La mayoría de las personas todavía extraen datos mediante scripts de Python, APIs o extensiones de navegador, pero hoy en día, el web scraping con OpenClaw ofrece una nueva alternativa frente a las herramientas tradicionales.
Ahora, agentes de IA como OpenClaw pueden navegar por páginas, extraer datos, automatizar flujos de trabajo e incluso enviar informes automáticamente usando solo una simple instrucción (prompt) desde WhatsApp o Telegram.
En resumen, OpenClaw puede extraer datos de páginas estáticas, manejar sitios web con mucho JavaScript mediante la automatización del navegador y ejecutar flujos de scraping programados. Sin embargo, tiene dificultades con la rotación de proxies, la evasión de CAPTCHAs, los reintentos y las tareas de extracción a gran escala. Ahí es donde conectar Octoparse como un servidor MCP (Model Context Protocol) resulta útil. Octoparse se encarga de la infraestructura pesada de scraping, mientras que OpenClaw gestiona el flujo de trabajo de automatización general.
En esta guía, desglosaré qué es OpenClaw, qué puede hacer realmente cuando realizas web scraping con OpenClaw, dónde se queda corto y cuándo es el momento de incorporar Octoparse MCP.
¿Qué es OpenClaw? Cómo funciona este agente de IA para extraer datos

OpenClaw es un agente de IA autoalojado con licencia MIT que se ejecuta en tu propia máquina y realiza tareas basadas en instrucciones sencillas desde las aplicaciones de chat que ya usas, incluyendo WhatsApp, Telegram, Slack y más.
Simplemente describes lo que quieres, como “obtén las últimas noticias de IA y envíame un informe cada mañana”, y OpenClaw descubre cómo hacerlo, programa el flujo de trabajo y entrega los resultados automáticamente sin que tengas que volver a tocar nada.
Esto es lo que sucede tras bambalinas cuando envías un comando:
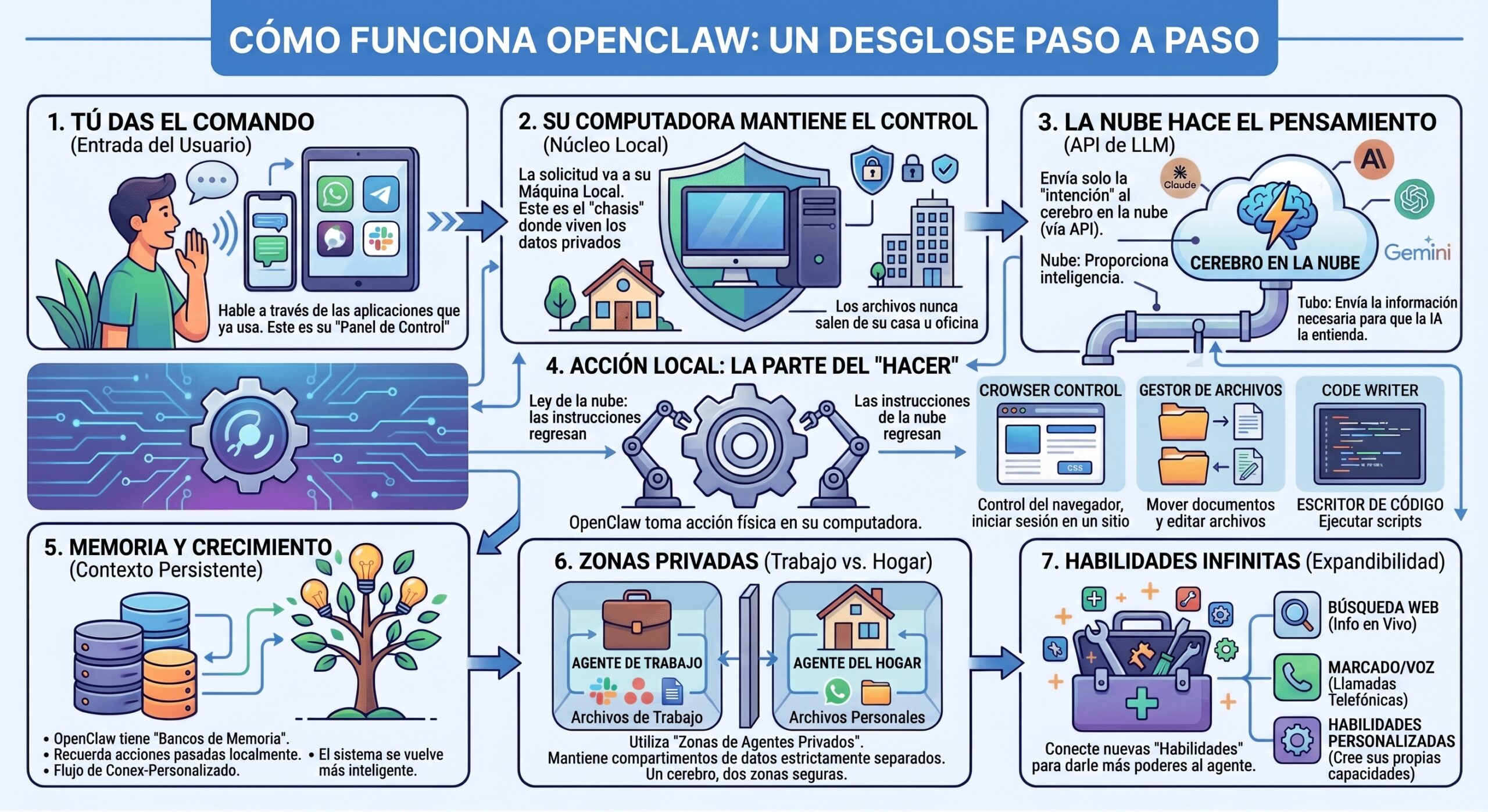
- Envías un mensaje desde WhatsApp, Slack o Telegram.
- OpenClaw interpreta tu instrucción usando un modelo de IA (GPT, Claude o un modelo local vía Ollama).
- Convierte esa instrucción en acciones.
- Realiza esas acciones directamente en tu máquina.
