Puedes llevar mucho tiempo en buscar, copiar y pegar varias imágenes de Reddit. Pero, ¿alguna vez has pensado en crear un raspador de imágenes de Reddit usando Octoparse, la poderosa herramienta de web scraping? Ahora vamos a averiguar cómo hacerlo.
¿Qué es Image Scraper y cómo funciona?
Este artículo presentará particularmente cómo construir un image Scraper de Reddit, pero comencemos con la idea del image Scraper. Image Scraper reduce su trabajo manual de copiar y pegar imágenes de las páginas web.
Al igual que en los escenarios del mundo real, las personas no pueden copiar y pegar cientos y miles de imágenes para cualesquiera propósitos. Image Scraper viene a rescatar a esas personas, lo que realmente reduce el consumo de tiempo y automatiza el proceso para usted.
Los pasos para hacer un Image Scraper básicamente incluyen:
- Extraer URL de imágenes de cualquier sitio web en particular y almacenarlas en un archivo de Excel
- Usar las URL para descargar imágenes con algunos complementos de Chrome
¿Cómo construir un Image Scraper?
Hay dos maneras de construir un Image Scraper. Si tienes experiencia técnica y buen conocimiento de cualquier lenguaje de programación, puedes usarlo para construir un Image Scraper. Incluso si no tienes experiencia técnica, no te preocupes, aún puedes construir tu propio Image Scraper personalizado utilizando el software.
- Lenguaje de computadora (codificación)
Para construir un image Scraper, la gente de tecnología puede construirlo fácilmente usando cualquier lenguaje de programación como Python. Simplemente tiene que escribir algunas líneas de código para construir un image Scraper por su cuenta. Puede aprovechar BeautifulSoup, Scrapy, Selenium como paquetes disponibles en Python para construir su propio Image Scraper.
- Herramienta de Web Scraping (sin codificación)
Y si eres alguien que no perteneces a ningún antecedente técnico, hay muchos Softwares de Scraping que eventualmente te ayudará con el image scraping en minutos.
Por lo tanto, permíteme presentarte uno aquí que tiene una interfaz fácil de usar y fácil de entender. Qué es, Octoparse.
Octoparse es un software de scraping que te brinda servicios de raspar gratuitos hasta 10K filas de una sola vez que puedes raspar sin costo, e incluso si este límite no es satisfactorio para ti, aún puedes actualizar sin límites solo por 75 $ un mes. Para obtener más información sobre todos y cada uno de los planes, visita este enlace: https://www.octoparse.com/pricing.
Aparte de los servicios gratuitos, la comunidad de Octoparse ofrece una buena cantidad de tutoriales y artículos para cualquier tipo de escenarios del mundo real.
Para construir un Image Scraper exitoso, también necesitará agregar una extensión de Chrome que guardará imágenes instantáneamente al proporcionar la lista de URL. Para este tutorial, estoy usando el complemento de Chrome Tab Save.
Ejemplo de tutorial: Crear un Image Scraper de Reddit con Octoparse
Tomemos un ejemplo de cómo hacer un raspador de imágenes de Reddit usando Octoparse. Para este tutorial, estoy usando la versión 8 de Octoparse.
Para este tutorial, estamos extrayendo imágenes de esta página web de Reddit, https://www.reddit.com/rising/
Para hacer Reddit Image Scraper, simplemente sigue estos pasos sencillos:
#1 Copia el enlace del sitio web del que desea extraer imágenes. En la esquina izquierda de la página de inicio, haz clic en el botón “+ Nuevo” y elige la opción “Advanced Mode” del menú desplegable como se muestra a continuación.
