¿Qué es servidor proxy?
Un servidor proxy juega el papel de un intermediario entre los internautas y el internet. Transmite por ti tus peticiones al servidor de la web ocultando tu identidad. Puede proteger la privacidad y ayuda a evitar el bloqueo de algunos sitios web cambiando IP de los usuarios.
¿Para que sirve el proxy en el web scraping?
Web Scraping se vuelve cada día más popular en la extracción y recopilación de datos. Esta técnica automática puede ayudarnos a exportar una gran cantidad de datos de la Web a tu dispositivo o a la base de datos. Sin embargo, el problema principal es que los sitios web pueden detectar fácilmente la solicitud de raspar múltiples páginas en tiempo sumamente corto mediante una única dirección IP, por lo que esos sitios web pueden bloquearte.
Para bajar las posibilidades de ser bloqueado, necesitaremos evitar raspar un sitio web con una única dirección IP. Podríamos utilizar servidores proxy que proporcionan varios IP proxy siempre que las solicitudes de página web se enrutan a través del servidor de rastreo.
Entre miles de sitios web que venden proxies, la estabilidad de proxy siempre sería el primer parámetro que consideraremos. Algunos proxies poco confiables operan demasiado rápido, lo que podría causar que se bloqueen. También el costo y la facilidad serán unos de los enfoques más importantes en la decisión de un servidor proxy.
Ver más: ¿Qué es un Proxy y para qué sirve?
Web scrapers populares para evitar el bloqueo de IP
En realidad, podemos adoptar un enfoque más conciso y eficiente mediante ciertas herramientas de extracción de datos con servicios de la rotación de IP, como Octoparse, Import.io. Estas herramientas pueden programar y ejecutar tu tarea en cualquier momento en el lado de la nube con diferentes IP ejecutándose al mismo tiempo. Además, estos scrapers también pueden proporcionarnos una forma rápida de configurar manualmente estos servidores proxy según lo necesites. Aquí hay un tutorial que presenta cómo configurar proxies en Octoparse.
A continuación, te presentaré los raspador populares en el mercado de web scrapers, incluidos Octoparse, Import.io, Webhose.io y Screen Scraper.
1. Octoparse
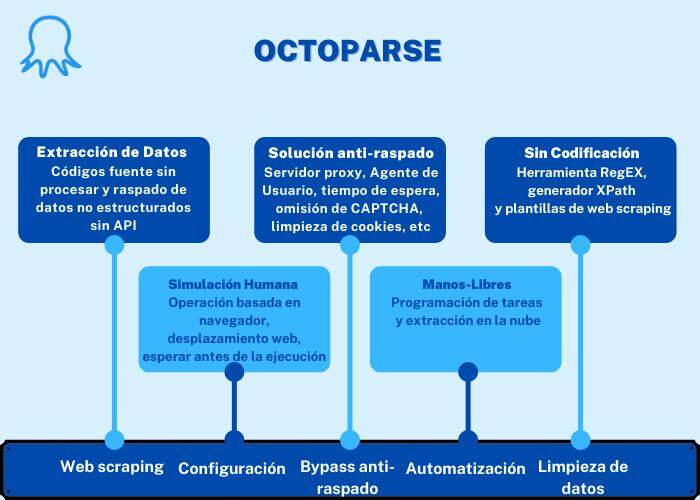
Octoparse es una herramienta de extracción de datos poderosa y gratuita que puede rastrear casi todos los sitios web. Su extracción de datos basada en la nube puede proporcionar ricos servidores proxy de dirección IP rotativos para web scraping, lo que ha disminuido las posibilidades de ser bloqueado y ahorrado mucho tiempo para la configuración manual.
Proporciona tutoriales detallados y equipo de soporte gratuito para ayudar a los usuarios a configurar su propio crawler. Básicamente, en esta herramienta, no es necesario tener habilidades de codificación ya que con solo hacer clics podrías construir un scraper. Además, ha actualizado la función de detección automática de datos en las páginas web y prediseñado más de 300 plantillas para extraer datos de sitios web populares.
Si deseas profundizar y fortalecer tu rastreo y raspado, ha ofrecido servicios sobre las API y los datos extraídos se pueden exportar a Excel, CSV, HTML o a tu base de datos.
2. Import.io

Import.io también es una herramienta de recopilación de datos fácil de usar. Tiene una interfaz de usuario simple y eficaz y una navegación visible. Esta herramienta también requiere menos habilidades de codificación. Import.io posee muchas características poderosas, como el servicio basado en la nube que puede ayudarnos a usar varias IP rotativas para nuestro proyecto de datos y mejorar nuestra capacidad de minería de datos. Sin embargo, Improt.io tiene dificultades para navegar a través de combinaciones de javascript / POST.
3. Webhose.io

Webhose.io es una herramienta de web scraping basada en navegador que utiliza varias técnicas de rastreo de datos para recopilar cantidades de datos de múltiples sitios web. Si bien puede que no se diseñe tan secillo como las herramientas introducidas anteriormente sobre su servicio en la nube, lo que significa que el proceso de raspado relacionado con la rotación de IP o la configuración del proxy puede ser algo complejo, proporciona un plan gratuito y premium según lo necesites.
4. Screen Scraper

Screen Scraper es bastante ordenado y potente. Puede lidiar con ciertas tareas difíciles, incluida la localización precisa, la navegación y la extracción de datos. Así que requiere que tengas habilidades básicas de programación si deseas que funcione al máximo. Implica que configures los ajustes de tarea y establecer los parámetros manualmente en la mayoría de los casos. Es una de sus ventajas que puede personalizar tu proceso de minería, mientras que las desventajas son que requiere un poco de tiempo ya que es complejo.