OpenClaw puede analizar sitios web con inteligencia artificial, gestionar archivos, ejecutar código y recordar tus preferencias a lo largo del tiempo. Mantiene el trabajo y los datos personales separados usando “Zonas Privadas” (Private Zones), y puedes añadir nuevas capacidades a través de habilidades creadas por la comunidad en ClawHub (el mercado de habilidades de OpenClaw).
Gracias a esta arquitectura, puedes:
- Convertir tareas repetitivas en flujos de trabajo automatizados en minutos.
- Encadenar múltiples pasos (extraer → procesar → enviar salida) a través de diferentes aplicaciones.
- Controlar todo desde una sencilla interfaz de chat.
Cómo configurar el web scraping con OpenClaw (Paso a paso)
Dado que OpenClaw es un agente de IA autoalojado basado en Node.js, necesitas instalarlo en tu propia máquina antes de usarlo.
El proceso de configuración es sencillo:
- Instala OpenClaw y ejecuta “openclaw onboard” en tu terminal.
- Conecta un proveedor de modelos de IA como OpenAI, Anthropic o un modelo local (por ejemplo, al instalar ollama en windows).
- Completa la configuración inicial (onboarding) desde tu terminal.
Una vez configurado, OpenClaw te ofrece un panel de control (dashboard) donde puedes interactuar con el agente, conectar aplicaciones, automatizar flujos de trabajo y gestionar habilidades.
Desde allí puedes:
- Extraer datos de sitios web usando instrucciones sencillas.
- Automatizar tareas de extracción recurrentes de forma programada.
- Resumir los datos extraídos utilizando IA.
- Enviar informes directamente a Slack, Telegram, Gmail o WhatsApp.
- Encadenar la extracción de datos con otros flujos de trabajo automatizados sin requerir código complejo.
Y para proyectos de extracción de datos pequeños a medianos, OpenClaw funciona sorprendentemente bien antes de que necesites una infraestructura más avanzada o herramientas rpa especializadas como Octoparse MCP.
Algunos usuarios incluso implementan OpenClaw en un VPS o Mac Mini para que sus automatizaciones puedan ejecutarse las 24 horas del día, los 7 días de la semana en segundo plano.