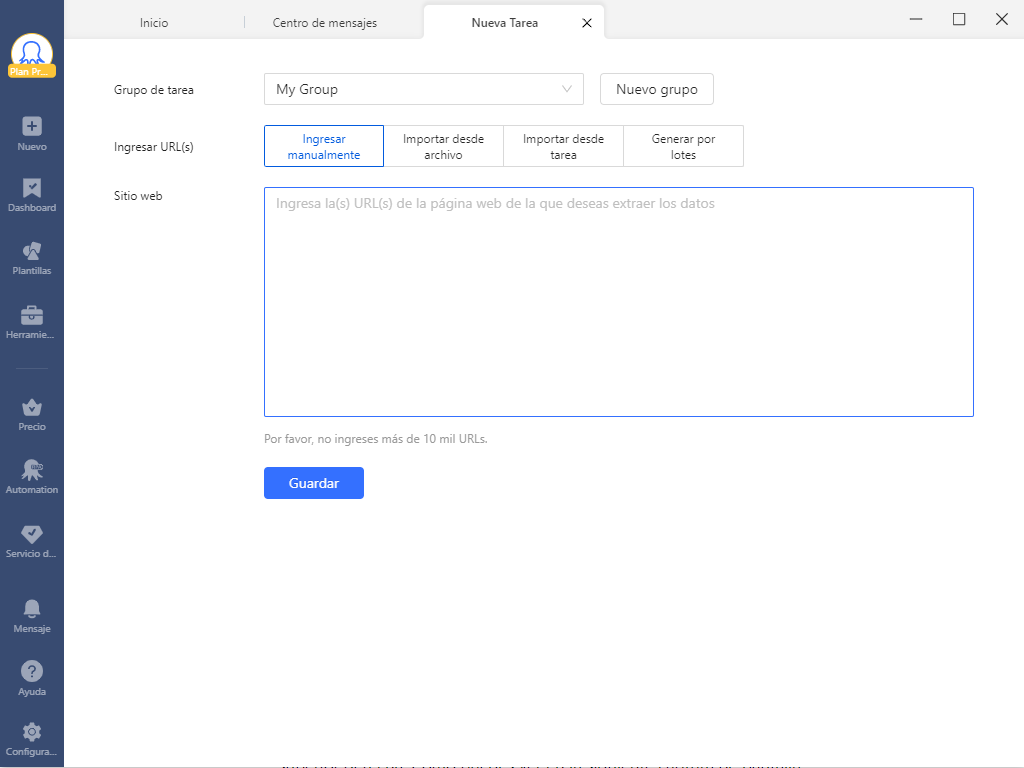
#2 Después de eso, verás otra interfaz que muestra espacio para la URL. Simplemente pega la URL copiada en el espacio especificado como a continuación y haz clic en “Guardar” para seguir adelante.
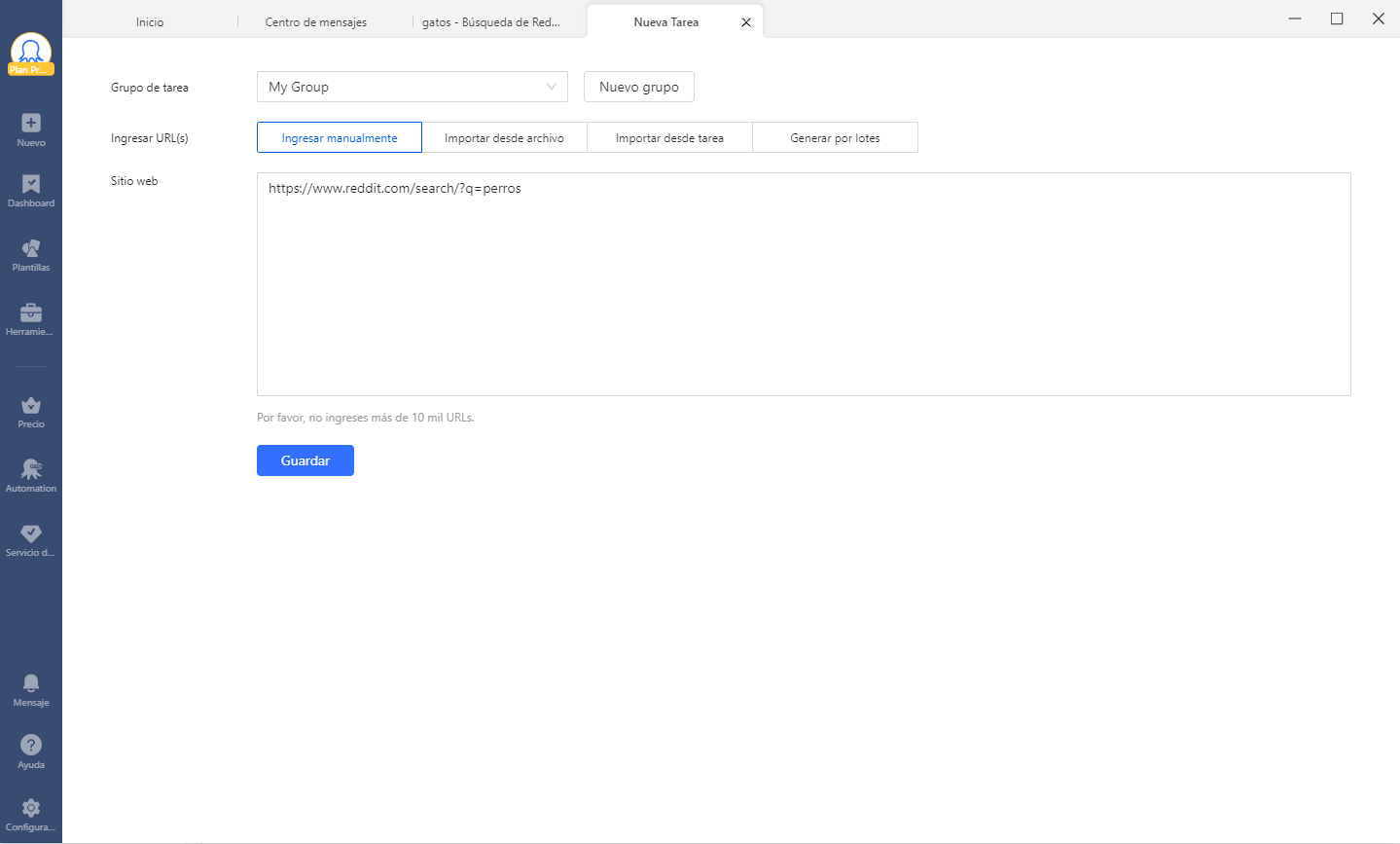
#3 Al hacer clic en el botón “Guardar” lo llevarás a la siguiente interfaz que se verá como la imagen de abajo dividida en tres secciones. Aparte de la sección “Workflow” y “Vista Previa de datos“, la parte superior derecha contiene la interfaz del sitio web que deseas raspar. Incluso puedes seleccionar elementos manualmente y navegar aquí tan bien como lo hace en el navegador. Para navegar aquí, cambia la opción “Navegar” en la esquina superior derecha. Como puedes ver en la siguiente captura de pantalla, también hay dos pasos enumerados en el panel “Tips”.
#4 Por lo tanto, si deseas seleccionar elementos de una página web de forma selectiva de forma manual, elige la segunda opción. La versión nueva también permite la función de “Detección Automática” en la que el robot de raspar selecciona automáticamente los datos de la página web enumerada. Es bueno seleccionar si eres un principiante en este software para saber un poco más sobre el flujo de trabajo y cómo funciona. Puedes eliminar o mantener atributos en la sección “Vista Previa de datos” según tu conveniencia más tarde.
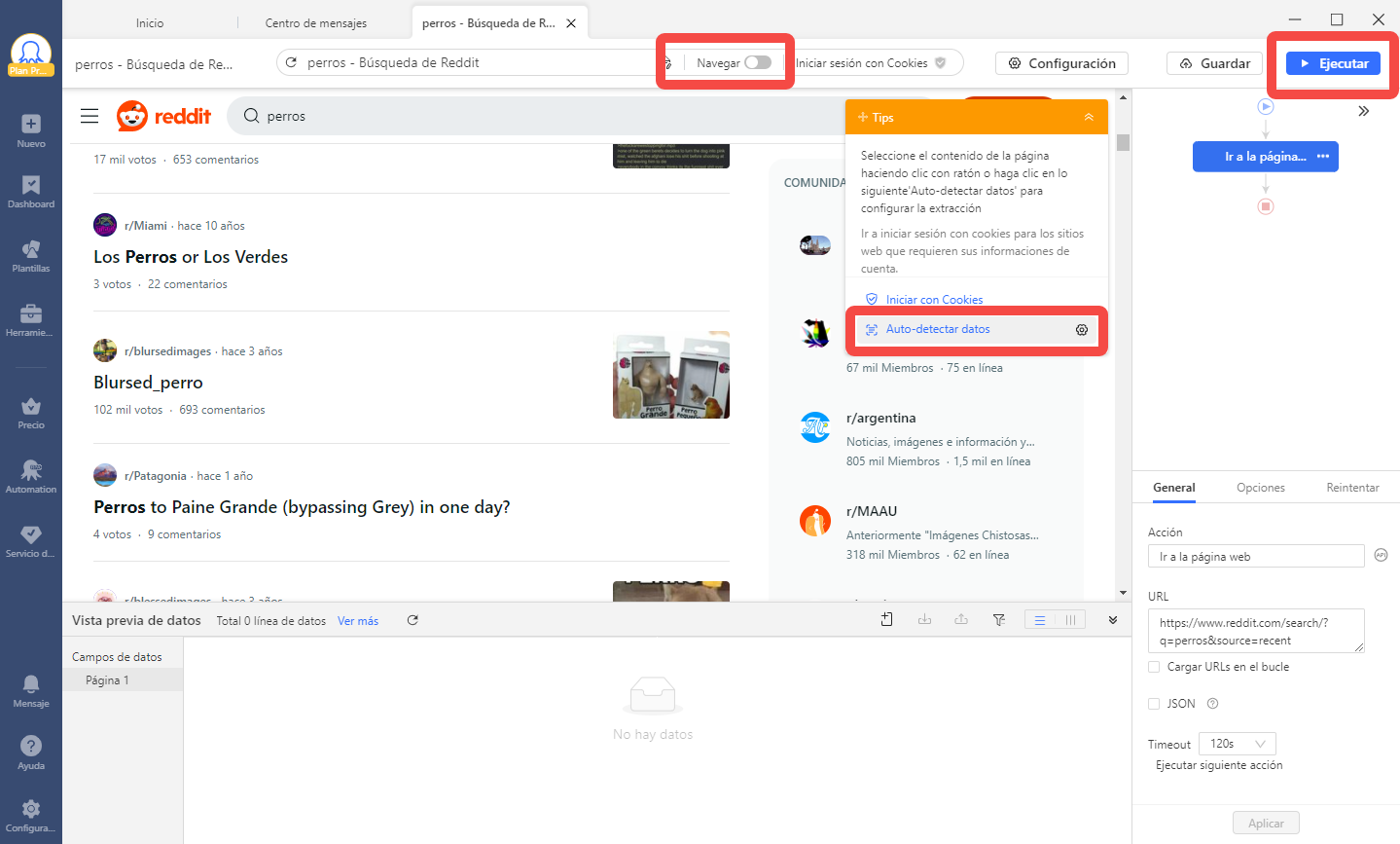
