El web scraping es una técnica útil para recopilar y extraer datos de sitios web. En este blog, te mostraremos cómo hacer web scraping de Twitter utilizando Python y una herramienta de web scraping y concluiremos al final sus pros y contras. Ahora empezamos.
¿Qué web scraping?
El web scraping es la acción de extraer contenidos y datos de un sitio web utilizando determinados tipos de software. En cierto modo, es una técnica utilizada en diferentes ámbitos como el marketing digital y la investigación para extraer información valiosa de páginas web.
Hay diferentes formas de intentar conseguir el raspado de datos web, la más sencilla es utilizar herramientas de raspado de datos de pago o gratuitas, como Octoparse, o escribir tu propio código de raspado (complicado y tedioso). El raspado de datos web le permite obtener datos actualizados y relevantes para que pueda mejorar tu estrategia de SEO y tomar decisiones informadas y de apoyo.
Scrapear Twitter con Python
Para descargar datos de Twitter con Python, primero tendremos que solicitar una API de Twitter a través de este enlace. Después de solicitar la API, podríamos obtener 4 líneas de código, que son clave API, clave secreta API, token de acceso y secreto de token de acceso (API key, API secret key, Access token, and Access token secret.
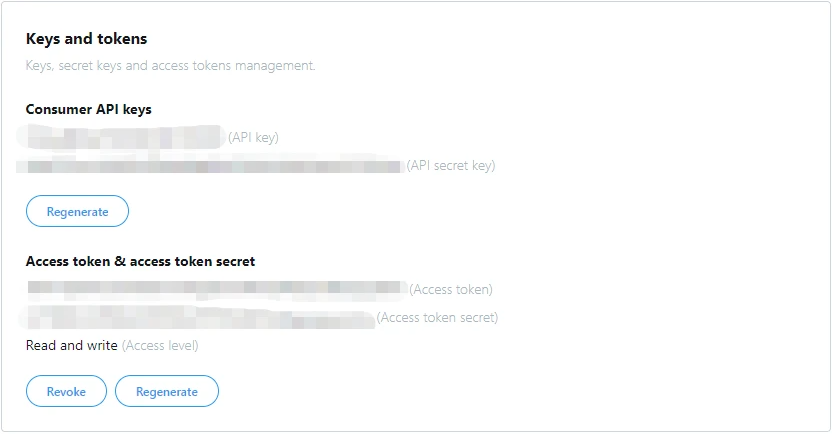
Ahora tenemos la API y podríamos comenzar a construir nuestro rastreador de Twitter. Usaremos dos bibliotecas para construir el rastreador, json y tweepy.
JSON es un paquete integrado que podría aplicarse para manipular datos JSON. Tweepy es un paquete de código abierto para acceder a la API de Twitter. Contiene muchas funciones y clases útiles para manejar diversos detalles de implementación.

Este flujo de información podría ayudarnos a ejecutar y extraer los tweets. OAuthHandler podría ayudarnos a enviar nuestras claves y secretos a Twitter. Mientras StreamListener podría ayudarnos a modificar los campos que necesitamos de cada tweet.
Luego, completa las claves y los secretos que aplicaste a través del enlace anterior.

Aquí crearemos una clase heredada de StreamListener para modificar qué tipo de datos necesitamos extraer de Twitter. Podríamos scrape información como tweets, ubicación, nombre de usuario, identificación de usuario, número de seguidores, número de amigos, likes y zona horaria. A parte de la información, como tweets, nombre de usuario, zona horaria, habría palabras en otros idiomas, por lo tanto, deberíamos considerar usar otra codificación de caracteres como UTF-8 en lugar de la codificación de caracteres Unicode predeterminada.
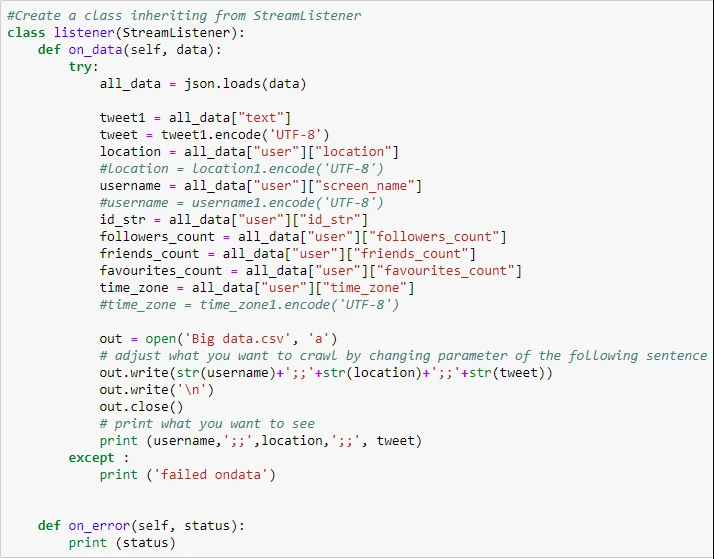
Luego, podríamos enviar nuestra clave y secreto usando OAuthHandler que llamamos desde Tweepy.