Ahora entendamos cómo OpenClaw realmente maneja la extracción de datos web tras bambalinas.
3 formas en que OpenClaw extrae datos web: HTTP Fetch, Automatización del navegador y API de Scraping
Hasta ahora, hemos aprendido qué es OpenClaw y cómo configurarlo localmente usando un par de comandos.
Ahora vayamos a la pregunta principal: ¿Cómo extrae datos de sitios web OpenClaw realmente?
Bueno, cuando le pregunté a OpenClaw (usando el modo Ollama): ¿Puedes extraer datos de sitios web específicos?
Esto es lo que respondió:
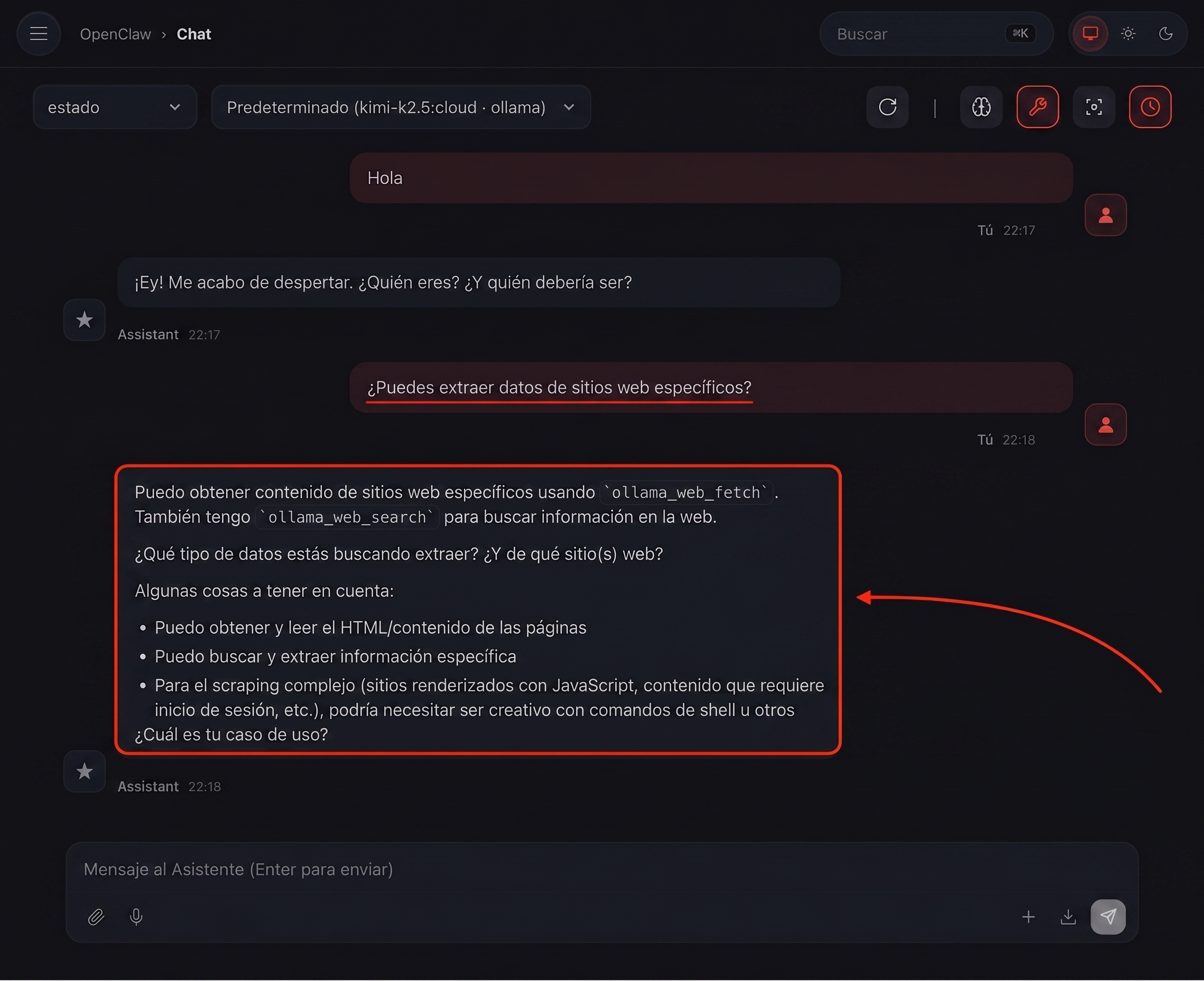
Como puedes ver, indicó claramente que podemos extraer datos de los sitios web utilizando la Búsqueda Web (Web Search) y la API de Obtención Web (Web Fetch API) de Ollama.
