Introducción
El scraping en la nube (cloud web scraping) es un método de recopilación de datos de sitios web que se ejecuta en servidores remotos, lo que permite que tus rastreadores sigan funcionando incluso cuando tu ordenador está apagado, en reposo o se cae de forma inesperada. Esto hace que las tareas de extracción grandes, de larga duración o inestables sean más rápidas, confiables y fáciles de escalar.
Si todavía ejecutas scrapers directamente en tu máquina local —ya sea con un script de Python o una extensión de navegador— probablemente ya hayas llegado a un límite de rendimiento. Aunque el scraping local funciona bien para tareas pequeñas y puntuales, se convierte en un cuello de botella en cuanto necesitas escalar.
En este artículo te explicamos qué es el scraping en la nube y cómo usar la extracción de datos en la nube para acelerar y optimizar tu proceso.
Por qué el scraping local suele fallar
A medida que tus necesidades de datos crecen —de cientos a millones de páginas—, la extracción local se vuelve un obstáculo. Estas son sus limitaciones más comunes:
- Limitaciones de hardware: Tu equipo se ralentiza, se sobrecalienta y consume todo el ancho de banda disponible.
- Dependencia constante del equipo: Si cierras tu portátil o pierdes la conexión a internet, el scraping falla sin más.
- Bloqueo inmediato de IP: Enviar miles de solicitudes desde una única IP doméstica es la forma más rápida de ser bloqueado por el sitio objetivo.
- Velocidad limitada: Estás restringido a la capacidad de procesamiento de una sola máquina.
La alternativa es el scraping en la nube: trasladar tu lógica de extracción a un entorno de servidor remoto te da escalabilidad, flexibilidad y rentabilidad. Con la configuración adecuada, puedes extraer datos de millones de páginas simultáneamente sin consumir ni un solo ciclo de CPU de tu propio equipo.
Scraping en la nube vs. scraping local: comparativa
Los scrapers basados en la nube y los scrapers locales representan dos enfoques completamente distintos. A la hora de elegir, las empresas suelen evaluar factores como velocidad, escalabilidad, fiabilidad, mantenimiento y coste. Aquí tienes las principales diferencias:
| Características | Basado en la nube | Basado en local |
|---|---|---|
| Velocidad | Más rápido para tareas de scraping a gran escala | Puede ser más lento con grandes volúmenes de datos |
| Escalabilidad | Se ajusta según el volumen de datos a extraer | Limitado por la capacidad de la máquina local |
| Fiabilidad | Mayor fiabilidad gracias a infraestructura robusta y redundante | Puede sufrir interrupciones por fallos de red o del equipo |
| Mantenimiento | Mínimo: el proveedor gestiona actualizaciones y copias de seguridad | Requiere mantenimiento activo: scripts, rendimiento, recursos locales |
| Coste | Puede generar costes por uso, pero elimina inversión inicial en hardware | Más económico para tareas pequeñas sin gastos adicionales de nube |
| Control | Menos control sobre la infraestructura subyacente | Mayor control sobre el proceso de scraping y los scripts |
Qué es el modo de extracción en la nube de Octoparse
Ahora que ya conoces las ventajas del scraping en la nube, hablemos de herramientas. Entre los distintos scrapers en la nube disponibles en el mercado, Octoparse destaca por la potencia y versatilidad de sus funciones.
Octoparse te permite construir la lógica del scraper en tu cliente de escritorio local y luego “subir” esa tarea a su plataforma en la nube. Gracias a su sistema de computación distribuida, cuando cargas una tarea, la plataforma divide tu lista de URLs y las asigna a múltiples servidores en la nube de forma simultánea.
- Velocidad: Una tarea que tarda 1 hora en tu máquina local podría completarse en solo 10 minutos distribuida en 6 servidores en la nube.
- Rotación de IPs: La rotación se gestiona automáticamente dentro del entorno cloud.
- Programación: Puedes configurar la tarea para que se ejecute automáticamente en los intervalos que necesites.

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.