Ahora solo necesitamos unos pocos pasos más para ejecutar y extraer la información. Aquí buscaremos todos los tweets relacionados con la palabra clave “Big data” y comenzaremos nuestra extracción con Stream.
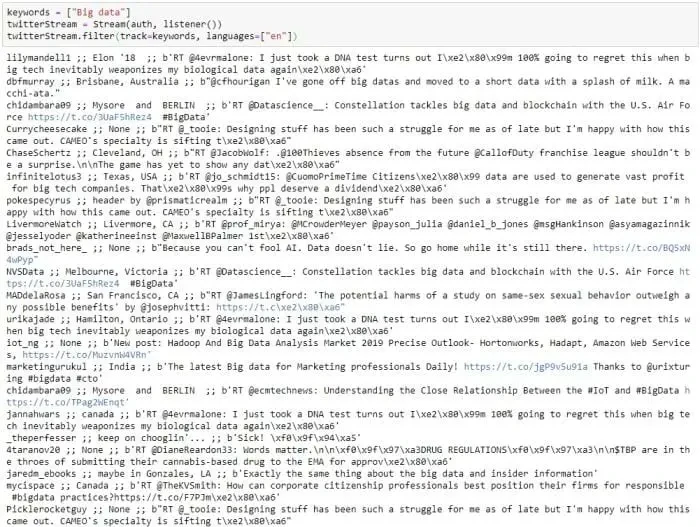
Cada línea de datos es información de un tweet. Los diferentes campos están separados por dos punto y coma “;“. El primer campo es el nombre de usuario, el segundo campo es la ubicación y el último campo es el tweet. Podríamos escribir los datos en una hoja de cálculo y establecer el delimitador como “;;” para separar los campos O podríamos aplicar otras bibliotecas como pandas, numpy y regex para organizar aún más los datos.
Scrapear Tweets con herramienta de web scraping – Octoparse
Octoparse es una herramienta de extracción de datos gratuita que ayuda a los usuarios a obtener informaciones de las web sin codificación. Para facilitarles a los usuarios que no son programadores en sacar las informaciones que quieran, el equipo de Octoparse prediseñó plantillas, incluidas las para descargar datos de Twitter.
Si quieres extraer tweets, números de seguidores, likes e imágenes de Twitter, podrías encontrar las correspondientes en Octoparse. Tras seleccionar la plantilla que más se ajuste a tus requisitos de datos, lo único que se tiene que hacer es introducir las URL o de los sitios web o palabras clave y Octoparse se encargará de scrapear y extraer datos.
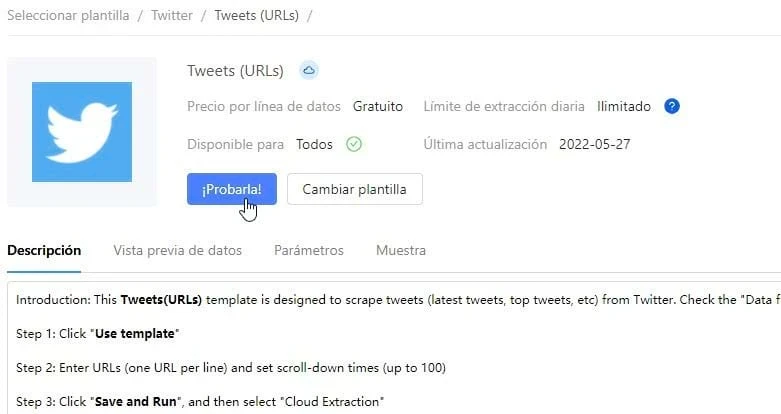
También puedes configurar tu propio crawler de Twitter haciendo solo clics en el web scraper software si necesitas personalizar los datos que se extraerán.
Los pasos detallados podrías ver en Cómo Extraer Datos de Twitter | Descargar a Excel o contactar con el equipo de soporte(support@octoparse.com) para arrancar en el viaje de descargar datos de Twitter.
Aprender más tutoriales de redes sociales scraping:
Pinterest Scraper
Lemon8 Scraper
Caráteristicas Principales de Octoparse
Sin adquisición de código para ahorrar tiempo de aprendizaje
Octoparse ha preparado un completo tutorial guía para novatos, para que pueda empezar fácilmente sin ningún tipo de codificación. Lo que es más, Galería de plantilla, más de 880 plantillas preestablecidas están a su disposición. ¡Comience su prueba eficiente de 14 días ahora!