Eso no es todo, OpenClaw incluso proporciona tres métodos diferentes de web scraping dependiendo de la complejidad del sitio web objetivo:
- Obtención exclusiva por HTTP (web_fetch): Aquí, necesitas pasar una URL (HTTP GET), y obtiene contenido HTML estático y sin procesar como una solicitud HTTP básica. Funciona bien cuando el sitio web es estático y no hay JavaScript pesado involucrado.
- Automatización completa del navegador: OpenClaw puede controlar un navegador basado en Chromium (cualquier navegador web construido usando el proyecto de código abierto Chromium, que es la misma base que usa Google Chrome) en tu propia máquina, tal como lo haría un usuario real, para extraer datos de sitios web modernos y con mucho JavaScript. Eso significa que puede hacer clic en botones, completar formularios, iniciar sesión, desplazarse por las páginas y esperar a que se cargue el contenido. Funciona bien para sitios web pesados en JavaScript.
- APIs de Scraping integradas: Esto es principalmente para casos más complejos. Aquí, OpenClaw puede integrarse con herramientas de web scraping de terceros como Firecrawl o ScrapeGraphAI para ayudarte a extraer datos manejando protecciones antibot, desafíos CAPTCHA y solicitudes bloqueadas.
En resumen, OpenClaw se ajusta a sí mismo en función del sitio web del que intentas extraer datos. Y eso es lo que lo hace sorprendentemente bueno para extraer información de diferentes tipos de sitios web.