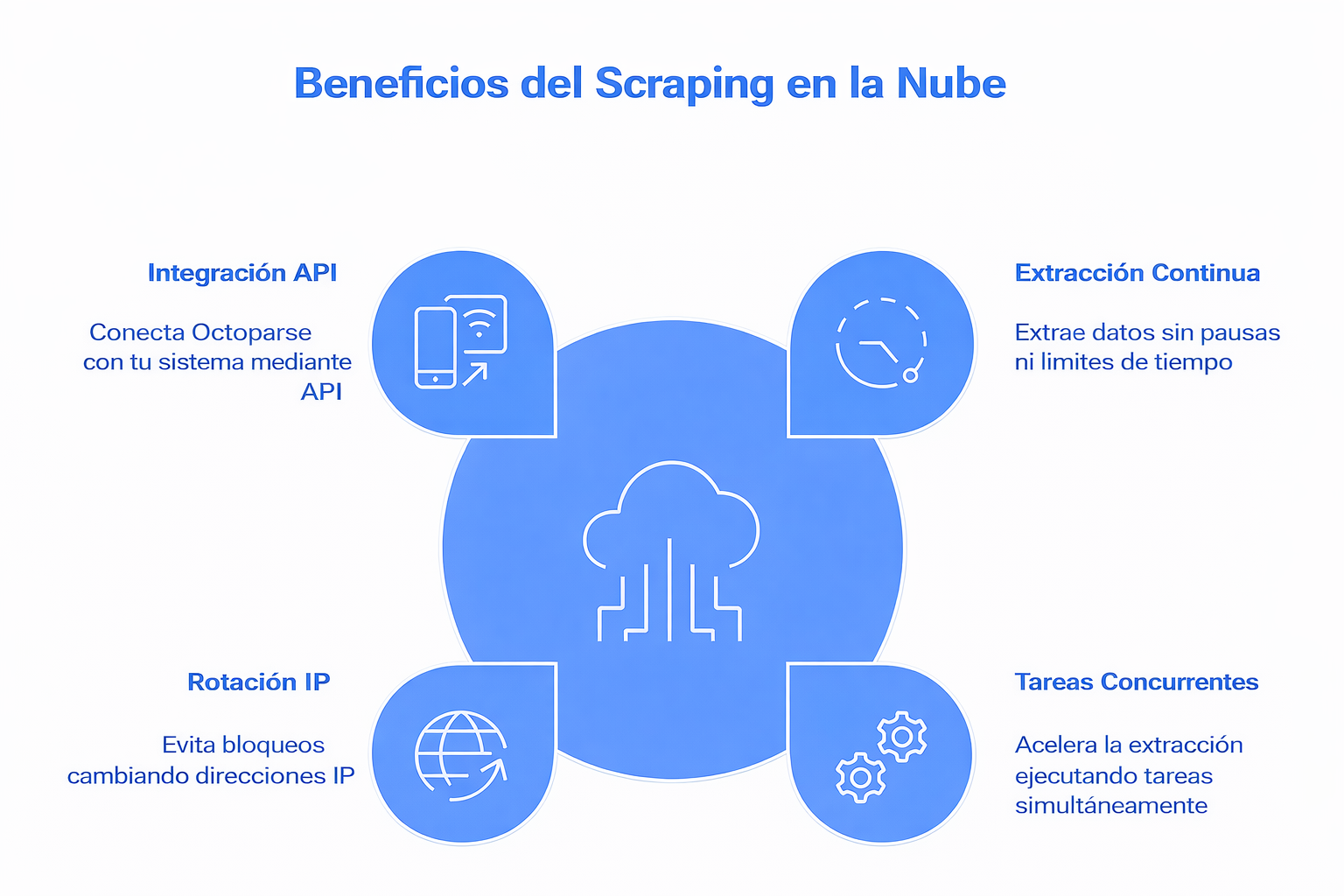
Octoparse ofrece además una potente función de nube que permite ejecutar tareas las 24 horas del día, los 7 días de la semana. A continuación, te explicamos sus características principales.
Extracción de datos sin pausas ni límite de tiempo
Al usar el servicio en la nube de Octoparse, olvídate de errores causados por interrupciones de red o congelamientos del sistema. Cuando ocurren este tipo de problemas, los servidores en la nube reanudan el trabajo de forma inmediata. Además, si necesitas extraer datos en un horario determinado o actualizar tu información de manera periódica, puedes programar tareas de extracción en la nube desde Octoparse.
Tareas concurrentes para acelerar el proceso
Como ya mencionamos, las plataformas en la nube te permiten dividir una tarea de scraping en varias secciones y asignarlas a múltiples servidores para que extraigan datos al mismo tiempo. El modo cloud de Octoparse ofrece hasta 20 nodos en los planes de pago. La plataforma divide automáticamente tu tarea en subtareas más pequeñas y ejecuta cada una en un nodo independiente. Los nodos pueden funcionar 24/7 y alcanzar una velocidad de 4 a 20 veces mayor que la extracción local.
Evita los bloqueos con rotación de IPs
Si tienes experiencia en scraping web, seguramente te habrán bloqueado alguna vez. Es un problema muy habitual, ya que muchos sitios web implementan medidas de seguridad avanzadas para detectar y bloquear scrapers. Para resolverlo, el servicio en la nube de Octoparse proporciona miles de nodos, cada uno con una dirección IP única, que rotan automáticamente. Así, tus solicitudes llegan al sitio objetivo a través de distintas IPs, lo que minimiza significativamente las posibilidades de ser rastreado o bloqueado.
Conecta Octoparse con tu sistema mediante API
El servicio en la nube de Octoparse también incluye una API que te permite integrar tu sistema u otras herramientas directamente con Octoparse. De este modo, puedes exportar los datos extraídos a tu base de datos sin necesidad de descargar archivos manualmente. Por ejemplo, puedes enviar los datos directamente a Google Sheets a través de la API de Octoparse. Si tu equipo tiene experiencia en programación y necesita automatizar la exportación de datos o el control de tareas, también puedes conectarte a las APIs de Octoparse con Postman.
