El raspado web/ web scraping es el procesamiento de extraer contenido específico de un sitio web sin acceder a una API para obtener el contenido.
Cómo construir un crawler
Para programadores o desarrolladores, el uso de python es la forma más común de construir un web scraper/crawler para extraer contenido web. Por ejemplo, el código en la captura de pantalla a continuación se puede usar para extraer datos de un sitio web público: pokemondb.net.
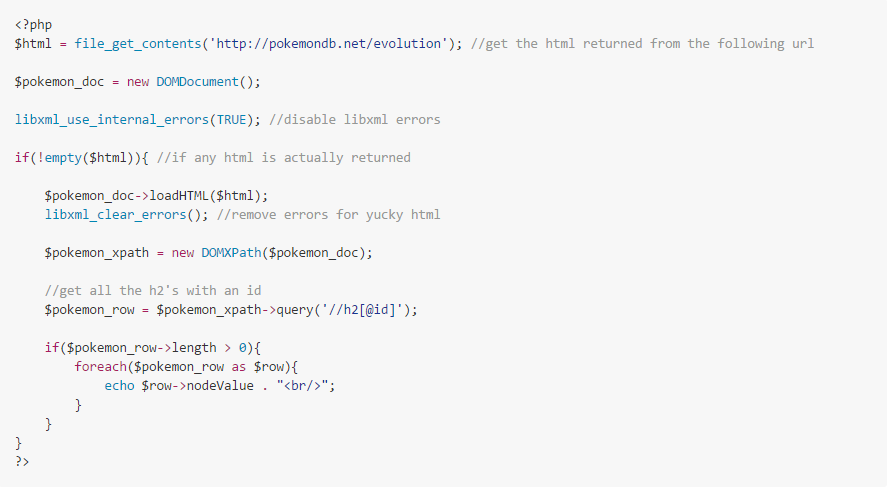
Fuente de imagen
Para la mayoría de las personas que no tienen habilidades de codificación, sería mejor usar algunos extractores de contenido web para obtener contenido específico de las páginas web. A continuación se presentan algunas soluciones con Octoparse:
1. Extraer contenido de la página web dinámica
Las páginas web pueden ser estáticas o dinámicas. A menudo, el contenido web que desea extraer cambiará cada momento. A menudo, el sitio web aplicará la técnica AJAX. Ajax permite que la página web envíe y reciba datos del fondo sin interferir con la visualización de la página web. En este caso, puede marcar la opción AJAX para permitir que Octoparse extraiga contenido de páginas web dinámicas.

Compruebe la configuración del tiempo de AJAX timeout en Octoparse
2. Extraer el contenido oculto de la página web
¿Alguna vez ha querido obtener datos específicos de un sitio web pero el contenido aparecería después de activar un enlace o pasar el puntero del mouse? Por ejemplo, cierta información de contacto en craigslist.org aparecerá después de hacer clic en el botón Reply.
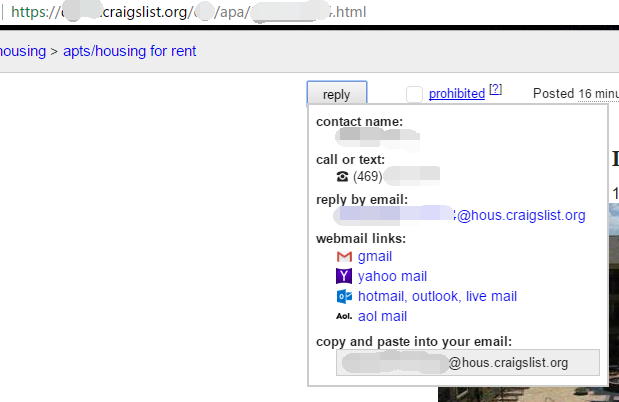
De hecho, dicho contenido oculto se puede encontrar en el código fuente HTML de esta página web. Octoparse puede extraer el texto entre el código fuente. Es fácil usar el comando “Click Item” o el comando “Cursor sobre” debajo del panel “Action Tip” para lograr la acción de extracción.

3. Extraer contenido de la página web con desplazamiento infinito
También puede notar que algunos mensajes solo se cargan una vez que se desplaza hacia la parte inferior de la página web, como Twitter. Esto se debe a que los sitios web aplican desplazamiento infinito. El desplazamiento infinito generalmente acompaña a AJAX o JavaScript para que las solicitudes sucedan cuando llegue al final de la página web. En este caso, puede establecer el tiempo de espera de AJAX, seleccionar el método de desplazamiento y los tiempos de desplazamiento para personalizar cómo desea que el robot extraiga el contenido.

Marque la opción “Scroll Down” en Octoparse para extraer contenido.
4. Extraer hipervínculos de la página web
Un websites normal contendrá al menos un hipervínculo y si desea extraer todos los enlaces de una página web, puede usar Octoparse para ayudarlo a extraer todas las URL de todos websites.
5. Extraer texto de la página web
Si desea extraer el lugar del contenido entre etiquetas HTML, como la etiqueta <DIV> o la etiqueta <SPAN>. Octoparse le permite extraer todo el texto entre el código fuente.
6. Extraer URL de imágenes de la página web
Octoparse no pudo descargar la imagen pero puede descargar la URL de la imagen.

Conclusión
Octoparse puede extraer todo lo que se muestra en la página web y exportarlo a formatos estructurados como Excel, CSV, HTML, TXT y otras bases de datos. Sin embargo, Octoparse ahora no puede descargar imágenes, videos, GIF y lienzos. Esperamos que en el futuro cercano, estas funciones se agreguen a la versión actualizada. Haga clic AQUÍ para descargar Octoparse y aprender más de ricos tutoriales.