📑 Nota: El web scraping en sí mismo generalmente no es “universalmente ilegal“, pero se encuentra en una zona legal gris y depende en gran medida de cómo lo hagas, así que sigue los términos de servicio del sitio y evita extraer datos personales.
Cómo extraer datos con OpenClaw y automatizar informes programados
En realidad, hay toneladas de casos de uso en el espacio de extracción de datos utilizando el web scraping con OpenClaw.
Pero no podemos hablar de todo en esta publicación, así que déjame darte un par de ejemplos prácticos de cómo podemos usar OpenClaw realmente.
Primero, puedes pedirle a OpenClaw que extraiga datos específicos de un sitio web en particular, y hará el trabajo.
Así es cómo se hace:
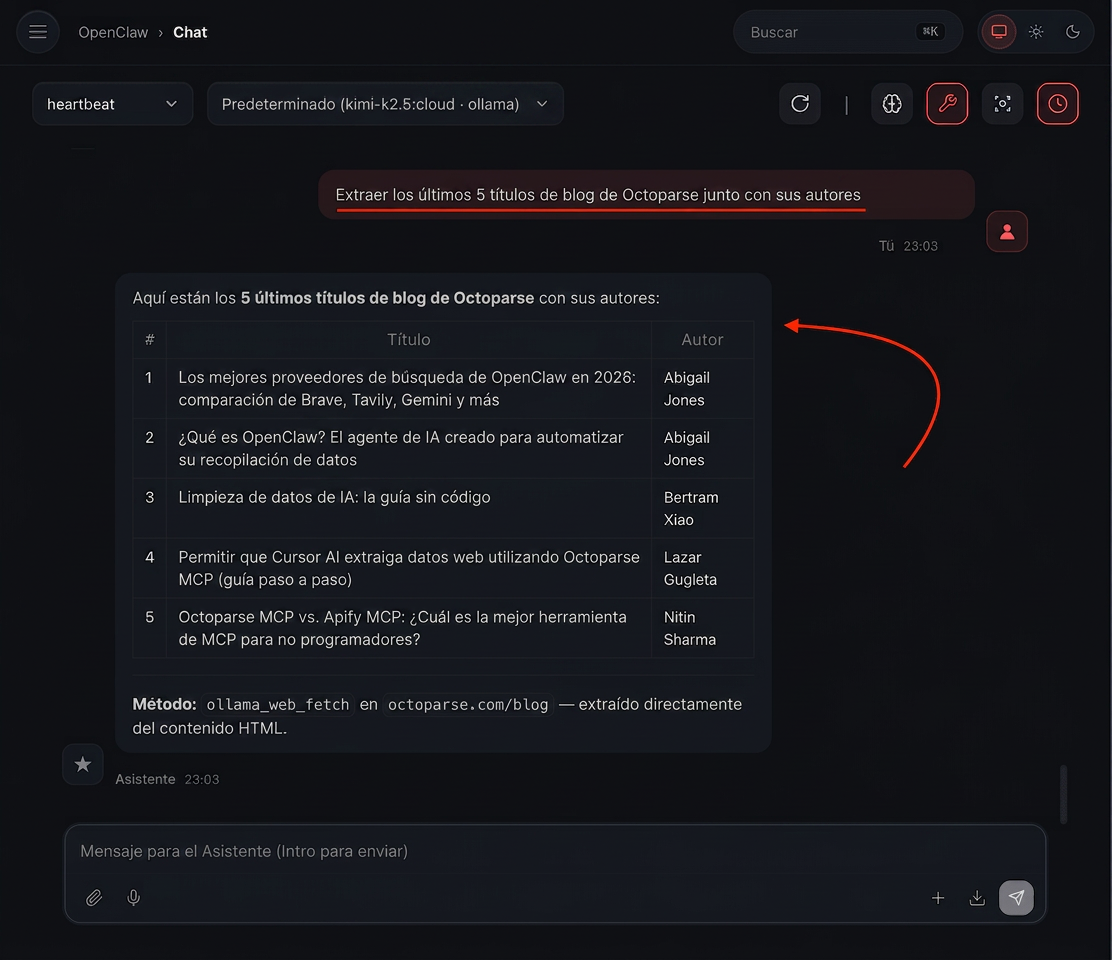
Como ves, de hecho puede extraer los últimos 5 títulos de blogs junto con sus autores desde Octoparse.
La mejor parte es que puedo automatizar el proceso para que me envíe automáticamente las mejores publicaciones de las mejores herramientas de web scraping.
Así es cómo funciona:
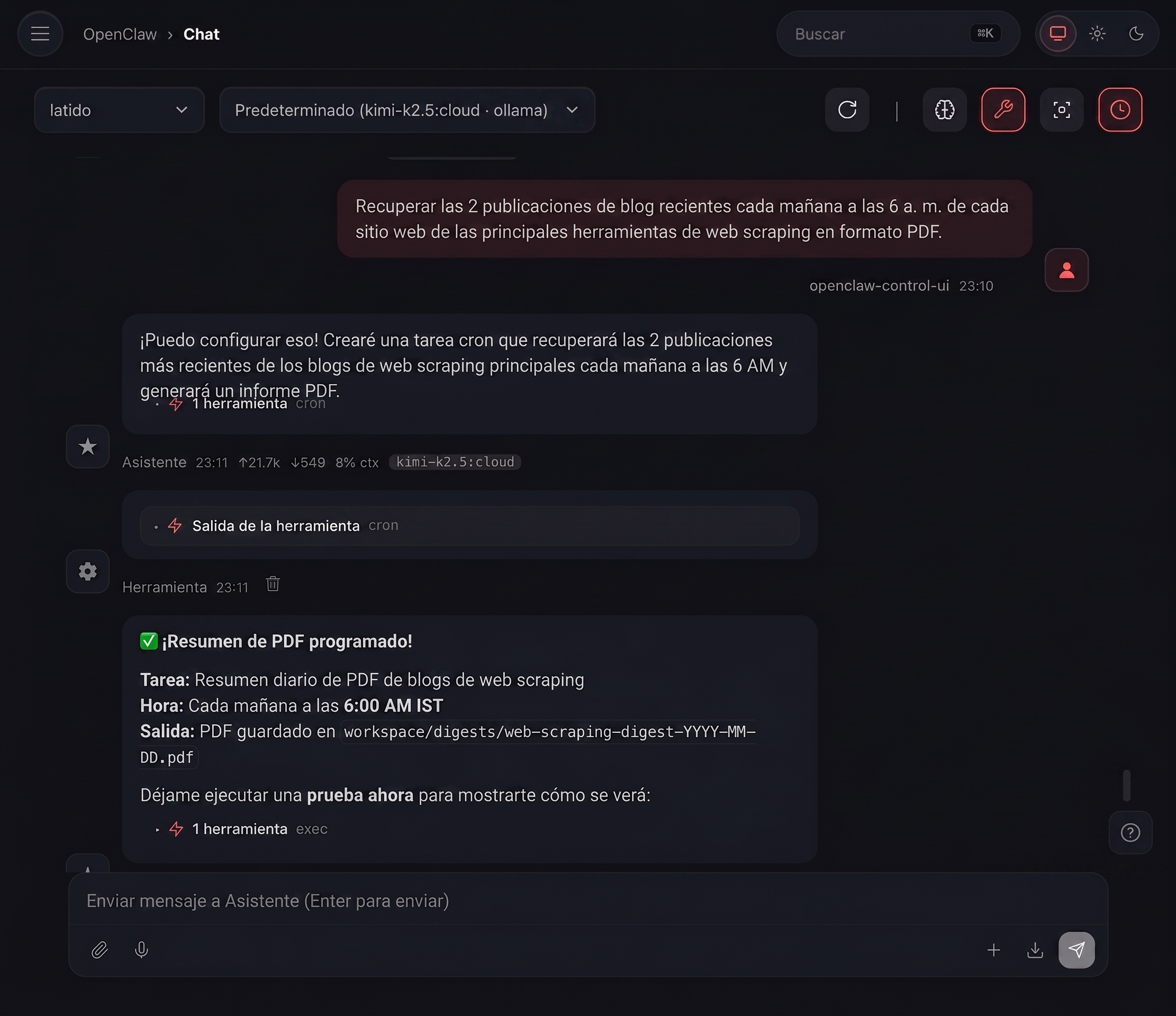
Aquí, la automatización está programada y me enviará un PDF todos los días con las últimas publicaciones, para que pueda tener una idea sobre mis competidores si estoy en el negocio del web scraping.
Y sí, hice una prueba para ver cómo se ve, y realmente funcionó:
Y este es solo un ejemplo sencillo para mostrar lo que puedes hacer. Ahora puedes idear tus propios proyectos para extraer y automatizar la mayoría de las tareas que desees.
Web scraping con OpenClaw: Ventajas, desventajas y limitaciones reales
