En el ámbito académico, nada parece más útil para que los estudiantes, investigadores y profesores obtengan suficiente información para la investigación que Google Scholar. Varias características hacen que este motor de búsqueda sea más práctico y realmente salvavidas, como su literatura académica, citas hacia adelante y Bib TeX auto-generado.
A veces, cuando necesitas una gran cantidad de datos de Google Scholar, no puedes hacerlo debido a algunas de sus restricciones. Por lo tanto, puedes utilizar el web scraping para extraer el contenido de Google Scholar y buscar una gran cantidad de artículos académicos y diversos recursos académicos.
Si estás ansioso por conseguirlos, sigue esta guía. Te allanará el camino para raspar los datos de Google Scholar con una metodología más conveniente.
¿Es legal scrapear Google Scholar?
Google Scholar se puede raspar fácilmente. Aunque parece un poco complicado, se puede hacer si se consigue un raspador de Google Scholar fiable para extraer la literatura académica sin problemas.
Sin embargo, debes prestar atención a las leyes locales sobre el scraping de datos. Y los derechos de autor o la privacidad del uso de estos datos.
¿Qué tipos de datos extraemos por Google Scholar?
Puedes obtener una gran cantidad de datos de Google Scholar, incluidos artículos de investigación, y crear automáticamente una base de datos de citas anteriores y posteriores, así como diversos recursos académicos, como ResearchGate, sitios de redes sociales académicas, etc.
¿Existe una API para Google Scholar?
Google Scholar no proporciona acceso oficial a la API para el web scraping. El robot.txt de este motor de búsqueda prohíbe a los web scrapers el raspado de la mayoría de las páginas. Se supone que se accede a través de sus bots o de algunas API de terceros y no está permitido realizar esta acción. Sin embargo, obtendrás un CAPTCHA para borrar si solicitas llegar a cierta información.
