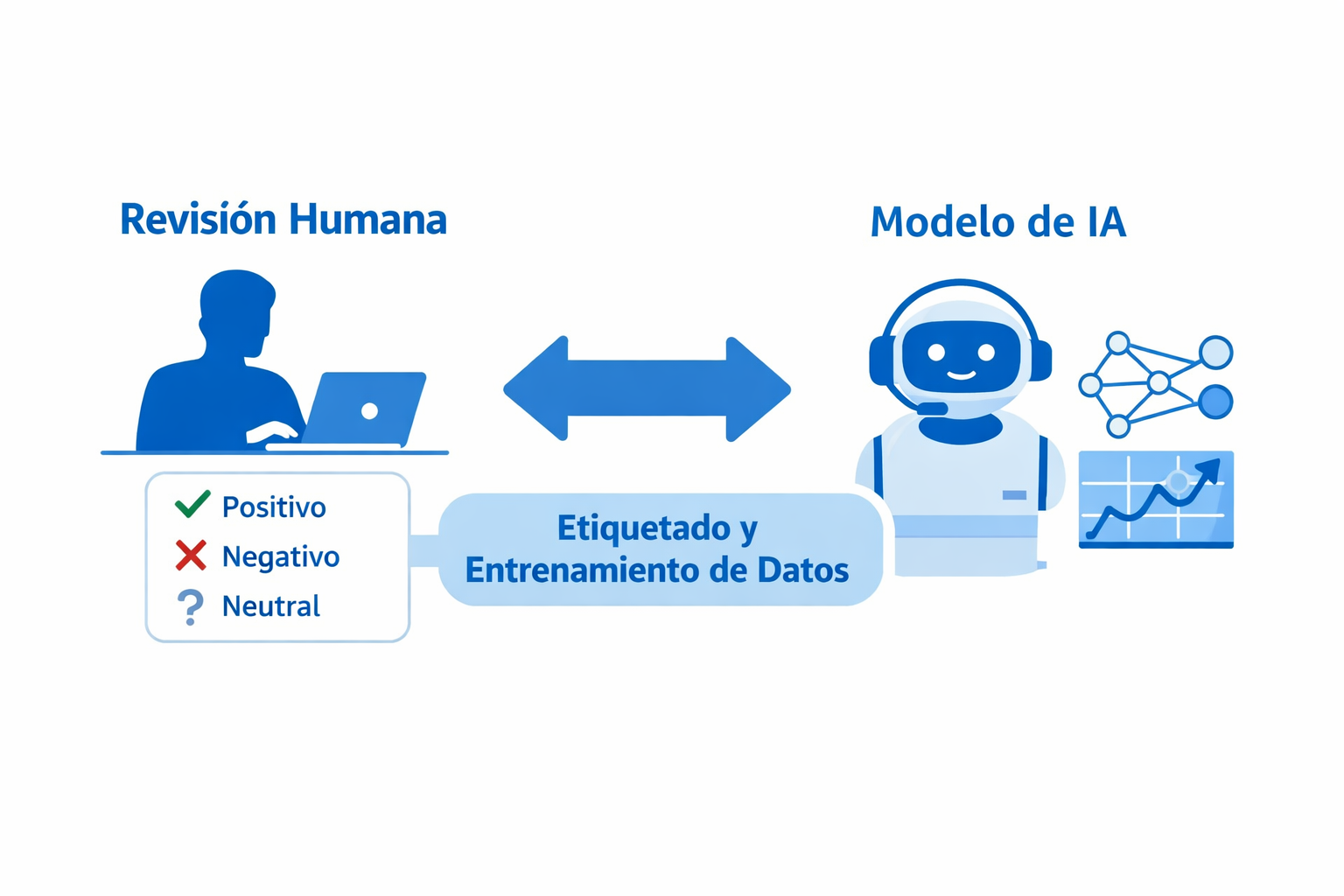
En modelos supervisados, los datos deben estar correctamente etiquetados antes del entrenamiento.
Ejemplo práctico
Una startup desarrolla un modelo de análisis de sentimiento para evaluar reseñas de clientes. Dispone de miles de comentarios, pero necesita clasificarlos manualmente en categorías coherentes antes de entrenar el algoritmo.
