Cloudflare CAPTCHA es uno de los mayores obstáculos en proyectos de web scraping. Cuando Cloudflare bloquea el acceso, muestra una verificación del navegador o exige una validación adicional antes de continuar, la extracción de datos puede detenerse por completo, incluso si solo trabajas con información pública.
Para quienes trabajan con web scraping, automatización o análisis de datos, este tipo de protección suele convertirse en un problema recurrente que consume tiempo y recursos.
En este artículo explicamos por qué Cloudflare activa el CAPTCHA y cuatro métodos prácticos para manejarlo, desde soluciones sin código hasta enfoques más técnicos.
¿Qué es el CAPTCHA de Cloudflare y por qué aparece?
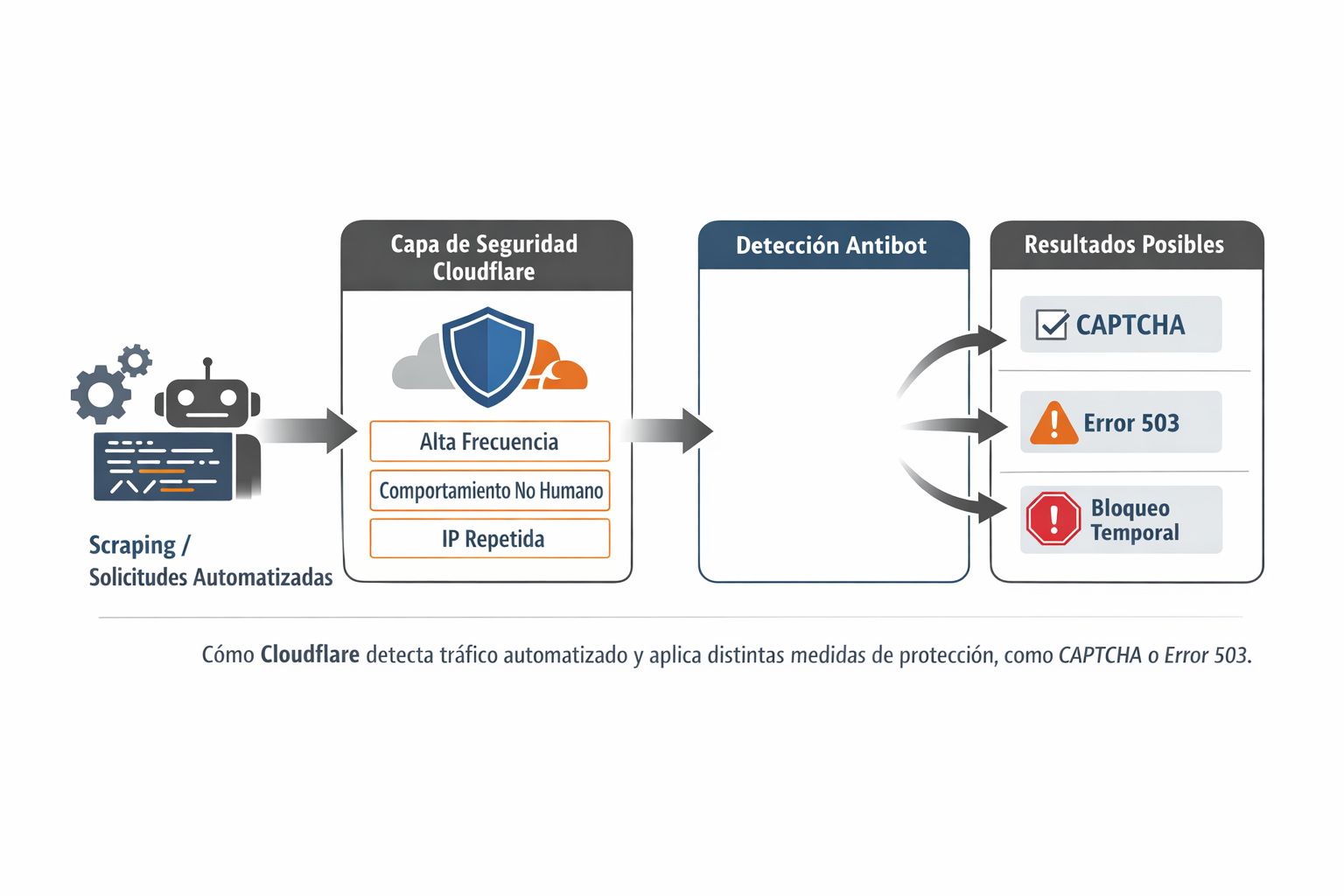
El CAPTCHA de Cloudflare forma parte de un conjunto más amplio de mecanismos de detección antibot, cuyo objetivo es identificar patrones de acceso que no se corresponden con el comportamiento de un usuario humano real. Entre estos patrones se incluyen, por ejemplo, un número elevado de solicitudes en un corto periodo de tiempo, accesos repetidos desde una misma dirección IP, navegadores sin señales de interacción humana o scripts automatizados que cargan páginas sin ejecutar acciones visuales.