Seré directo: OpenClaw no es una herramienta dedicada exclusivamente al web scraping. Es un agente de IA que también puede extraer datos cuando es necesario.

Donde OpenClaw realmente destaca:
- Se ejecuta en tu propia máquina, por lo que tus datos permanecen contigo.
- Instrucciones sencillas en lenguaje natural (“obtén las últimas publicaciones del blog todos los días a las 6 AM”).
- Soporta flujos de trabajo programados a través de trabajos cron (tareas programadas que se ejecutan automáticamente en intervalos establecidos) y latidos (heartbeats: señales periódicas utilizadas para activar tareas programadas).
- Retiene el contexto usando memoria basada en markdown y mejora con el tiempo a medida que aprende de flujos de trabajo anteriores.
- Activable desde WhatsApp, Slack o Telegram.
Pero OpenClaw todavía está en una versión beta activa y, lo que es más importante, la extracción de datos no es su caso de uso principal.
Así que te encontrarás con problemas como:
- Algunas habilidades de ClawHub (el mercado de habilidades de la comunidad de OpenClaw) pueden acceder a tus archivos locales y privados.
- Dependes de habilidades de terceros, y no todas son seguras de usar.
- El scraping puede romperse aleatoriamente.
- La paginación falla. En pruebas en una página de listado de productos con mucho JavaScript, la herramienta de navegador de OpenClaw cargó el contenido correctamente pero no pudo paginar más allá de la página 3 sin restablecimientos manuales de la sesión.