Si las etiquetas son inconsistentes o ambiguas, el modelo aprenderá patrones incorrectos. La calidad del etiquetado impacta directamente en la precisión del resultado.
En proyectos más avanzados, el etiquetado puede combinar revisión humana y sistemas de preclasificación automática para acelerar el proceso.
Limitaciones
- Proceso costoso en tiempo
- Riesgo de sesgo humano
- Necesidad de criterios claros de clasificación
Insight clave
El modelo aprende exactamente lo que se le enseña. Si las etiquetas son imprecisas o inconsistentes, incluso el mejor algoritmo producirá resultados poco fiables.
FAQs
1. ¿Cuál es la mejor herramienta para entrenar un modelo de IA?
No existe una única herramienta ideal. La elección depende del tipo de modelo, el volumen de datos y el nivel técnico del equipo. TensorFlow y PyTorch son potentes para deep learning, mientras que Scikit-learn es más adecuado para modelos clásicos y proyectos empresariales.
2.¿Es necesario saber programar para entrenar un modelo de IA?
En la mayoría de los casos sí, especialmente si se utilizan frameworks como TensorFlow o PyTorch. Sin embargo, existen plataformas cloud y soluciones AutoML que reducen la complejidad técnica.
3. ¿Qué herramienta es mejor para principiantes?
Para comenzar, Scikit-learn y Kaggle ofrecen un entorno más accesible. También es recomendable empezar con análisis exploratorio en Excel o Power BI antes de avanzar hacia modelos más complejos.
4. ¿Cuál es el papel de la limpieza de datos antes del entrenamiento?
La limpieza y transformación del dataset es una de las fases más importantes del proyecto. Datos duplicados, inconsistentes o desequilibrados pueden afectar directamente la precisión del modelo.
5. ¿Puedo entrenar un modelo sin datos propios?
Sí, es posible utilizar datasets públicos como los disponibles en Kaggle. Sin embargo, para aplicaciones empresariales reales, los datos propios suelen aportar mayor ventaja competitiva.
6. ¿Cómo obtener datos si no existen APIs disponibles?
Cuando no hay APIs disponibles, es necesario recurrir a herramientas de estructuración de datos web para transformar información pública en datasets utilizables. Este tipo de soluciones permite automatizar la recopilación y mantener actualizada la información antes del entrenamiento.
7. ¿Qué es más importante: el modelo o el dataset?
En la práctica, la calidad y estructura del dataset suelen tener mayor impacto en el rendimiento que la complejidad del algoritmo.
8. ¿Las plataformas cloud sustituyen la preparación de datos?
No. Las plataformas cloud facilitan el entrenamiento y escalabilidad, pero no reemplazan la necesidad de una estrategia sólida de organización y validación de datos.
Conclusión
Entrenar un modelo de inteligencia artificial no consiste únicamente en elegir el framework más avanzado o la arquitectura más compleja. Como hemos visto, el entrenamiento es solo una etapa dentro de un proceso más amplio que comienza con la recopilación, limpieza y estructuración de datos.
Herramientas como TensorFlow, PyTorch o Scikit-learn permiten desarrollar modelos sólidos desde el punto de vista técnico. Las plataformas cloud facilitan la escalabilidad y el despliegue. Sin embargo, el rendimiento final del sistema depende en gran medida de la calidad, coherencia y equilibrio del dataset que lo alimenta.
En muchos proyectos de IA, la verdadera ventaja competitiva no está en el algoritmo, sino en la capacidad de acceder, organizar y mantener datos relevantes de forma sostenible en el tiempo. Por eso, antes de pensar en optimizar hiperparámetros, es fundamental construir una base de datos estructurada y bien gobernada.
Cuando los datos provienen de múltiples fuentes online y no están disponibles en formatos descargables, contar con herramientas de recopilación y estructuración adecuadas puede marcar la diferencia en la viabilidad del proyecto.
Al final, el modelo aprende exactamente lo que se le enseña. La calidad de los resultados siempre reflejará la calidad de los datos.