https://www.octoparse.es/template/google-search-scraper
2 Métodos de recopilar datos de Google Scholar
#1 Manera sin codificación: Herramienta de web scraping sin código
Para raspar los datos de Google Scholar, hay una inmensa necesidad de aprender lenguajes de codificación difíciles. Sin embargo, puede utilizar Octoparse, que puede ayudarle a raspar los datos de Google Scholar en Excel sin codificación. Octoparse puede raspar la página web automáticamente, y puedes aplicar funciones avanzadas como paginación, bucle, tiempo de espera AJAX, etc.
Octoparse también proporciona una plantilla preestablecida para raspar la información de los artículos de Google Scholar que se puede utilizar directamente para extraer todos los datos. Lo que hay que hacer es introducir las palabras clave y esperar los resultados. Encuéntrela en el panel Plantilla de Octoparse, y podrá previsualizar el ejemplo de datos.
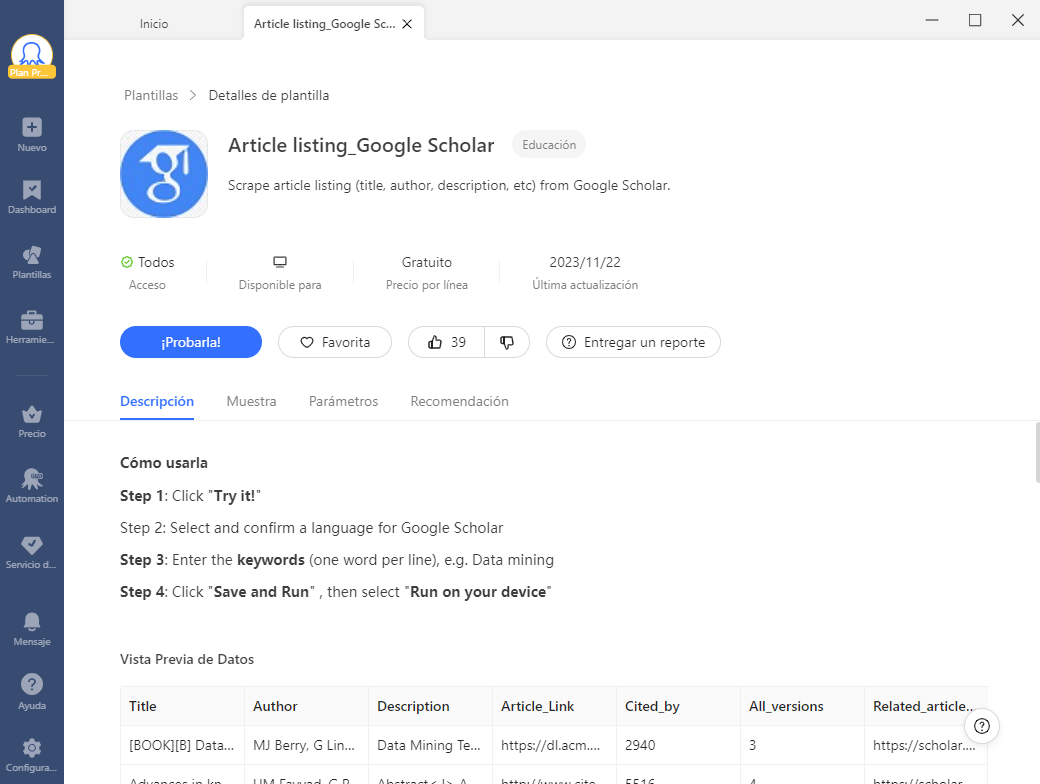
Pasos para extraer recursos académicos de Google Scholar
Descargue Octoparse, instálelo en su dispositivo y regístrese gratuitamente. A continuación, siga los sencillos pasos que se indican a continuación o lea la guía de usuario detallada sobre el scraping de datos de Google Scholar. También puede ver el vídeo aquí para ayudarle a entender más.
Paso 1: Introduce el enlace de la página que necesitas extraer de Google Scholar
En primer lugar, vaya a la página de destino de Google Scholar, copie la URL e introdúzcala en la barra de búsqueda de Octoparse en la pantalla de inicio. A continuación, la URL de destino se raspará automáticamente.
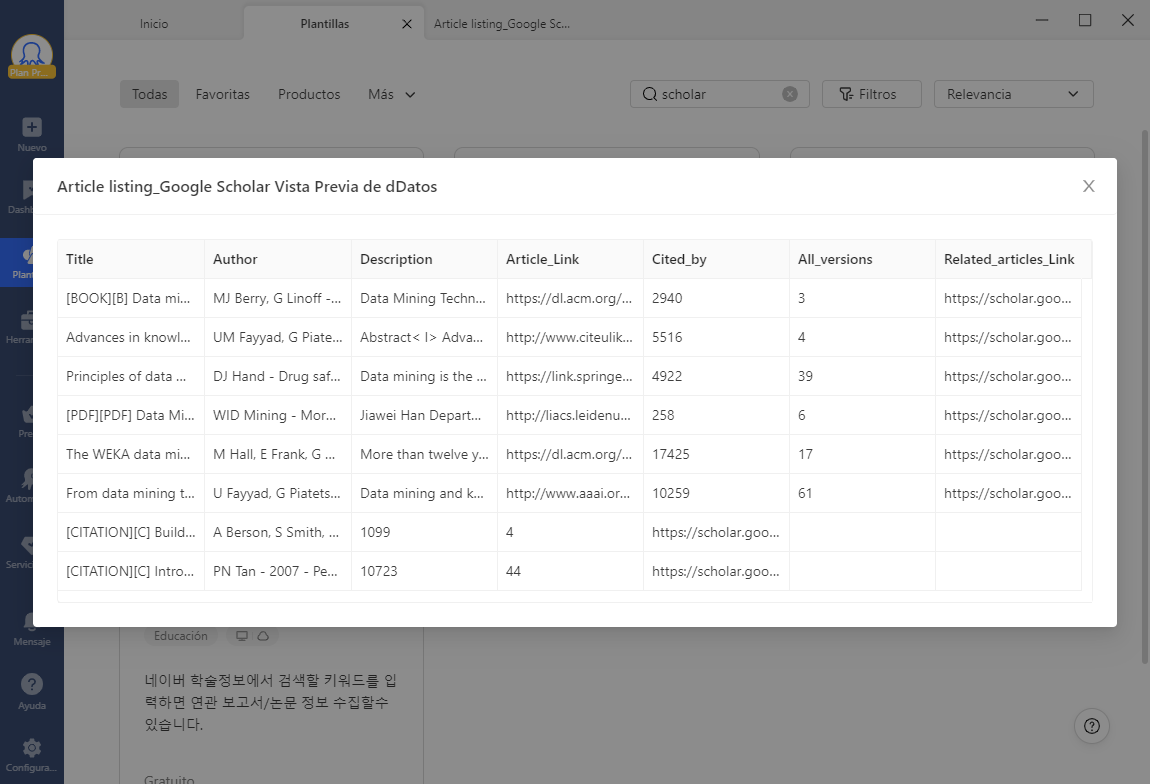
Paso 2: Personalizar el workflow de trabajo para obtener más datos
Tras el proceso de autodetección, se generará un workflow. Puede realizar cambios con el panel de consejos para obtener más datos. La sección de vista previa mostrará lo que será raspado.