#5 Por la presente, estoy ilustrando los pasos de “Edit task workflow manually”. El panel “Tips” aparecerá al hacer clic en la primera imagen. Luego elige la opción “Select all” para seleccionar todas las imágenes enumeradas en la página web.
#6 Ahora mira la imagen a continuación, debes estar viendo algunas diferencias. Justo después de seleccionar todas las imágenes, ha enumerado todos los enlaces para las imágenes en la sección “Vista Previa de datos“. El panel “Tips” ha enumerado algunas opciones para elegir. Para extraer URL de imágenes, selecciona la primera opción, es decir, “Extract image URLs“.
#7 Para ver qué enlace de imagen se ha raspado, haz clic en ese enlace en la sección “Vista Previa de datos“. Podrás ver algunos aspectos destacados en la interfaz de navegación como en la captura de pantalla adjunta.
#8 Cambia algunos ajustes para desplazarnos más hacia abajo y cargar más imágenes. Como puedes ver, se está desplazando solo por una pantalla y obteniendo solo 3 imágenes. Para obtener más datos, debes especificar algunas configuraciones. Para este caso particular, he adjuntado algunas capturas de pantalla a continuación.
#9 Haz doble clic en el cuadro “Ir a la página web” para que puedas ingresar las opciones de configuración.
#10 Marca la casilla para desplazarse hacia abajo más. Completa otros valores como repeticiones y espera el tiempo según tus requisitos. No olvida actualizar la configuración de un “Loop Item” en el flujo de trabajo.