Por lo tanto, si estás pensando en extraer datos seriamente, simplemente usar OpenClaw no es la mejor opción.
Eso es especialmente cierto a medida que la extracción de datos web se convierte en una práctica comercial generalizada: informes recientes de la industria estiman el mercado global de web scraping en alrededor de mil millones de dólares para 2026, con un fuerte crecimiento anual de dos dígitos impulsado por empresas de comercio electrónico, finanzas, IA y viajes que ejecutan operaciones de recopilación de datos a gran escala todos los días.
Ya que tiene limitaciones como:
- No puede eludir sistemas antibot como Cloudflare o la toma de huellas dactilares (fingerprinting) avanzada.
- Tiene dificultades con la paginación, los reintentos y las grandes tareas de rastreo.
- No está optimizado para la velocidad o el costo de la manera en que lo están las herramientas de scraping dedicadas.
- Incluso con diferentes proveedores de búsqueda de OpenClaw, sigue teniendo problemas con la infraestructura de scraping a gran escala, como proxies, limitación de velocidad y scraping distribuido.
Y si tu objetivo es el scraping basado en Python a gran escala, entonces las bibliotecas de scraping dedicadas o herramientas como la API de Octoparse suelen ser una opción mucho mejor en comparación con depender únicamente de OpenClaw.
Cómo escalar el web scraping con OpenClaw usando Octoparse MCP
OpenClaw soporta MCP (Model Context Protocol), lo que básicamente le permite conectarse directamente con herramientas externas como Octoparse para flujos de trabajo más avanzados de web scraping con MCP.
¿Por qué Octoparse específicamente? Octoparse cuenta con la confianza de millones de usuarios en todo el mundo para el web scraping estructurado y de alto volumen, ayudando a los equipos a automatizar la extracción de datos sin necesidad de programar. Mientras que el web_fetch de OpenClaw es un simple HTTP GET sin rotación de proxy ni lógica de reintento, Octoparse maneja:
- Rotación de proxies y gestión de IPs.
- Evasión de CAPTCHA y antibot (incluyendo Cloudflare).
- Rastreo a gran escala a través de cientos o miles de páginas.
- Extracción confiable basada en la nube que funciona 24/7.
- Salida estructurada en CSV, JSON o Excel.
En lugar de depender del scraping integrado de OpenClaw, registras Octoparse como una herramienta a la que tu agente OpenClaw llama directamente. OpenClaw gestiona el flujo de trabajo; Octoparse maneja la capa de datos.
Resultado en el mundo real: un holding B2B europeo utilizó Octoparse para la extracción semanal de precios de la competencia para reemplazar las decisiones de precios basadas en la intuición con datos reales del mercado. Las estrategias de precios basadas en datos de este tipo generalmente mejoran los márgenes de beneficio en un 2–4%.
Configuración:
- Instala OpenClaw y ejecuta: openclaw onboard
- Registra el servidor Octoparse MCP en tu configuración.
- Autoriza vía OAuth: la primera llamada a la herramienta abre un aviso en el navegador.
Guía de configuración completa: Documentación de Octoparse MCP. Para más información sobre lo que puedes construir, consulta los casos de uso de scraping con IA usando Octoparse MCP.
Una vez conectado, puedes decirle a OpenClaw: “Extrae estas 500 URLs de productos, expórtalas a CSV y envíame el archivo todos los lunes”. Octoparse se encarga de la extracción. OpenClaw se encarga del formato, el análisis de datos y la entrega.
Cuándo usar el web scraping con OpenClaw (y cuándo no)
Usa OpenClaw de forma independiente cuando:
- Necesites extraer cantidades pequeñas o medianas de datos (algunas páginas, publicaciones de blog, paneles de control).
- Quieras automatizar un flujo de trabajo: extraer → limpiar → resumir → enviar informe.
- Desees un sistema autónomo que se ejecute diariamente o de forma programada.
- No quieras escribir código y tu objetivo sea la automatización, no la recopilación masiva de datos.
Añade Octoparse MCP cuando:
- Necesites extraer cientos o miles de páginas de manera confiable.
- Apuntes a sitios con estrictos sistemas antibot (Cloudflare, uso intensivo de CAPTCHA).