Capacidad de solución de reCAPTCHA
Te ayuda a resolver rápidamente el mecanismo anti-picking y a mejorar la eficiencia de la recolección.
Soporte técnico profesional multilingüe para ofrecer soluciones de datos eficientes
En la actualidad, Octoparse admite 7 idiomas para la navegación por el sitio web y el servicio de atención al cliente, y 5 idiomas para el cliente (italiano y coreano próximamente) para garantizar una comunicación con usted sin barreras. Personalice la solución de recogida de datos a su medida según sus necesidades.

Bajo precio, mejor experiencia de producto
Octoparse tiene el precio más ventajoso en la industria del software de recopilación de páginas web, a la vez que proporciona características de mayor valor en la industria, métodos de recopilación más flexibles, recopilación de datos más completa.
Python vs Web scrapers
Los pros y los cons de Python y Octoparse
Según la parte anterior, ahora podemos concluir los pros y los contras de la codificación con Python y Octoparse:
1. Costo de aprendizaje
Octoparse tiene un costo de aprendizaje más bajo en comparación con Python. Para crear un rastreador con Python, no solo se debe estar familiarizado con diferentes bibliotecas y técnicas de codificación, sino comprender bien la estructura de las web y reconocer las técnicas de anti-scraping.
Sin embargo, en Octoparse, los desarrolladores ya han considerado todo tipo de situaciones para los usuarios y todo lo que necesita es hacer clics y todos los datos se descargarán.
2. Establecimiento rápido
De la parte anterior, parece que ambos métodos son simples y fáciles de usar. Sin embargo, el proceso que lleva más tiempo no es construir el rastreador. En realidad, es cuando se realiza un análisis inicial en los sitios web antes de comenzar a construir el rastreador. Diferentes sitios web aplican distintos métodos de desarrollo y técnicas anti-scraping. Necesitaremos más tiempo para analizar sitios web si elegimos la codificación para obtener tweets.
Sin embargo, los desarrolladores de Octoparse ya han considerado la mayoría de las situaciones y puedes obtener acceso a datos de Twitter sin analizar las páginas web.
3. Flexibilidad
Python tiene mejor flexibilidad que Octoparse. Podríamos manipular el comportamiento de nuestros rastreadores simplemente cambiando algunos de los códigos, importar algunas bibliotecas potentes o API para acceder a los datos con solo varios códigos e incluso algunas de las técnicas anti-scraping más difíciles, como Captcha or reCaptcha, podrían resolverse ahora con algunos métodos de aprendizaje profundo utilizando Python.
Conclusión
Honestamente, Python y Octoparse tienen sus ventajas. Octoparse es más adecuado para personas sin habilidades de codificación, mientras que Python podría proporcionar una gran flexibilidad para los expertos. Si crees que sería difícil aprender tal codificación de Python, ¡contáctanos! Octoparse podría proporcionar un servicio de datos y ayudarte a extraer datos con solo varios clics.