Cuando Cloudflare detecta este tipo de comportamiento, no siempre responde de la misma forma. En algunos casos, activa un CAPTCHA como verificación adicional; en otros, ralentiza el acceso, bloquea temporalmente la solicitud o devuelve códigos de error como el 503, que suelen indicar que el sitio está protegiéndose frente a tráfico considerado sospechoso.
Para proyectos de extracción de datos, estas medidas pueden interrumpir parcial o totalmente los flujos de scraping, provocar fallos intermitentes en tareas automatizadas o hacer que un proceso que funcionaba correctamente deje de hacerlo sin cambios aparentes. Por ello, comprender cómo y por qué Cloudflare aplica estas protecciones es un paso clave antes de intentar solucionarlas.
Qué tipo de proyectos suelen verse más afectados por el CAPTCHA de Cloudflare
No todos los proyectos de web scraping activan con la misma frecuencia las protecciones de Cloudflare. En la práctica, el CAPTCHA y otros bloqueos suelen aparecer con mayor probabilidad en escenarios específicos, especialmente cuando el acceso automatizado es continuo o a gran escala.
Los siguientes tipos de proyectos son los que más comúnmente se ven afectados por el CAPTCHA de Cloudflare:
- Monitoreo de precios y disponibilidad:
La extracción frecuente de precios, stock o cambios en catálogos de productos puede generar patrones de acceso repetitivos que activan los sistemas antibot. - Scraping de listados a gran escala:
Proyectos que recorren cientos o miles de páginas de resultados, como marketplaces, directorios o portales inmobiliarios, suelen alcanzar rápidamente los límites de detección. - Extracciones periódicas o programadas:
Tareas que se ejecutan de forma automática varias veces al día o de manera continua (24/7) pueden resultar sospechosas si no simulan un comportamiento humano real. - Automatizaciones sin navegador real:
Procesos basados únicamente en peticiones HTTP, sin ejecución de JavaScript ni señales de interacción humana, tienen más probabilidades de ser bloqueados por Cloudflare. - Proyectos con múltiples solicitudes desde una misma IP:
Incluso cuando se trabaja con datos públicos, el uso intensivo de una sola dirección IP puede activar CAPTCHA o bloqueos temporales.
Reconocer si tu proyecto encaja en alguno de estos escenarios es un paso clave para elegir la estrategia adecuada y evitar bloqueos innecesarios durante la extracción de datos.
- No siempre es un formulario clásico; a veces es un proceso de verificación invisible
- Cambia dinámicamente según el comportamiento del tráfico
- Puede bloquear incluso direcciones IP “limpias” si detecta automatización
- Es difícil de resolver solo con peticiones HTTP tradicionales
Por eso, manejar este tipo de protección requiere estrategias más avanzadas o herramientas adecuadas.