Cómo usar la extracción en la nube de Octoparse: guía paso a paso
El modo de extracción en la nube es una función avanzada de Octoparse; asegúrate de tener contratado el plan Estándar, Profesional o Empresarial antes de comenzar. Una vez hecho esto, abre Octoparse en tu dispositivo y sigue estos pasos.
Paso 1: configura tu tarea de extracción
Al igual que en el modo de scraping local, primero debes definir tu flujo de trabajo. Copia y pega la URL del sitio web del que quieres extraer datos. Con la interfaz de clic y la función de detección automática de Octoparse, crear un flujo de extracción es muy sencillo, sin necesidad de conocimientos de programación.
Paso 2: personaliza tu flujo de extracción de datos
Revisa y especifica los campos de datos que necesitas: detalles de productos, precios, reseñas, etc. En este paso también puedes configurar la paginación, XPath, proxy de IP y otras funciones avanzadas. Elimina o añade campos según tus necesidades.
Paso 3: ejecuta tu tarea en la nube
Una vez terminado el flujo, haz clic en el botón Ejecutar y selecciona Modo Estándar o Modo Aceleración bajo Ejecutar en la nube para lanzar la extracción. No necesitas mantener tu ordenador encendido ni preocuparte por el rendimiento.
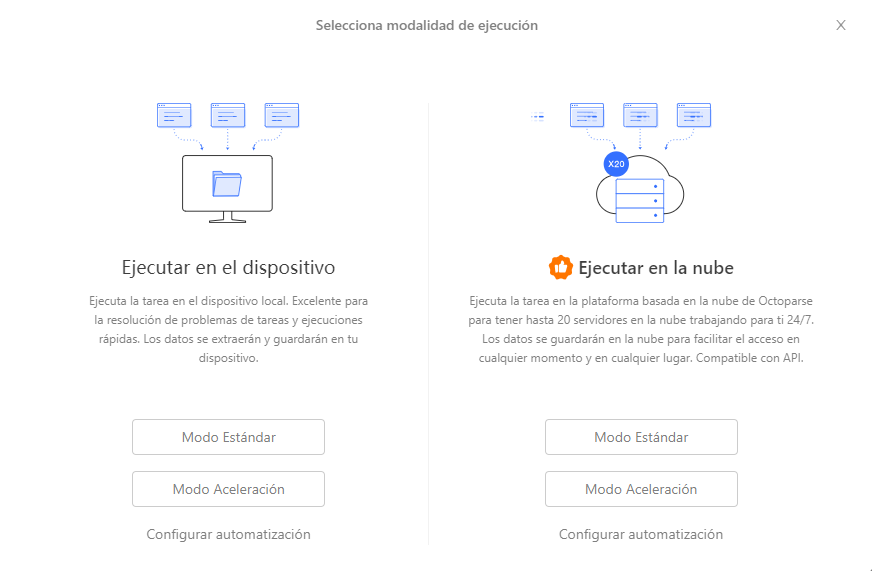
También puedes ejecutar múltiples tareas desde la nube simultáneamente: selecciona las tareas que quieras en la Lista de tareas y haz clic en Iniciar ejecución en la nube para lanzarlas todas juntas.

La programación de tareas en la nube también está disponible. Selecciona la opción Programar ejecución en la nube para una tarea concreta y activa el botón Programar para definir el horario.
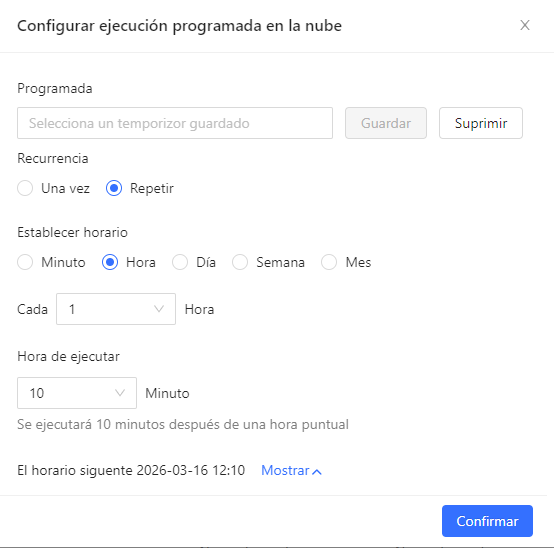
Para más detalles sobre la configuración del scraping en la nube con Octoparse, consulta el Tutorial de extracción de datos en la nube.
Conclusión
El scraping web en la nube es la solución definitiva para simplificar tu proceso de extracción de datos. Comparado con la solución local, es mucho más eficiente y te ayuda a superar los problemas más comunes, como los bloqueos de IP y los CAPTCHAs. Prueba ahora el modo de extracción en la nube de Octoparse y lleva tu proyecto de scraping al siguiente nivel.