Paso 3: Extraer datos de la página de resultados de búsqueda de Google Scholar
Haz clic en el botón Ejecutar para iniciar el raspado y espera unos instantes. Por último, puedes descargar los datos extraídos en un archivo Excel/CSV o guardarlos directamente en tu base de datos.
También puedes extraer los resultados de búsqueda de Google o Bing directamente si quieres encontrar más información que no puedes encontrar en Google Scholar.
#2 Manera con codificación: Scrapear Google Scholar Usando Python
En el escenario actual, uno tiene que aprender lenguajes de programación para raspar los datos de Google Scholar. Aunque, un método fácil de usar ha sido discutido anteriormente. Sin embargo, también hay que aprender a extraer datos de Google Scholar con Python. Por lo tanto, aprenderlo en unos sencillos pasos.
Paso 1: En primer lugar, prepara el entorno virtual e instala las librerías para selectores CSS para extraer datos de las etiquetas y atributos relevantes.
Paso 2: Añade las extensiones SelectorGadget para extraer datos de los selectores CSS. A continuación, utilice los códigos Python específicos para extraer los resultados de búsqueda orgánica de Google Scholar.
Paso 3: Utilice SerpAPI para esto, ya que puede extraer título, fragmento, información de publicación, enlace a un artículo, enlace a artículos relacionados, enlace a diferentes versiones de artículos y enlaces en la parte inferior; BibTeX, EndNote, RefMan, RefWorks, etc.
Paso 4: Aparte de esto, SerpAPI también puede raspar información de Google Scholar Profiles, incluyendo nombre del autor, enlace, afiliación(es), correo electrónico, intereses, citado por, y acceso público.
Paso 5: A continuación, otro dato importante son los resultados de citas de Google Scholar. Para ello, se crea una lista temporal para almacenar los datos de las citas. Utilice estas líneas de comando para iterar sobre los resultados orgánicos y pasar el id de los resultados a la consulta de búsqueda:
Paso 6: A continuación, tiene que pasar una lista de los datos devueltos de los resultados orgánicos y citar a Data Framedata argumento y dejar que se guarde en CSV.
Paso 7: Algunos comandos particulares que puede utilizar según su deseo, ya sea eliminar o añadir cualquier columna de los datos seleccionados.
Así, la codificación Python raspará los datos de Google Scholar.
Pensamientos Finales
Si tu vida académica está en marcha, estarás utilizando Google Scholar para obtener los últimos y antiguos artículos académicos y otros recursos académicos, incluyendo el reenvío de citas. Google Scholar web scraping puede añadir más valor a su viaje académico. Sólo tiene que utilizar Octoparse para ayudarle a extraer una gran cantidad de datos de páginas web a sus propios dispositivos locales. No tiene necesidad de aprender extenuantes lenguajes de programación.
Para obtener más información sobre los sitios de literatura académica rastreables de Octoparse, pulse aquí: 30 Herramientas y Recursos para Investigación Académica