Método 1: Manejar el CAPTCHA de Cloudflare con Octoparse (sin código)
Octoparse es una potente herramienta de web scraping que permite manejar el CAPTCHA de Cloudflare de forma eficiente, automatizando todo el proceso de extracción de datos y reduciendo la necesidad de intervención manual. A continuación, se explica cómo Octoparse aborda este tipo de desafíos:
- Gestión automática de CAPTCHA:
Octoparse detecta automáticamente los desafíos de CAPTCHA y los gestiona mediante la simulación de un comportamiento de navegación similar al de un usuario humano. De este modo, es posible resolver o saltar CAPTCHA sin interrumpir el proceso de scraping. - Gestión inteligente de proxies:
Octoparse rota direcciones IP mediante el uso de proxies para reducir la detección y los bloqueos por parte de Cloudflare. Al utilizar diferentes IP, el tráfico se asemeja más al de usuarios legítimos, lo que dificulta que Cloudflare bloquee las solicitudes. - Scraping en la nube:
Gracias a sus capacidades de extracción en la nube, Octoparse permite ejecutar tareas sin depender de la IP local, evitando bloqueos locales y problemas relacionados con la sobrecarga del servidor.
Con Octoparse, gestionar el CAPTCHA de Cloudflare se vuelve un proceso más fluido, permitiéndote centrarte en la recopilación de datos sin interrupciones innecesarias. A continuación, se describen los pasos básicos para resolver el CAPTCHA de Cloudflare con Octoparse.
Pasos para manejar el CAPTCHA de Cloudflare con Octoparse
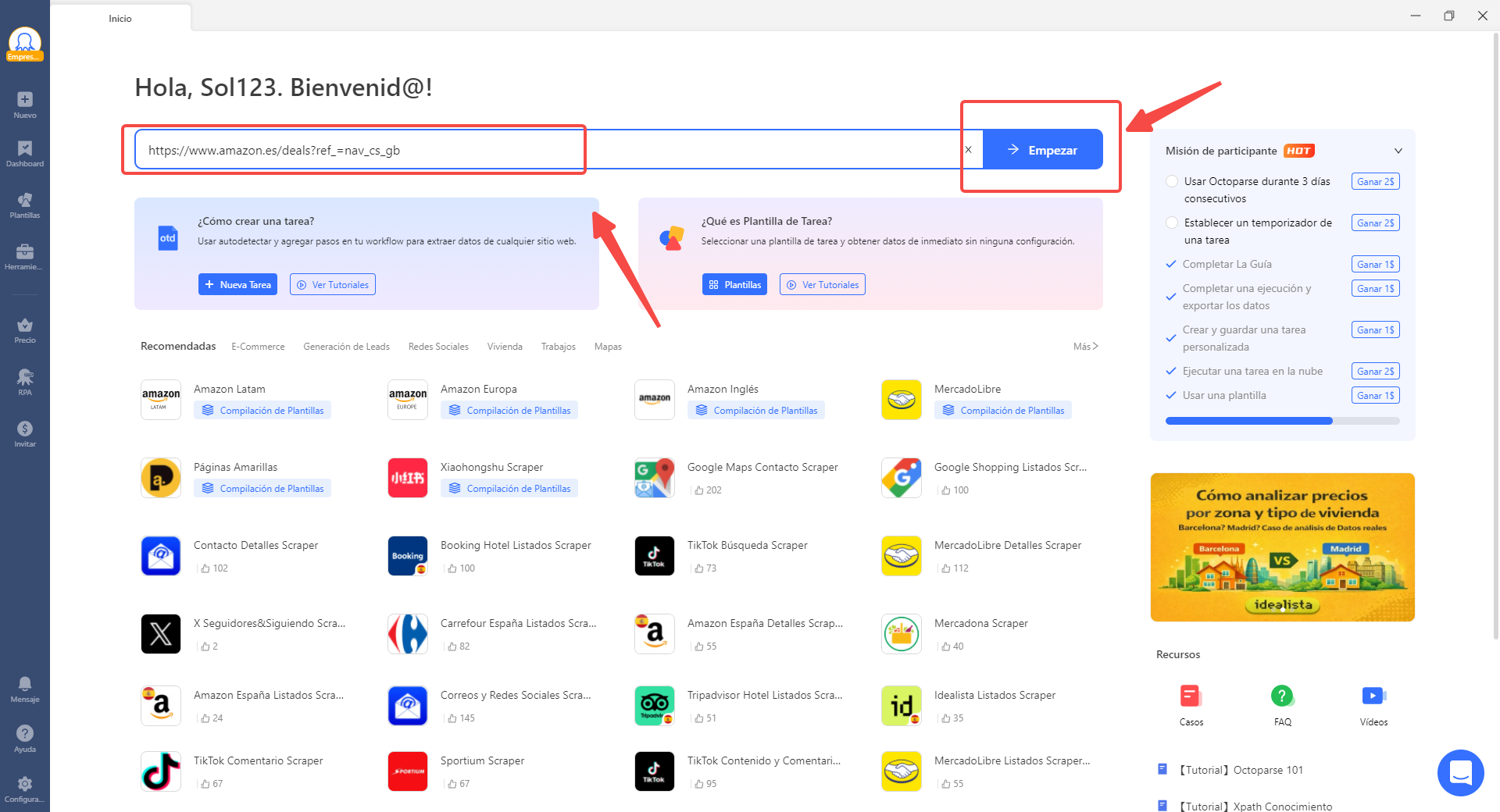
Paso 1: Crear una tarea de scraping
Al igual que en cualquier tarea de extracción de datos, primero debes crear un flujo de trabajo para el sitio web del que deseas obtener información. Abre Octoparse y pega la URL de la página para iniciar la detección automática o configurar la tarea de forma manual.
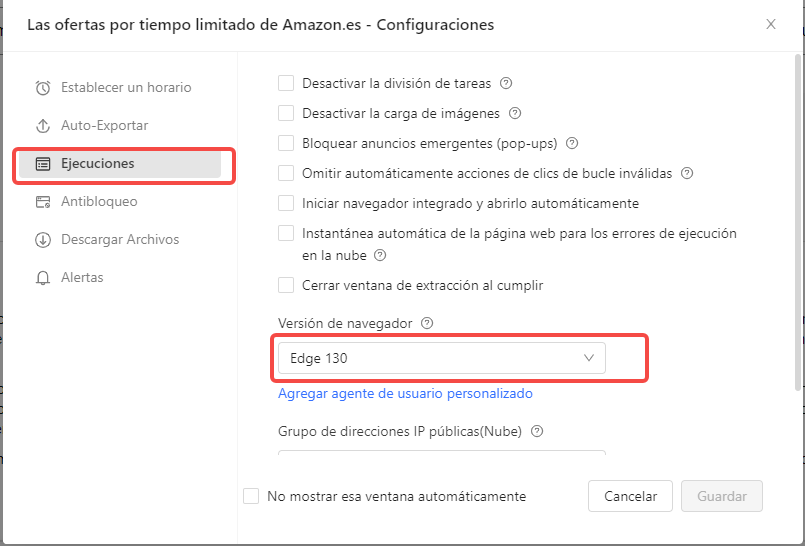
Paso 2: Configurar Edge 130 en los ajustes de la tarea
Accede a la configuración de la tarea y selecciona Edge 130 como versión del navegador.
Después de guardar este ajuste, activa el modo de navegación (Browse mode) para poder resolver el CAPTCHA de forma manual si es necesario.