#11 Si la opción “Extract data in the loop” no está seleccionada ya automáticamente, selecciona esta opción en la configuración de “Extract Data” del flujo de trabajo.
#12 Puedes ver estos dos botones en la parte superior del flujo de trabajo: “Guardar” y “Ejectuar“. Ahí es donde puedes guardar tu tarea y ejecutar el rastreador una vez que se hayan actualizado todas las configuraciones.
#13 Si estás utilizando un plan gratuito, ejecuta la tarea en tu dispositivo. Los servicios en la nube solo están disponibles para otros planes. Se raspará la lista de enlaces de imágenes para ti en solo unos minutos. Como puedes ver a continuación, raspó 51 enlaces en solo 1 minuto y 12 segundos. ¿No es genial?
#14 Ahora, para guardar el archivo de datos en tu sistema, haz clic en “Export Data” y elige el formato de tu elección.
#15 Así es como se verán las URL raspadas en un formato estructurado. El siguiente paso es descargar las imágenes, ya que tienes todos los enlaces en un solo lugar, simplemente copia y pega los enlaces a la Tab Save Chrome extension.
#16 Comienza a descargar los archivos haciendo clic en el icono de descarga en la parte inferior.
Mira, ¡qué fácil fue! Con solo seguir estos pasos, puedes crear tu propio Raspador de imágenes de Reddit en solo unos minutos. ¿Entonces, Qué espera? Venga y raspa. Utiliza este software y este tutorial como puedas.