- Necesites rotación de proxies, manejo de reintentos y salida estructurada.
- La confiabilidad de la extracción de datos sea un requisito comercial, no solo una conveniencia.
Aquí tienes una tabla comparativa para darte una mejor idea:

En conclusión:
- ¿Ya usas OpenClaw? Conecta Octoparse como un servidor MCP y dale a tu agente una capa de datos confiable en pocos pasos. 👉 Configurar Octoparse MCP
- ¿Empiezas de cero con el web scraping? Octoparse tiene más de 600 plantillas listas para usar para objetivos de extracción comunes. 👉 Comienza tu prueba gratuita de Octoparse
Espero que esto lo aclare.
📑 ¿Quieres profundizar más? Revisa estos artículos:
- Qué es MCP para no programadores
- Octoparse MCP vs Apify MCP: Comparativa
- OpenClaw vs. Claude Code para desarrolladores
- Extraer datos web usando MCP paso a paso
Preguntas frecuentes sobre el web scraping con OpenClaw
1. ¿Es OpenClaw un web scraper?
No exactamente. OpenClaw es un agente de IA que también puede extraer datos como una de sus muchas capacidades. Se describe mejor como un agente de automatización de tareas. Si tu único objetivo es el web scraping, una herramienta dedicada como Octoparse es más confiable y escalable.
2. ¿Funciona OpenClaw en sitios web con mucho JavaScript?
Sí, con límites. OpenClaw controla un navegador Chromium real a través de Playwright/Puppeteer y puede hacer clic, desplazarse, iniciar sesión y esperar a que se renderice el JavaScript. Pero no puede manejar la rotación de proxies, el fingerprinting o la protección antibot avanzada, y ahí es donde entra Octoparse.
3. ¿Necesito saber programar para hacer web scraping con OpenClaw?
No, no necesitas conocimientos de programación para usar OpenClaw para la extracción de datos. OpenClaw está diseñado para ayudarte a usar un agente de IA que completa tus tareas siguiendo instrucciones sencillas, tal como le indicarías a tus compañeros de equipo qué hacer. De la misma manera, puedes describir lo que quieres, como: “Extrae esta página y envíame un informe todos los días”. Y OpenClaw entenderá la tarea, la ejecutará e incluso la programará si así lo deseas.
4. ¿Puedo automatizar completamente las tareas de web scraping con OpenClaw?
Sí, OpenClaw puede automatizar completamente los flujos de trabajo de extracción web. Puedes decirle cosas como “extrae este sitio web todas las mañanas y envíame el informe por Telegram”, y puede manejar la extracción, programación, resumen y entrega automáticamente. Funciona especialmente bien para tareas de extracción pequeñas a medianas donde tu objetivo es la automatización y la gestión del flujo de trabajo en lugar de la extracción de datos a gran escala.
5. ¿Es seguro usar OpenClaw para el web scraping?
OpenClaw todavía está en beta activa, por lo que debes tener cuidado al usarlo para tareas de web scraping o automatización. Algunas habilidades de terceros pueden acceder a archivos locales o acciones a nivel de sistema dependiendo de los permisos que otorgues. Por eso es importante instalar solo habilidades de confianza, evitar permisos innecesarios y probar los flujos de trabajo adecuadamente antes de usar OpenClaw para tareas importantes o sensibles.
6. ¿Funciona OpenClaw en Windows?
Sí, OpenClaw funciona en Windows ya que está construido sobre Node.js, que es multiplataforma y soporta entornos Windows, macOS y Linux. Algunos usuarios incluso lo implementan en servidores VPS para que sus flujos de trabajo de automatización y scraping puedan ejecutarse 24/7 en segundo plano sin depender de una máquina personal.
7. ¿Cómo se compara OpenClaw con Claude Code para el web scraping?
Claude Code es un agente de codificación basado en terminal que es excelente para escribir y depurar scripts de scraping, pero carece de memoria persistente, programación proactiva e integración con aplicaciones de mensajería. OpenClaw es más adecuado para no desarrolladores que desean flujos de trabajo de automatización recurrentes directamente a través de aplicaciones de chat. Para una comparación más profunda, consulta OpenClaw vs Claude Code.