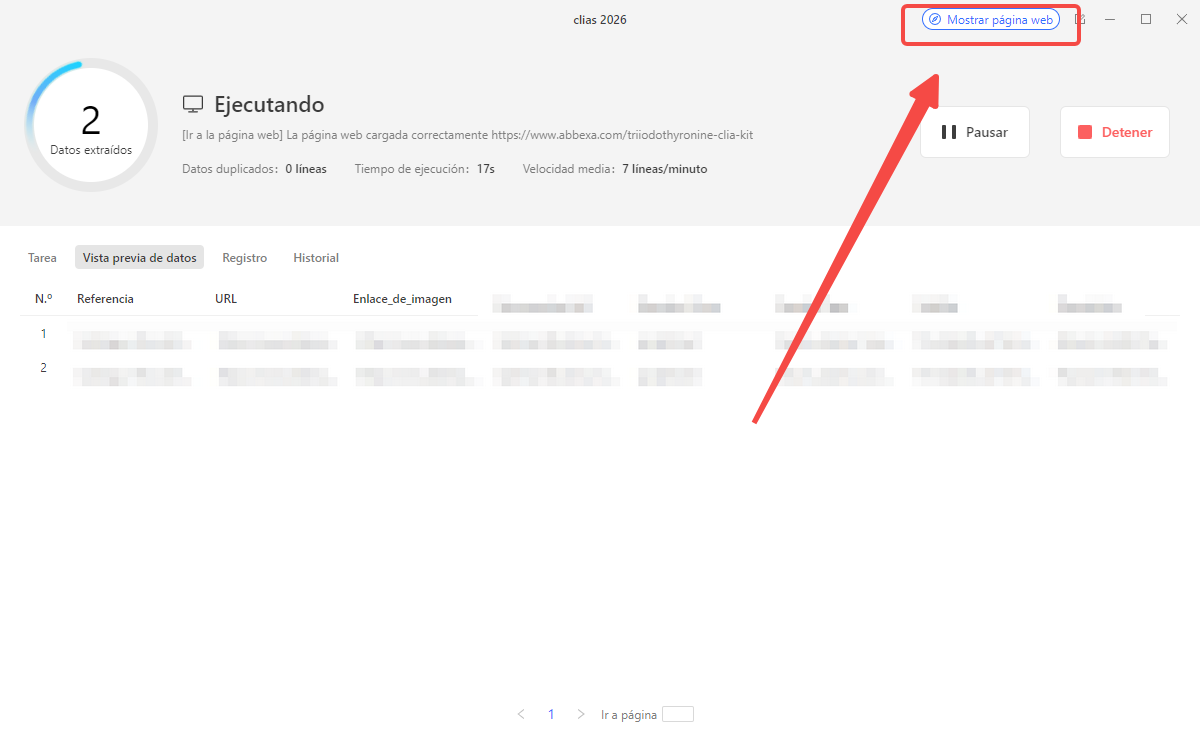
Paso 3: Ejecutar la tarea de forma local
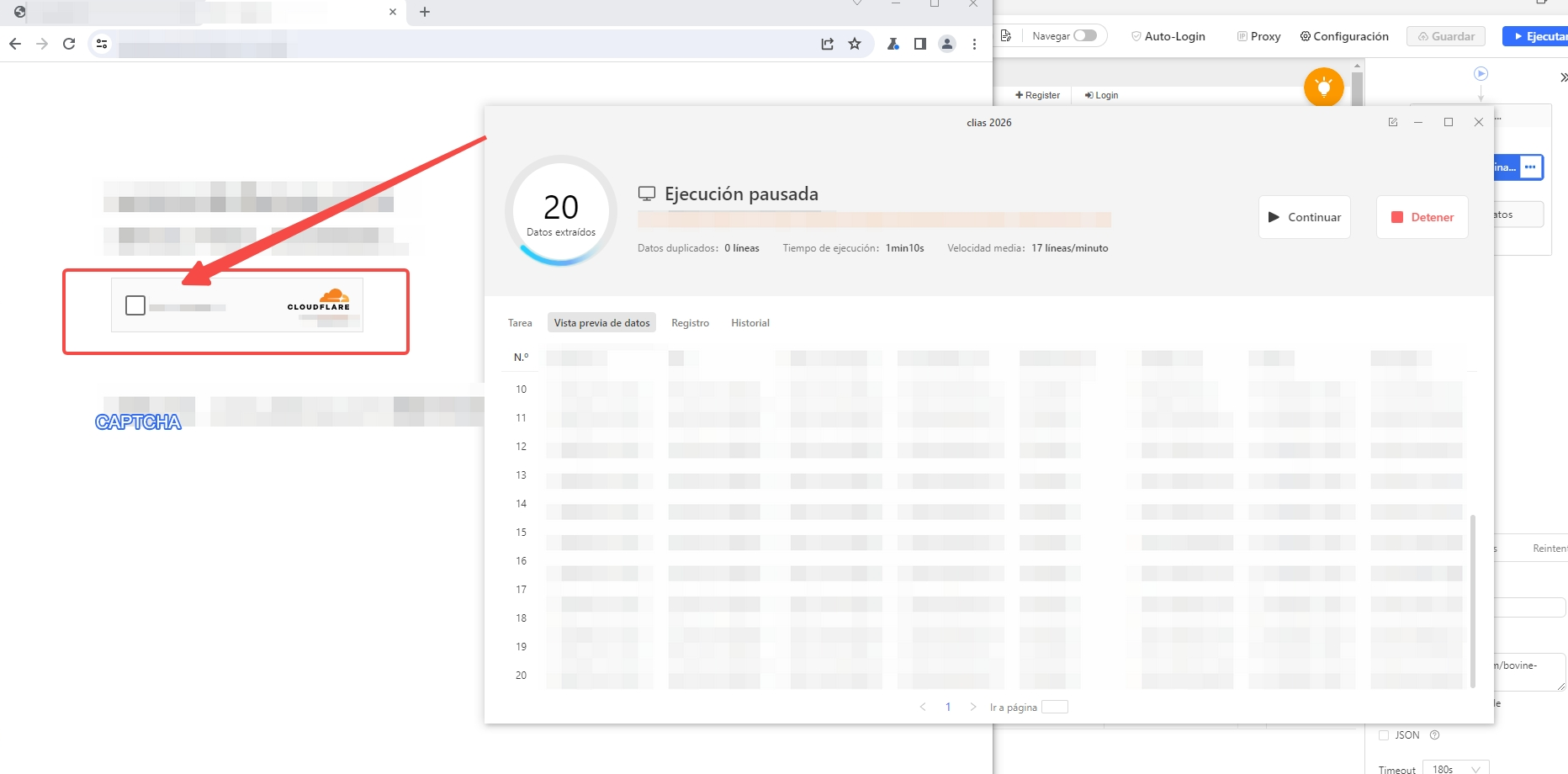
El CAPTCHA de Cloudflare solo puede resolverse cuando la tarea se ejecuta localmente. Por ello, selecciona la opción “Ejecutar en el dispositivo” para iniciar la extracción de datos.
Durante la ejecución, haz clic en “Pausar” y luego en “Mostrar página web” para resolver el CAPTCHA directamente en el navegador. Una vez completado, selecciona “Continuar” para continuar con la tarea.
Método 2: Rotación de proxies
La rotación de proxies es una estrategia clásica para evitar bloqueos, incluyendo los de Cloudflare.
¿En qué consiste?
- Utilizar múltiples direcciones IP
- Cambiar de IP automáticamente entre solicitudes
- Reducir la carga sobre una sola IP
Los proxies residenciales suelen funcionar mejor que los de centros de datos, ya que parecen tráfico más natural.
Limitaciones
- Coste elevado, especialmente a gran escala
- No garantiza evitar CAPTCHA si el comportamiento sigue siendo automatizado
- Requiere configuración y mantenimiento constante
Método 3: Servicios de resolución de CAPTCHA
Otra opción es integrar servicios externos de resolución de CAPTCHA, que utilizan reconocimiento automático o intervención humana.
Ventajas
- Permiten automatizar procesos bloqueados por CAPTCHA
- Funcionan con distintos tipos de desafíos
Desventajas
- Coste adicional por cada CAPTCHA resuelto
- Integración técnica necesaria
- No siempre compatibles con el flujo dinámico de Cloudflare
Este método suele ser más adecuado para desarrolladores con experiencia técnica.
Comparación de servicios de resolución de CAPTCHA
| Servicio | Tipo de resolución | Principales ventajas | Principales limitaciones | Perfil recomendado |
|---|---|---|---|---|
| 2Captcha | Intervención humana | Amplia compatibilidad con distintos tipos de CAPTCHA; precios accesibles; uso extendido en web scraping | Latencia variable; coste por cada CAPTCHA resuelto | Proyectos pequeños o medianos con necesidades puntuales |
| Anti-Captcha | Automática y humana | API bien documentada; soporte para múltiples sistemas de verificación | Requiere integración técnica; costes acumulativos | Desarrolladores con experiencia técnica |
| CapMonster | Automática (local / API) | Buen rendimiento en escenarios de alto volumen; control local | Configuración compleja; requiere mantenimiento | Proyectos avanzados y de gran escala |
| DeathByCaptcha | Humana y automática | Alta fiabilidad; servicio veterano | Menor velocidad en algunos casos; coste por uso | Casos donde la precisión es prioritaria |
Aunque estos servicios permiten automatizar procesos bloqueados por CAPTCHA, es importante tener en cuenta que:
- Implican costes adicionales por cada desafío resuelto
- Requieren integración técnica y mantenimiento continuo
- No siempre funcionan de forma estable con protecciones dinámicas como Cloudflare
Por este motivo, suelen ser más adecuados para desarrolladores con experiencia técnica o proyectos que requieren un alto nivel de personalización.
Método 4: Automatización del navegador (Selenium, Playwright)
Las herramientas de automatización del navegador permiten controlar un navegador real mediante código.
Ejemplos comunes
- Selenium (¿Qué es Selenium?)
- Playwright
- Puppeteer
Ventajas
- Alto nivel de control
- Capacidad de simular interacciones humanas
Desventajas
- Requieren conocimientos de programación
- Configuración compleja
- Mayor esfuerzo de mantenimiento
- Mayor riesgo de detección si no se optimiza correctamente
¿Cuál es el mejor método para tu proyecto?
No existe una solución única. La mejor opción depende de:
- Tu nivel técnico
- El volumen de datos que necesitas
- El presupuesto disponible
- La frecuencia de extracción
En muchos casos, empezar con una solución sin código como Octoparse es la forma más rápida y eficiente de validar un proyecto antes de pasar a enfoques más técnicos.
Preguntas frecuentes (FAQ)
¿Es legal manejar el CAPTCHA de Cloudflare?
Depende del sitio web y de sus términos de uso. Es importante extraer solo datos públicos y respetar la legislación y condiciones de cada plataforma.
¿Por qué Cloudflare bloquea incluso cuando uso proxies?
Porque Cloudflare no solo analiza la IP, sino también el comportamiento del navegador, la frecuencia de solicitudes y otros factores.
¿Necesito siempre proxies para evitar bloqueos?
No necesariamente. Un comportamiento más humano y el uso de un navegador real pueden reducir significativamente los bloqueos.
💡En la práctica, esto implica navegar con pausas naturales, cargar páginas de forma secuencial en lugar de simultánea y permitir interacciones básicas como el desplazamiento o la ejecución de JavaScript.
Conclusión
El CAPTCHA de Cloudflare es un reto común en proyectos de web scraping modernos. Sin embargo, con la estrategia adecuada —ya sea mediante herramientas sin código, rotación de proxies o automatización avanzada— es posible manejar estos bloqueos de forma eficiente.
Elegir el método correcto desde el inicio puede ahorrarte tiempo, costes y frustraciones, y permitirte centrarte en lo más importante: convertir datos en decisiones.

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.



